 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDRIVESPATIAL: A Benchmark for Spatiotemporal Intelligence in VLMs for Autonomous Driving
May 22, 2026Spatiotemporal intelligence in autonomous driving (AD) requires an agent to integrate multi-view observations into a coherent scene representation, maintain object continuity across viewpoints and time, and reason about spatial relations, interactions, and future dynamics. However, existing AD vision-language benchmarks largely focus on single-view, static, ego-centric, or single-source question answering, leaving it unclear whether current Vision-Language Models (VLMs) can truly construct and reason over dynamic driving scenes. We introduce DriveSpatial, a benchmark of 15.6K human-verified QA pairs across 20 tasks from five large-scale AD datasets. DriveSpatial evaluates four abilities: Cognitive Scene Construction, Multi-view Relational Understanding, Temporal Reasoning, and Generalization. Unlike prior benchmarks, DriveSpatial is generated from a dynamic multi-relational scene graph that encodes object states, spatial relations, interactions, camera visibility, and temporal correspondences, enabling QA pairs that enforce genuine cross-view and spatiotemporal reasoning. Evaluating 15 representative VLMs reveals a substantial human-model gap: the strongest model trails humans by 28.4 points, with Cognitive Scene Construction emerging as the key bottleneck. Further diagnostics show that language-only prompting is insufficient, while explicit BEV grounding consistently improves performance. These results suggest that current VLMs lack the scene-construction ability needed for reliable spatiotemporal driving intelligence. DriveSpatial and its construction pipeline will be released to support future research.
CodeGraphVLP: Code-as-Planner Meets Semantic-Graph State for Non-Markovian Vision-Language-Action Models
Apr 24, 2026Vision-Language-Action (VLA) models promise generalist robot manipulation, but are typically trained and deployed as short-horizon policies that assume the latest observation is sufficient for action reasoning. This assumption breaks in non-Markovian long-horizon tasks, where task-relevant evidence can be occluded or appear only earlier in the trajectory, and where clutter and distractors make fine-grained visual grounding brittle. We present CodeGraphVLP, a hierarchical framework that enables reliable long-horizon manipulation by combining a persistent semantic-graph state with an executable code-based planner and progress-guided visual-language prompting. The semantic-graph maintains task-relevant entities and relations under partial observability. The synthesized planner executes over this semantic-graph to perform efficient progress checks and outputs a subtask instruction together with subtask-relevant objects. We use these outputs to construct clutter-suppressed observations that focus the VLA executor on critical evidence. On real-world non-Markovian tasks, CodeGraphVLP improves task completion over strong VLA baselines and history-enabled variants while substantially lowering planning latency compared to VLM-in-the-loop planning. We also conduct extensive ablation studies to confirm the contributions of each component.
Clutter-Resistant Vision-Language-Action Models through Object-Centric and Geometry Grounding
Dec 27, 2025Recent Vision-Language-Action (VLA) models have made impressive progress toward general-purpose robotic manipulation by post-training large Vision-Language Models (VLMs) for action prediction. Yet most VLAs entangle perception and control in a monolithic pipeline optimized purely for action, which can erode language-conditioned grounding. In our real-world tabletop tests, policies over-grasp when the target is absent, are distracted by clutter, and overfit to background appearance. To address these issues, we propose OBEYED-VLA (OBject-centric and gEometrY groundED VLA), a framework that explicitly disentangles perceptual grounding from action reasoning. Instead of operating directly on raw RGB, OBEYED-VLA augments VLAs with a perception module that grounds multi-view inputs into task-conditioned, object-centric, and geometry-aware observations. This module includes a VLM-based object-centric grounding stage that selects task-relevant object regions across camera views, along with a complementary geometric grounding stage that emphasizes the 3D structure of these objects over their appearance. The resulting grounded views are then fed to a pretrained VLA policy, which we fine-tune exclusively on single-object demonstrations collected without environmental clutter or non-target objects. On a real-world UR10e tabletop setup, OBEYED-VLA substantially improves robustness over strong VLA baselines across four challenging regimes and multiple difficulty levels: distractor objects, absent-target rejection, background appearance changes, and cluttered manipulation of unseen objects. Ablation studies confirm that both semantic grounding and geometry-aware grounding are critical to these gains. Overall, the results indicate that making perception an explicit, object-centric component is an effective way to strengthen and generalize VLA-based robotic manipulation.
