 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEllSeg-Gen, towards Domain Generalization for head-mounted eyetracking
May 04, 2022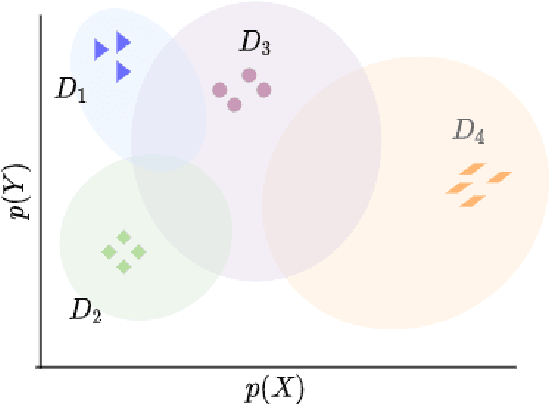
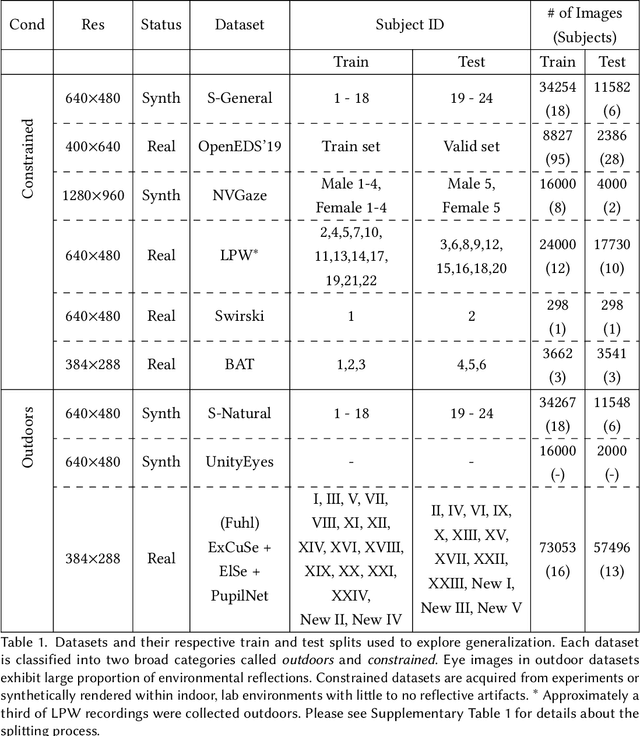
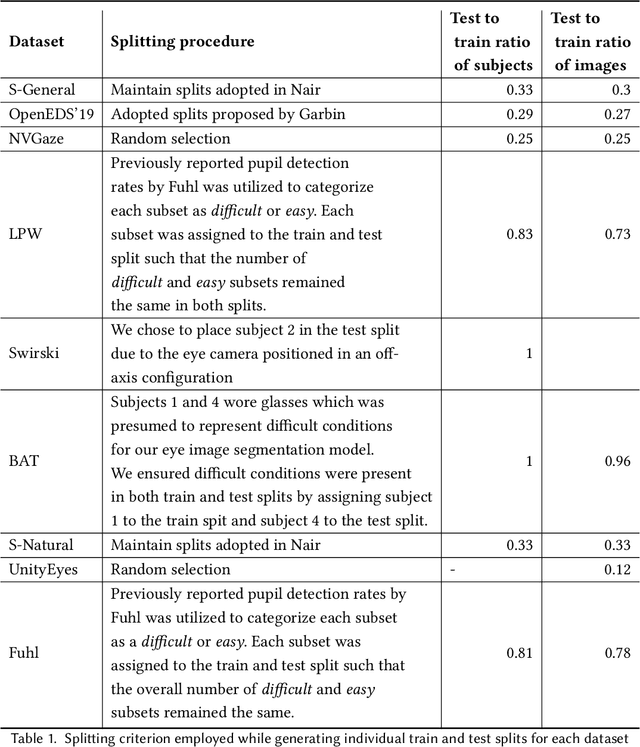
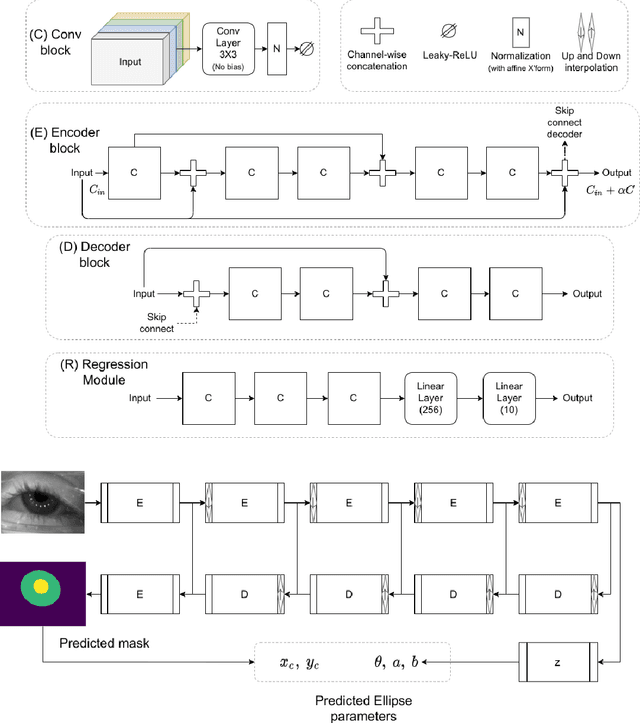
The study of human gaze behavior in natural contexts requires algorithms for gaze estimation that are robust to a wide range of imaging conditions. However, algorithms often fail to identify features such as the iris and pupil centroid in the presence of reflective artifacts and occlusions. Previous work has shown that convolutional networks excel at extracting gaze features despite the presence of such artifacts. However, these networks often perform poorly on data unseen during training. This work follows the intuition that jointly training a convolutional network with multiple datasets learns a generalized representation of eye parts. We compare the performance of a single model trained with multiple datasets against a pool of models trained on individual datasets. Results indicate that models tested on datasets in which eye images exhibit higher appearance variability benefit from multiset training. In contrast, dataset-specific models generalize better onto eye images with lower appearance variability.
