 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHyperGLM: HyperGraph for Video Scene Graph Generation and Anticipation
Nov 27, 2024Multimodal LLMs have advanced vision-language tasks but still struggle with understanding video scenes. To bridge this gap, Video Scene Graph Generation (VidSGG) has emerged to capture multi-object relationships across video frames. However, prior methods rely on pairwise connections, limiting their ability to handle complex multi-object interactions and reasoning. To this end, we propose Multimodal LLMs on a Scene HyperGraph (HyperGLM), promoting reasoning about multi-way interactions and higher-order relationships. Our approach uniquely integrates entity scene graphs, which capture spatial relationships between objects, with a procedural graph that models their causal transitions, forming a unified HyperGraph. Significantly, HyperGLM enables reasoning by injecting this unified HyperGraph into LLMs. Additionally, we introduce a new Video Scene Graph Reasoning (VSGR) dataset featuring 1.9M frames from third-person, egocentric, and drone views and supports five tasks: Scene Graph Generation, Scene Graph Anticipation, Video Question Answering, Video Captioning, and Relation Reasoning. Empirically, HyperGLM consistently outperforms state-of-the-art methods across five tasks, effectively modeling and reasoning complex relationships in diverse video scenes.
DINTR: Tracking via Diffusion-based Interpolation
Oct 14, 2024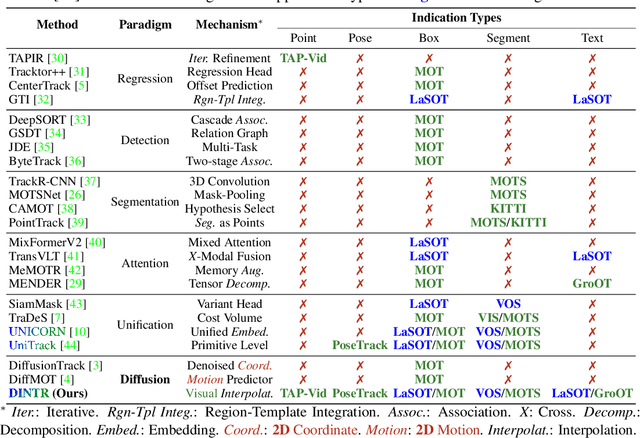
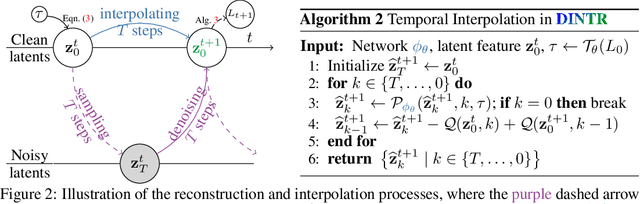


Object tracking is a fundamental task in computer vision, requiring the localization of objects of interest across video frames. Diffusion models have shown remarkable capabilities in visual generation, making them well-suited for addressing several requirements of the tracking problem. This work proposes a novel diffusion-based methodology to formulate the tracking task. Firstly, their conditional process allows for injecting indications of the target object into the generation process. Secondly, diffusion mechanics can be developed to inherently model temporal correspondences, enabling the reconstruction of actual frames in video. However, existing diffusion models rely on extensive and unnecessary mapping to a Gaussian noise domain, which can be replaced by a more efficient and stable interpolation process. Our proposed interpolation mechanism draws inspiration from classic image-processing techniques, offering a more interpretable, stable, and faster approach tailored specifically for the object tracking task. By leveraging the strengths of diffusion models while circumventing their limitations, our Diffusion-based INterpolation TrackeR (DINTR) presents a promising new paradigm and achieves a superior multiplicity on seven benchmarks across five indicator representations.
ED-SAM: An Efficient Diffusion Sampling Approach to Domain Generalization in Vision-Language Foundation Models
Jun 03, 2024The Vision-Language Foundation Model has recently shown outstanding performance in various perception learning tasks. The outstanding performance of the vision-language model mainly relies on large-scale pre-training datasets and different data augmentation techniques. However, the domain generalization problem of the vision-language foundation model needs to be addressed. This problem has limited the generalizability of the vision-language foundation model to unknown data distributions. In this paper, we introduce a new simple but efficient Diffusion Sampling approach to Domain Generalization (ED-SAM) to improve the generalizability of the vision-language foundation model. Our theoretical analysis in this work reveals the critical role and relation of the diffusion model to domain generalization in the vision-language foundation model. Then, based on the insightful analysis, we introduce a new simple yet effective Transport Transformation to diffusion sampling method. It can effectively generate adversarial samples to improve the generalizability of the foundation model against unknown data distributions. The experimental results on different scales of vision-language pre-training datasets, including CC3M, CC12M, and LAION400M, have consistently shown State-of-the-Art performance and scalability of the proposed ED-SAM approach compared to the other recent methods.
CYCLO: Cyclic Graph Transformer Approach to Multi-Object Relationship Modeling in Aerial Videos
Jun 03, 2024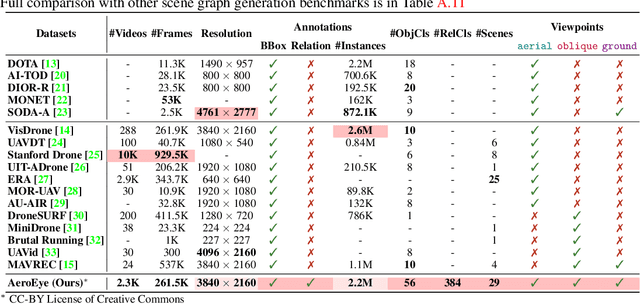
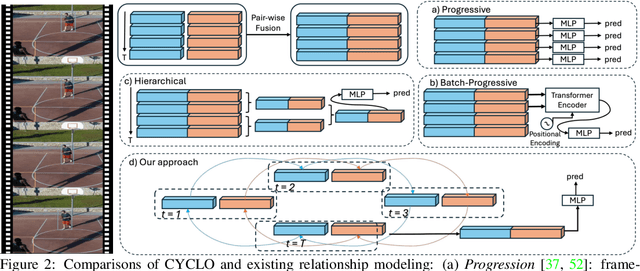
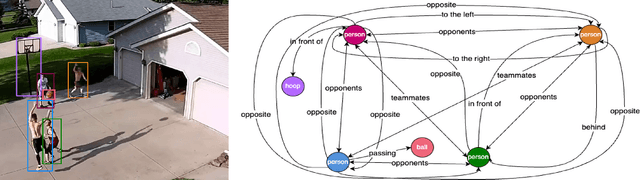