Rethinking Progression of Memory State in Robotic Manipulation: An Object-Centric Perspective
Nov 18, 2025As embodied agents operate in increasingly complex environments, the ability to perceive, track, and reason about individual object instances over time becomes essential, especially in tasks requiring sequenced interactions with visually similar objects. In these non-Markovian settings, key decision cues are often hidden in object-specific histories rather than the current scene. Without persistent memory of prior interactions (what has been interacted with, where it has been, or how it has changed) visuomotor policies may fail, repeat past actions, or overlook completed ones. To surface this challenge, we introduce LIBERO-Mem, a non-Markovian task suite for stress-testing robotic manipulation under object-level partial observability. It combines short- and long-horizon object tracking with temporally sequenced subgoals, requiring reasoning beyond the current frame. However, vision-language-action (VLA) models often struggle in such settings, with token scaling quickly becoming intractable even for tasks spanning just a few hundred frames. We propose Embodied-SlotSSM, a slot-centric VLA framework built for temporal scalability. It maintains spatio-temporally consistent slot identities and leverages them through two mechanisms: (1) slot-state-space modeling for reconstructing short-term history, and (2) a relational encoder to align the input tokens with action decoding. Together, these components enable temporally grounded, context-aware action prediction. Experiments show Embodied-SlotSSM's baseline performance on LIBERO-Mem and general tasks, offering a scalable solution for non-Markovian reasoning in object-centric robotic policies.
SlotVLA: Towards Modeling of Object-Relation Representations in Robotic Manipulation
Nov 10, 2025Inspired by how humans reason over discrete objects and their relationships, we explore whether compact object-centric and object-relation representations can form a foundation for multitask robotic manipulation. Most existing robotic multitask models rely on dense embeddings that entangle both object and background cues, raising concerns about both efficiency and interpretability. In contrast, we study object-relation-centric representations as a pathway to more structured, efficient, and explainable visuomotor control. Our contributions are two-fold. First, we introduce LIBERO+, a fine-grained benchmark dataset designed to enable and evaluate object-relation reasoning in robotic manipulation. Unlike prior datasets, LIBERO+ provides object-centric annotations that enrich demonstrations with box- and mask-level labels as well as instance-level temporal tracking, supporting compact and interpretable visuomotor representations. Second, we propose SlotVLA, a slot-attention-based framework that captures both objects and their relations for action decoding. It uses a slot-based visual tokenizer to maintain consistent temporal object representations, a relation-centric decoder to produce task-relevant embeddings, and an LLM-driven module that translates these embeddings into executable actions. Experiments on LIBERO+ demonstrate that object-centric slot and object-relation slot representations drastically reduce the number of required visual tokens, while providing competitive generalization. Together, LIBERO+ and SlotVLA provide a compact, interpretable, and effective foundation for advancing object-relation-centric robotic manipulation.
AerialFormer: Multi-resolution Transformer for Aerial Image Segmentation
Jun 12, 2023Aerial Image Segmentation is a top-down perspective semantic segmentation and has several challenging characteristics such as strong imbalance in the foreground-background distribution, complex background, intra-class heterogeneity, inter-class homogeneity, and tiny objects. To handle these problems, we inherit the advantages of Transformers and propose AerialFormer, which unifies Transformers at the contracting path with lightweight Multi-Dilated Convolutional Neural Networks (MD-CNNs) at the expanding path. Our AerialFormer is designed as a hierarchical structure, in which Transformer encoder outputs multi-scale features and MD-CNNs decoder aggregates information from the multi-scales. Thus, it takes both local and global contexts into consideration to render powerful representations and high-resolution segmentation. We have benchmarked AerialFormer on three common datasets including iSAID, LoveDA, and Potsdam. Comprehensive experiments and extensive ablation studies show that our proposed AerialFormer outperforms previous state-of-the-art methods with remarkable performance. Our source code will be publicly available upon acceptance.