Semi-Supervised Learning for Eye Image Segmentation
Mar 17, 2021
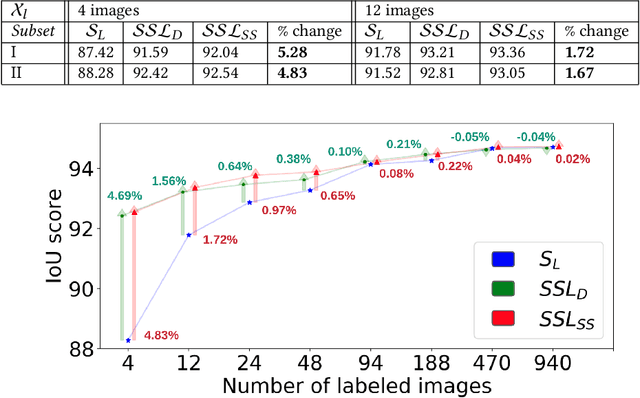
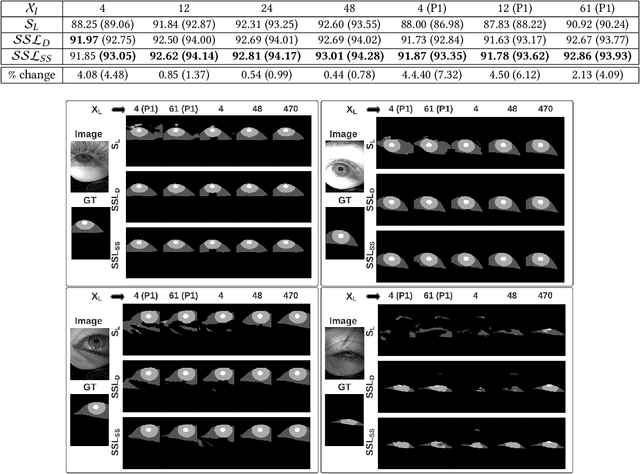
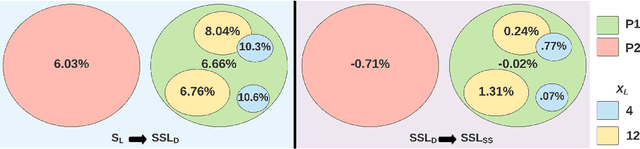
Recent advances in appearance-based models have shown improved eye tracking performance in difficult scenarios like occlusion due to eyelashes, eyelids or camera placement, and environmental reflections on the cornea and glasses. The key reason for the improvement is the accurate and robust identification of eye parts (pupil, iris, and sclera regions). The improved accuracy often comes at the cost of labeling an enormous dataset, which is complex and time-consuming. This work presents two semi-supervised learning frameworks to identify eye-parts by taking advantage of unlabeled images where labeled datasets are scarce. With these frameworks, leveraging the domain-specific augmentation and novel spatially varying transformations for image segmentation, we show improved performance on various