 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAISFormer: Amodal Instance Segmentation with Transformer
Oct 13, 2022
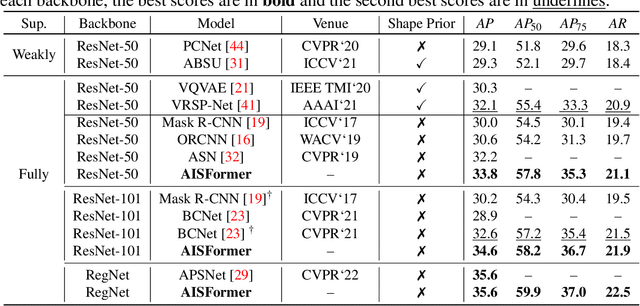


Amodal Instance Segmentation (AIS) aims to segment the region of both visible and possible occluded parts of an object instance. While Mask R-CNN-based AIS approaches have shown promising results, they are unable to model high-level features coherence due to the limited receptive field. The most recent transformer-based models show impressive performance on vision tasks, even better than Convolution Neural Networks (CNN). In this work, we present AISFormer, an AIS framework, with a Transformer-based mask head. AISFormer explicitly models the complex coherence between occluder, visible, amodal, and invisible masks within an object's regions of interest by treating them as learnable queries. Specifically, AISFormer contains four modules: (i) feature encoding: extract ROI and learn both short-range and long-range visual features. (ii) mask transformer decoding: generate the occluder, visible, and amodal mask query embeddings by a transformer decoder (iii) invisible mask embedding: model the coherence between the amodal and visible masks, and (iv) mask predicting: estimate output masks including occluder, visible, amodal and invisible. We conduct extensive experiments and ablation studies on three challenging benchmarks i.e. KINS, D2SA, and COCOA-cls to evaluate the effectiveness of AISFormer. The code is available at: https://github.com/UARK-AICV/AISFormer
VLCap: Vision-Language with Contrastive Learning for Coherent Video Paragraph Captioning
Jun 26, 2022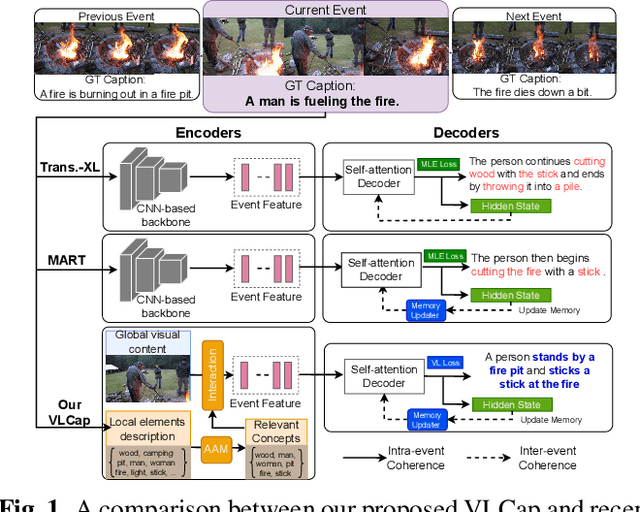
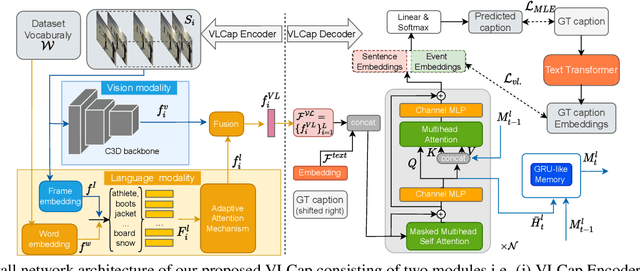

In this paper, we leverage the human perceiving process, that involves vision and language interaction, to generate a coherent paragraph description of untrimmed videos. We propose vision-language (VL) features consisting of two modalities, i.e., (i) vision modality to capture global visual content of the entire scene and (ii) language modality to extract scene elements description of both human and non-human objects (e.g. animals, vehicles, etc), visual and non-visual elements (e.g. relations, activities, etc). Furthermore, we propose to train our proposed VLCap under a contrastive learning VL loss. The experiments and ablation studies on ActivityNet Captions and YouCookII datasets show that our VLCap outperforms existing SOTA methods on both accuracy and diversity metrics.