VLCap: Vision-Language with Contrastive Learning for Coherent Video Paragraph Captioning
Jun 26, 2022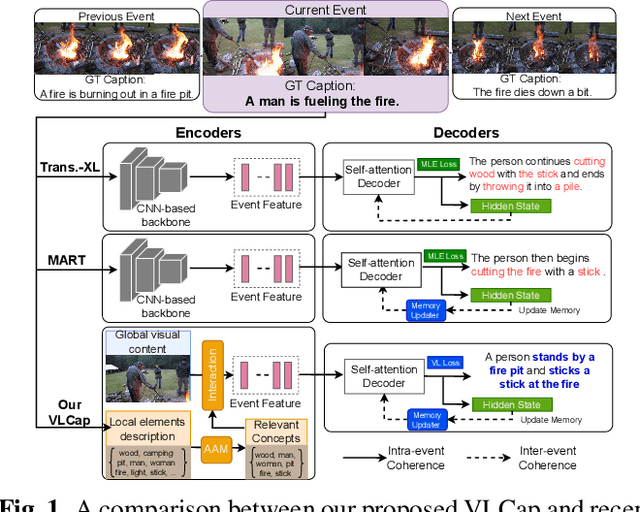
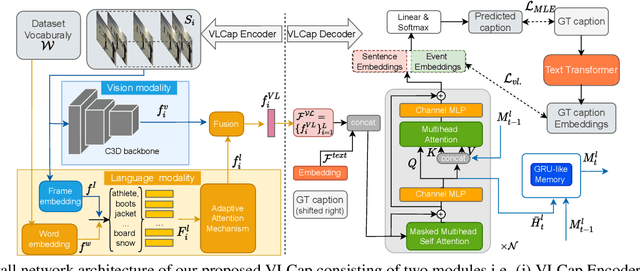

In this paper, we leverage the human perceiving process, that involves vision and language interaction, to generate a coherent paragraph description of untrimmed videos. We propose vision-language (VL) features consisting of two modalities, i.e., (i) vision modality to capture global visual content of the entire scene and (ii) language modality to extract scene elements description of both human and non-human objects (e.g. animals, vehicles, etc), visual and non-visual elements (e.g. relations, activities, etc). Furthermore, we propose to train our proposed VLCap under a contrastive learning VL loss. The experiments and ablation studies on ActivityNet Captions and YouCookII datasets show that our VLCap outperforms existing SOTA methods on both accuracy and diversity metrics.
BiMaL: Bijective Maximum Likelihood Approach to Domain Adaptation in Semantic Scene Segmentation
Aug 06, 2021
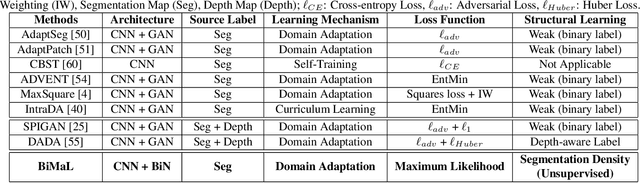
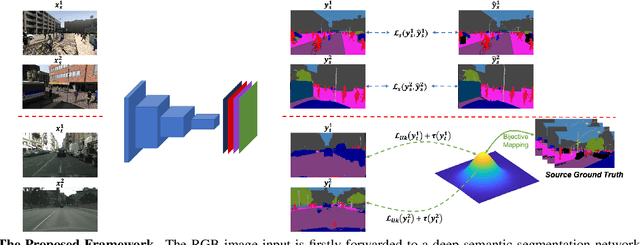
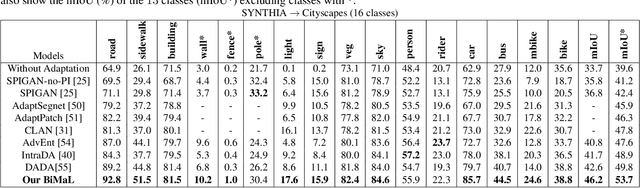
Semantic segmentation aims to predict pixel-level labels. It has become a popular task in various computer vision applications. While fully supervised segmentation methods have achieved high accuracy on large-scale vision datasets, they are unable to generalize on a new test environment or a new domain well. In this work, we first introduce a new Un-aligned Domain Score to measure the efficiency of a learned model on a new target domain in unsupervised manner. Then, we present the new Bijective Maximum Likelihood(BiMaL) loss that is a generalized form of the Adversarial Entropy Minimization without any assumption about pixel independence. We have evaluated the proposed BiMaL on two domains. The proposed BiMaL approach consistently outperforms the SOTA methods on empirical experiments on "SYNTHIA to Cityscapes", "GTA5 to Cityscapes", and "SYNTHIA to Vistas".