test cases. For instance, for a model trained on just 48 labeled images, these frameworks achieved an improvement of 0.38% and 0.65% in segmentation performance over the baseline model, which is trained only with the labeled dataset.
$pi_t$- Enhancing the Precision of Eye Tracking using Iris Feature Motion Vectors
Sep 20, 2020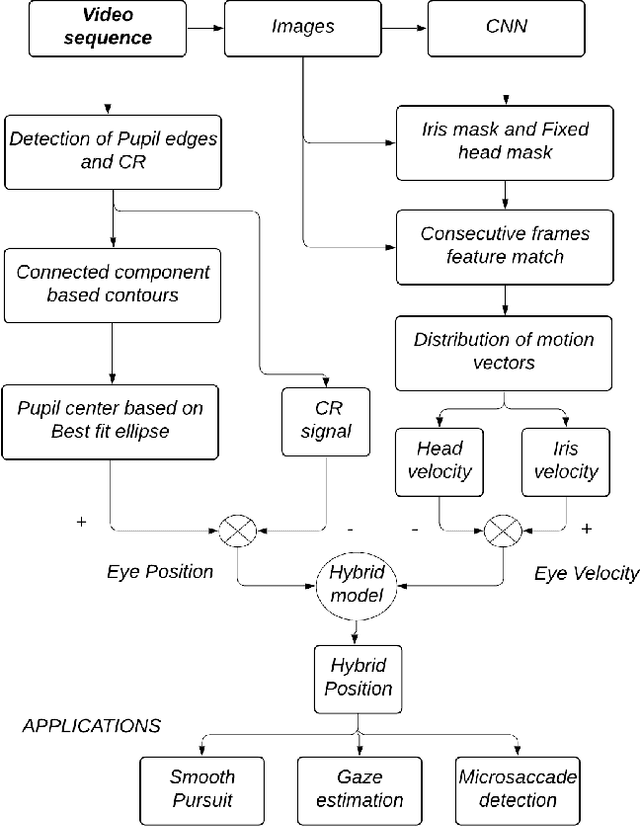


A new high-precision eye-tracking method has been demonstrated recently by tracking the motion of iris features rather than by exploiting pupil edges. While the method provides high precision, it suffers from temporal drift, an inability to track across blinks, and loss of texture matches in the presence of motion blur. In this work, we present a new methodology $pi_t$ to address these issues by optimally combining the information from both iris textures and pupil edges. With this method, we show an improvement in precision (S2S-RMS & STD) of at least 48% and 10% respectively while fixating a series of small targets and following a smoothly moving target. Further, we demonstrate the capability in the identification of microsaccades between targets separated by 0.2-degree.