Video scene graph generation (VidSGG) has emerged as a transformative approach to capturing and interpreting the intricate relationships among objects and their temporal dynamics in video sequences. In this paper, we introduce the new AeroEye dataset that focuses on multi-object relationship modeling in aerial videos. Our AeroEye dataset features various drone scenes and includes a visually comprehensive and precise collection of predicates that capture the intricate relationships and spatial arrangements among objects. To this end, we propose the novel Cyclic Graph Transformer (CYCLO) approach that allows the model to capture both direct and long-range temporal dependencies by continuously updating the history of interactions in a circular manner. The proposed approach also allows one to handle sequences with inherent cyclical patterns and process object relationships in the correct sequential order. Therefore, it can effectively capture periodic and overlapping relationships while minimizing information loss. The extensive experiments on the AeroEye dataset demonstrate the effectiveness of the proposed CYCLO model, demonstrating its potential to perform scene understanding on drone videos. Finally, the CYCLO method consistently achieves State-of-the-Art (SOTA) results on two in-the-wild scene graph generation benchmarks, i.e., PVSG and ASPIRe.
FALCON: Fairness Learning via Contrastive Attention Approach to Continual Semantic Scene Understanding in Open World
Nov 27, 2023Continual Learning in semantic scene segmentation aims to continually learn new unseen classes in dynamic environments while maintaining previously learned knowledge. Prior studies focused on modeling the catastrophic forgetting and background shift challenges in continual learning. However, fairness, another major challenge that causes unfair predictions leading to low performance among major and minor classes, still needs to be well addressed. In addition, prior methods have yet to model the unknown classes well, thus resulting in producing non-discriminative features among unknown classes. This paper presents a novel Fairness Learning via Contrastive Attention Approach to continual learning in semantic scene understanding. In particular, we first introduce a new Fairness Contrastive Clustering loss to address the problems of catastrophic forgetting and fairness. Then, we propose an attention-based visual grammar approach to effectively model the background shift problem and unknown classes, producing better feature representations for different unknown classes. Through our experiments, our proposed approach achieves State-of-the-Art (SOTA) performance on different continual learning settings of three standard benchmarks, i.e., ADE20K, Cityscapes, and Pascal VOC. It promotes the fairness of the continual semantic segmentation model.
AerialFormer: Multi-resolution Transformer for Aerial Image Segmentation
Jun 12, 2023Aerial Image Segmentation is a top-down perspective semantic segmentation and has several challenging characteristics such as strong imbalance in the foreground-background distribution, complex background, intra-class heterogeneity, inter-class homogeneity, and tiny objects. To handle these problems, we inherit the advantages of Transformers and propose AerialFormer, which unifies Transformers at the contracting path with lightweight Multi-Dilated Convolutional Neural Networks (MD-CNNs) at the expanding path. Our AerialFormer is designed as a hierarchical structure, in which Transformer encoder outputs multi-scale features and MD-CNNs decoder aggregates information from the multi-scales. Thus, it takes both local and global contexts into consideration to render powerful representations and high-resolution segmentation. We have benchmarked AerialFormer on three common datasets including iSAID, LoveDA, and Potsdam. Comprehensive experiments and extensive ablation studies show that our proposed AerialFormer outperforms previous state-of-the-art methods with remarkable performance. Our source code will be publicly available upon acceptance.
CROVIA: Seeing Drone Scenes from Car Perspective via Cross-View Adaptation
Apr 14, 2023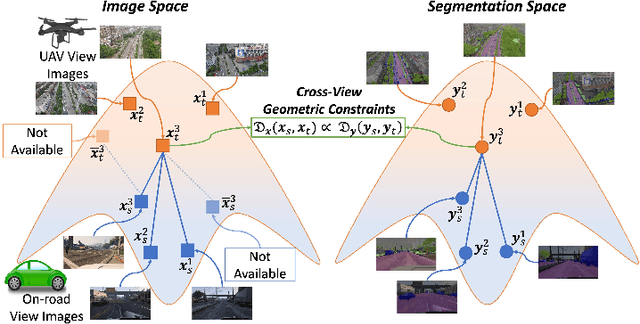

