 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFedVG: Gradient-Guided Aggregation for Enhanced Federated Learning
Feb 24, 2026Federated Learning (FL) enables collaborative model training across multiple clients without sharing their private data. However, data heterogeneity across clients leads to client drift, which degrades the overall generalization performance of the model. This effect is further compounded by overemphasis on poorly performing clients. To address this problem, we propose FedVG, a novel gradient-based federated aggregation framework that leverages a global validation set to guide the optimization process. Such a global validation set can be established using readily available public datasets, ensuring accessibility and consistency across clients without compromising privacy. In contrast to conventional approaches that prioritize client dataset volume, FedVG assesses the generalization ability of client models by measuring the magnitude of validation gradients across layers. Specifically, we compute layerwise gradient norms to derive a client-specific score that reflects how much each client needs to adjust for improved generalization on the global validation set, thereby enabling more informed and adaptive federated aggregation. Extensive experiments on both natural and medical image benchmarking datasets, across diverse model architectures, demonstrate that FedVG consistently improves performance, particularly in highly heterogeneous settings. Moreover, FedVG is modular and can be seamlessly integrated with various state-of-the-art FL algorithms, often further improving their results. Our code is available at https://github.com/alinadevkota/FedVG.
Federated Foundation Model for GI Endoscopy Images
May 30, 2025



Gastrointestinal (GI) endoscopy is essential in identifying GI tract abnormalities in order to detect diseases in their early stages and improve patient outcomes. Although deep learning has shown success in supporting GI diagnostics and decision-making, these models require curated datasets with labels that are expensive to acquire. Foundation models offer a promising solution by learning general-purpose representations, which can be finetuned for specific tasks, overcoming data scarcity. Developing foundation models for medical imaging holds significant potential, but the sensitive and protected nature of medical data presents unique challenges. Foundation model training typically requires extensive datasets, and while hospitals generate large volumes of data, privacy restrictions prevent direct data sharing, making foundation model training infeasible in most scenarios. In this work, we propose a FL framework for training foundation models for gastroendoscopy imaging, enabling data to remain within local hospital environments while contributing to a shared model. We explore several established FL algorithms, assessing their suitability for training foundation models without relying on task-specific labels, conducting experiments in both homogeneous and heterogeneous settings. We evaluate the trained foundation model on three critical downstream tasks--classification, detection, and segmentation--and demonstrate that it achieves improved performance across all tasks, highlighting the effectiveness of our approach in a federated, privacy-preserving setting.
Supervised Pretraining for Material Property Prediction
Apr 27, 2025Accurate prediction of material properties facilitates the discovery of novel materials with tailored functionalities. Deep learning models have recently shown superior accuracy and flexibility in capturing structure-property relationships. However, these models often rely on supervised learning, which requires large, well-annotated datasets an expensive and time-consuming process. Self-supervised learning (SSL) offers a promising alternative by pretraining on large, unlabeled datasets to develop foundation models that can be fine-tuned for material property prediction. In this work, we propose supervised pretraining, where available class information serves as surrogate labels to guide learning, even when downstream tasks involve unrelated material properties. We evaluate this strategy on two state-of-the-art SSL models and introduce a novel framework for supervised pretraining. To further enhance representation learning, we propose a graph-based augmentation technique that injects noise to improve robustness without structurally deforming material graphs. The resulting foundation models are fine-tuned for six challenging material property predictions, achieving significant performance gains over baselines, ranging from 2% to 6.67% improvement in mean absolute error (MAE) and establishing a new benchmark in material property prediction. This study represents the first exploration of supervised pertaining with surrogate labels in material property prediction, advancing methodology and application in the field.