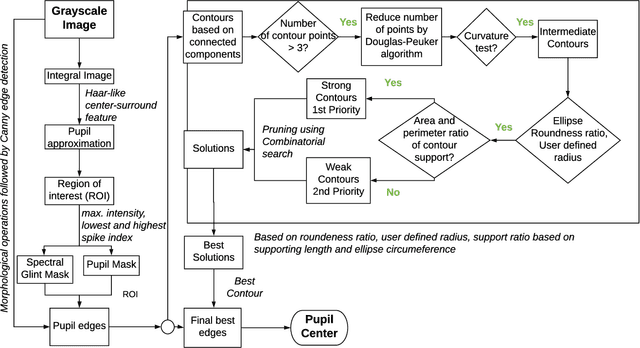
EllSeg: An Ellipse Segmentation Framework for Robust Gaze Tracking
Jul 19, 2020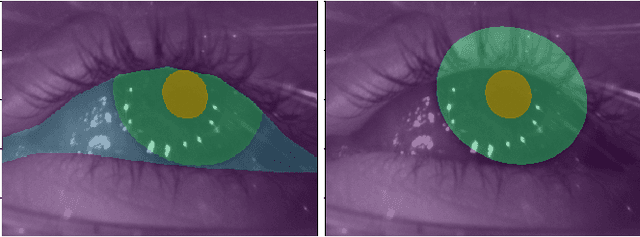
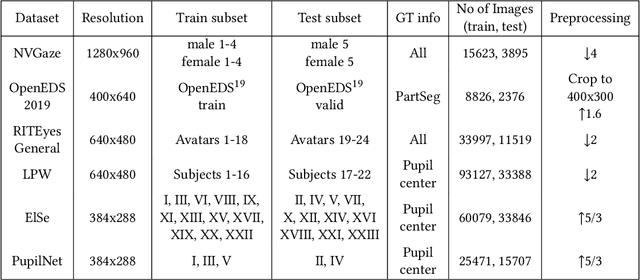
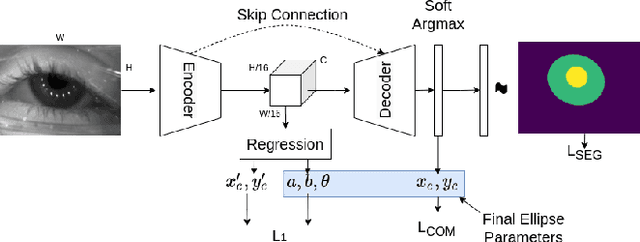
Ellipse fitting, an essential component in pupil or iris tracking based video oculography, is performed on previously segmented eye parts generated using various computer vision techniques. Several factors, such as occlusions due to eyelid shape, camera position or eyelashes, frequently break ellipse fitting algorithms that rely on well-defined pupil or iris edge segments. In this work, we propose training a convolutional neural network to directly segment entire elliptical structures and demonstrate that such a framework is robust to occlusions and offers superior pupil and iris tracking performance (at least 10$\%$ and 24$\%$ increase in pupil and iris center detection rate respectively within a two-pixel error margin) compared to using standard eye parts segmentation for multiple publicly available synthetic segmentation datasets.