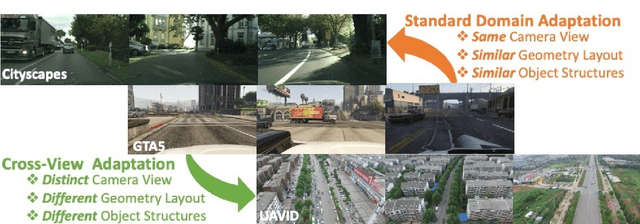

Understanding semantic scene segmentation of urban scenes captured from the Unmanned Aerial Vehicles (UAV) perspective plays a vital role in building a perception model for UAV. With the limitations of large-scale densely labeled data, semantic scene segmentation for UAV views requires a broad understanding of an object from both its top and side views. Adapting from well-annotated autonomous driving data to unlabeled UAV data is challenging due to the cross-view differences between the two data types. Our work proposes a novel Cross-View Adaptation (CROVIA) approach to effectively adapt the knowledge learned from on-road vehicle views to UAV views. First, a novel geometry-based constraint to cross-view adaptation is introduced based on the geometry correlation between views. Second, cross-view correlations from image space are effectively transferred to segmentation space without any requirement of paired on-road and UAV view data via a new Geometry-Constraint Cross-View (GeiCo) loss. Third, the multi-modal bijective networks are introduced to enforce the global structural modeling across views. Experimental results on new cross-view adaptation benchmarks introduced in this work, i.e., SYNTHIA to UAVID and GTA5 to UAVID, show the State-of-the-Art (SOTA) performance of our approach over prior adaptation methods
FREDOM: Fairness Domain Adaptation Approach to Semantic Scene Understanding
Apr 04, 2023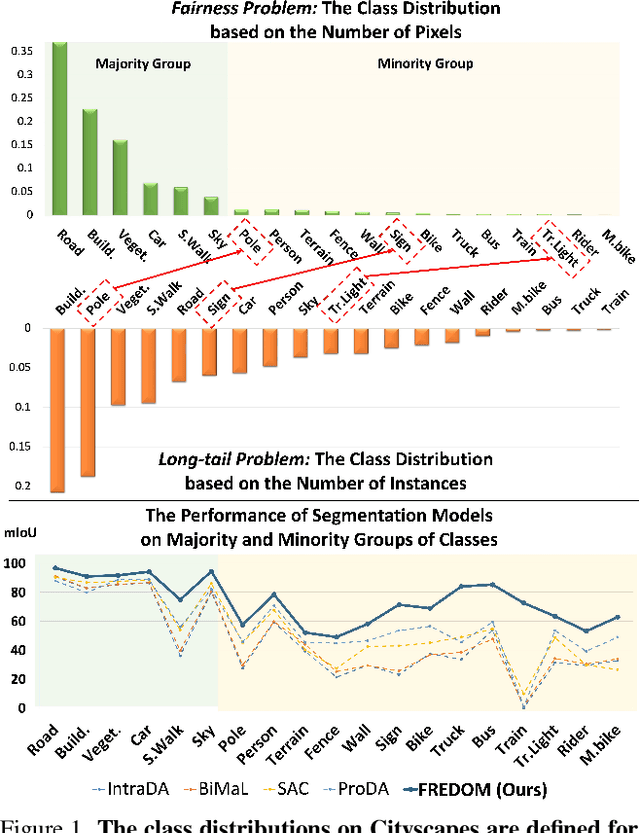



Although Domain Adaptation in Semantic Scene Segmentation has shown impressive improvement in recent years, the fairness concerns in the domain adaptation have yet to be well defined and addressed. In addition, fairness is one of the most critical aspects when deploying the segmentation models into human-related real-world applications, e.g., autonomous driving, as any unfair predictions could influence human safety. In this paper, we propose a novel Fairness Domain Adaptation (FREDOM) approach to semantic scene segmentation. In particular, from the proposed formulated fairness objective, a new adaptation framework will be introduced based on the fair treatment of class distributions. Moreover, to generally model the context of structural dependency, a new conditional structural constraint is introduced to impose the consistency of predicted segmentation. Thanks to the proposed Conditional Structure Network, the self-attention mechanism has sufficiently modeled the structural information of segmentation. Through the ablation studies, the proposed method has shown the performance improvement of the segmentation models and promoted fairness in the model predictions. The experimental results on the two standard benchmarks, i.e., SYNTHIA $\to$ Cityscapes and GTA5 $\to$ Cityscapes, have shown that our method achieved State-of-the-Art (SOTA) performance.