Enhancing material property prediction with ensemble deep graph convolutional networks
Jul 26, 2024



Machine learning (ML) models have emerged as powerful tools for accelerating materials discovery and design by enabling accurate predictions of properties from compositional and structural data. These capabilities are vital for developing advanced technologies across fields such as energy, electronics, and biomedicine, potentially reducing the time and resources needed for new material exploration and promoting rapid innovation cycles. Recent efforts have focused on employing advanced ML algorithms, including deep learning - based graph neural network, for property prediction. Additionally, ensemble models have proven to enhance the generalizability and robustness of ML and DL. However, the use of such ensemble strategies in deep graph networks for material property prediction remains underexplored. Our research provides an in-depth evaluation of ensemble strategies in deep learning - based graph neural network, specifically targeting material property prediction tasks. By testing the Crystal Graph Convolutional Neural Network (CGCNN) and its multitask version, MT-CGCNN, we demonstrated that ensemble techniques, especially prediction averaging, substantially improve precision beyond traditional metrics for key properties like formation energy per atom ($\Delta E^{f}$), band gap ($E_{g}$) and density ($\rho$) in 33,990 stable inorganic materials. These findings support the broader application of ensemble methods to enhance predictive accuracy in the field.
Learning Transferable Object-Centric Diffeomorphic Transformations for Data Augmentation in Medical Image Segmentation
Jul 25, 2023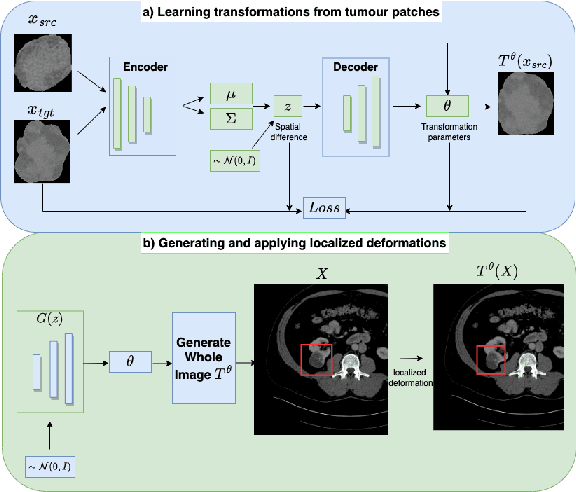
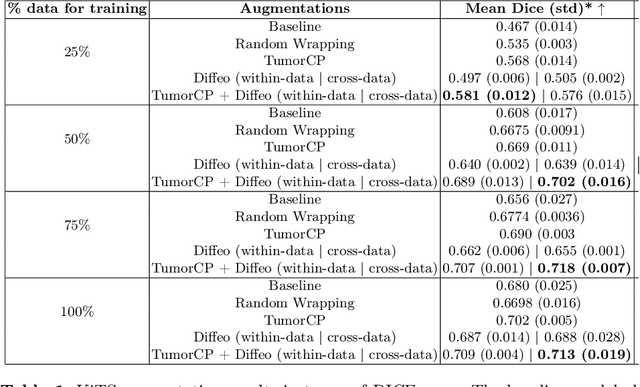

Obtaining labelled data in medical image segmentation is challenging due to the need for pixel-level annotations by experts. Recent works have shown that augmenting the object of interest with deformable transformations can help mitigate this challenge. However, these transformations have been learned globally for the image, limiting their transferability across datasets or applicability in problems where image alignment is difficult. While object-centric augmentations provide a great opportunity to overcome these issues, existing works are only focused on position and random transformations without considering shape variations of the objects. To this end, we propose a novel object-centric data augmentation model that is able to learn the shape variations for the objects of interest and augment the object in place without modifying the rest of the image. We demonstrated its effectiveness in improving kidney tumour segmentation when leveraging shape variations learned both from within the same dataset and transferred from external datasets.
T2FNorm: Extremely Simple Scaled Train-time Feature Normalization for OOD Detection
Jun 08, 2023



Neural networks are notorious for being overconfident predictors, posing a significant challenge to their safe deployment in real-world applications. While feature normalization has garnered considerable attention within the deep learning literature, current train-time regularization methods for Out-of-Distribution(OOD) detection are yet to fully exploit this potential. Indeed, the naive incorporation of feature normalization within neural networks does not guarantee substantial improvement in OOD detection performance. In this work, we introduce T2FNorm, a novel approach to transforming features to hyperspherical space during training, while employing non-transformed space for OOD-scoring purposes. This method yields a surprising enhancement in OOD detection capabilities without compromising model accuracy in in-distribution(ID). Our investigation demonstrates that the proposed technique substantially diminishes the norm of the features of all samples, more so in the case of out-of-distribution samples, thereby addressing the prevalent concern of overconfidence in neural networks. The proposed method also significantly improves various post-hoc OOD detection methods.