RIT-Eyes: Rendering of near-eye images for eye-tracking applications
Jun 05, 2020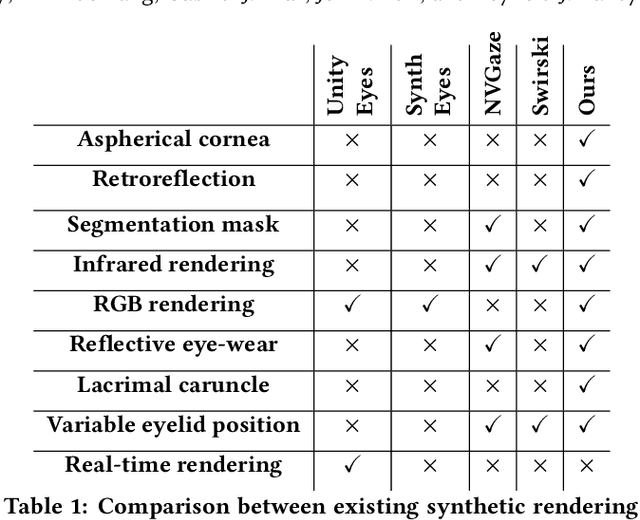
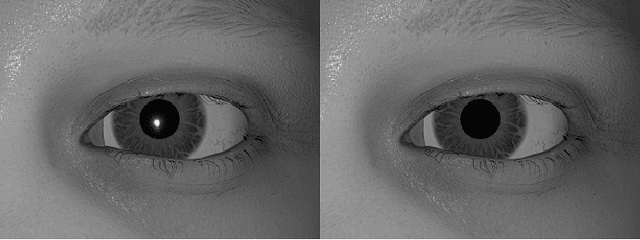
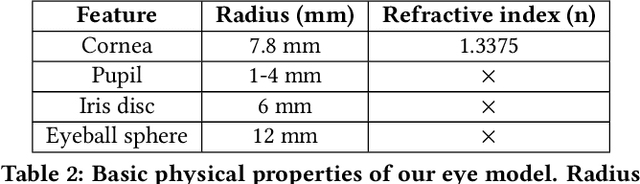
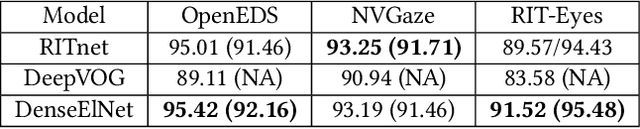
Deep neural networks for video-based eye tracking have demonstrated resilience to noisy environments, stray reflections, and low resolution. However, to train these networks, a large number of manually annotated images are required. To alleviate the cumbersome process of manual labeling, computer graphics rendering is employed to automatically generate a large corpus of annotated eye images under various conditions. In this work, we introduce a synthetic eye image generation platform that improves upon previous work by adding features such as an active deformable iris, an aspherical cornea, retinal retro-reflection, gaze-coordinated eye-lid deformations, and blinks. To demonstrate the utility of our platform, we render images reflecting the represented gaze distributions inherent in two publicly available datasets, NVGaze and OpenEDS. We also report on the performance of two semantic segmentation architectures (SegNet and RITnet) trained on rendered images and tested on the original datasets.
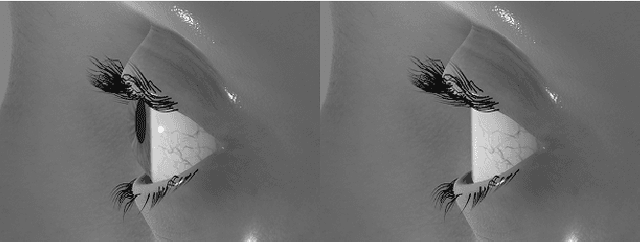
Privacy-Preserving Eye Videos using Rubber Sheet Model
Apr 03, 2020
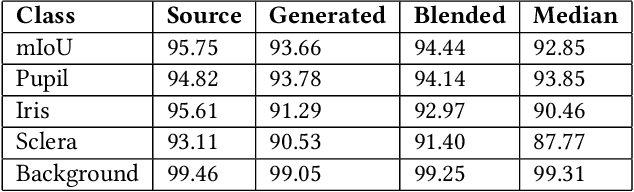


Video-based eye trackers estimate gaze based on eye images/videos. As security and privacy concerns loom over technological advancements, tackling such challenges is crucial. We present a new approach to handle privacy issues in eye videos by replacing the current identifiable iris texture with a different iris template in the video capture pipeline based on the Rubber Sheet Model. We extend to image blending and median-value representations to demonstrate that videos can be manipulated without significantly degrading segmentation and pupil detection accuracy.