Interpretable Modeling and Reduction of Unknown Errors in Mechanistic Operators
Nov 02, 2022Prior knowledge about the imaging physics provides a mechanistic forward operator that plays an important role in image reconstruction, although myriad sources of possible errors in the operator could negatively impact the reconstruction solutions. In this work, we propose to embed the traditional mechanistic forward operator inside a neural function, and focus on modeling and correcting its unknown errors in an interpretable manner. This is achieved by a conditional generative model that transforms a given mechanistic operator with unknown errors, arising from a latent space of self-organizing clusters of potential sources of error generation. Once learned, the generative model can be used in place of a fixed forward operator in any traditional optimization-based reconstruction process where, together with the inverse solution, the error in prior mechanistic forward operator can be minimized and the potential source of error uncovered. We apply the presented method to the reconstruction of heart electrical potential from body surface potential. In controlled simulation experiments and in-vivo real data experiments, we demonstrate that the presented method allowed reduction of errors in the physics-based forward operator and thereby delivered inverse reconstruction of heart-surface potential with increased accuracy.
* 11 pages, Conference: Medical Image Computing and Computer Assisted Intervention
Semi-Supervised Learning for Eye Image Segmentation
Mar 17, 2021
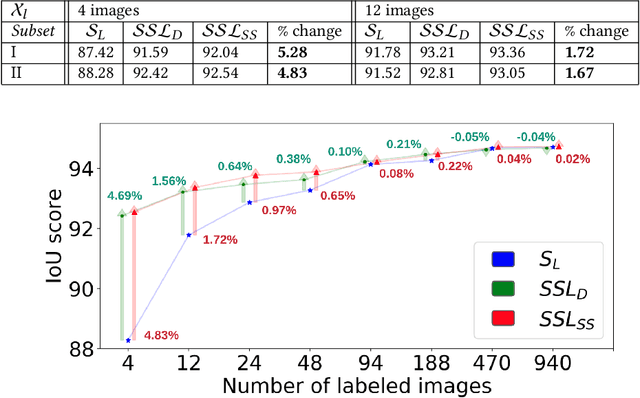
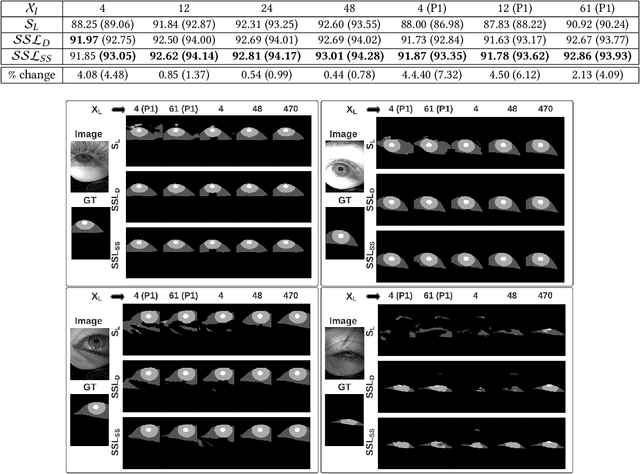
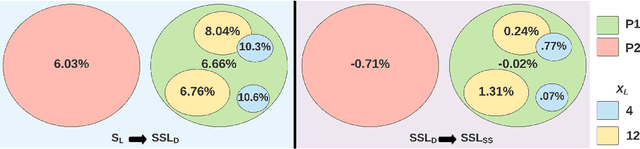
Recent advances in appearance-based models have shown improved eye tracking performance in difficult scenarios like occlusion due to eyelashes, eyelids or camera placement, and environmental reflections on the cornea and glasses. The key reason for the improvement is the accurate and robust identification of eye parts (pupil, iris, and sclera regions). The improved accuracy often comes at the cost of labeling an enormous dataset, which is complex and time-consuming. This work presents two semi-supervised learning frameworks to identify eye-parts by taking advantage of unlabeled images where labeled datasets are scarce. With these frameworks, leveraging the domain-specific augmentation and novel spatially varying transformations for image segmentation, we show improved performance on various test cases. For instance, for a model trained on just 48 labeled images, these frameworks achieved an improvement of 0.38% and 0.65% in segmentation performance over the baseline model, which is trained only with the labeled dataset.