RITnet: Real-time Semantic Segmentation of the Eye for Gaze Tracking
Oct 01, 2019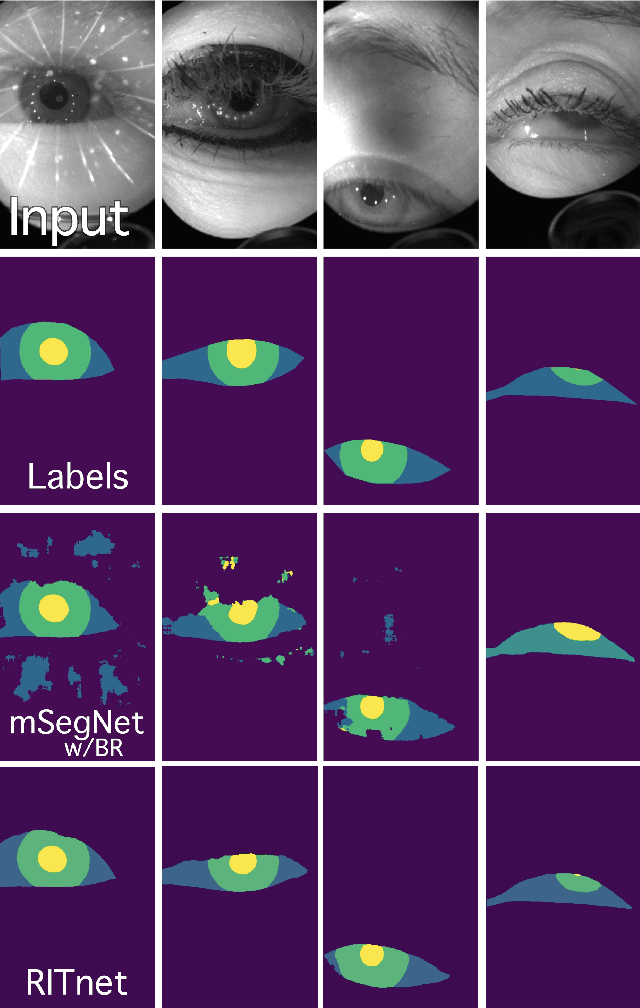
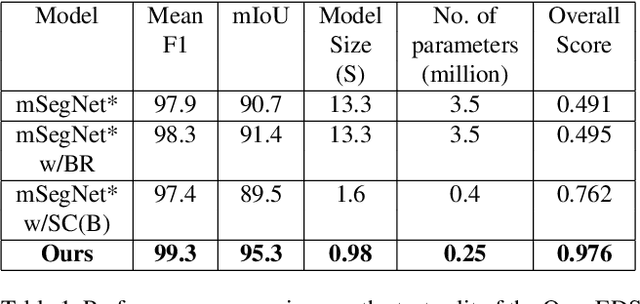
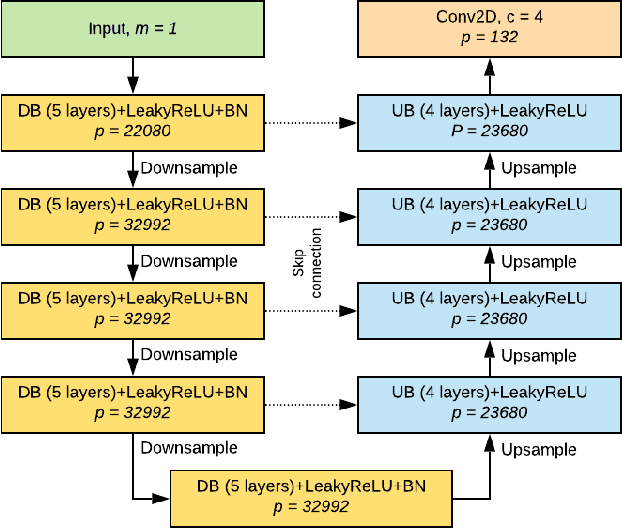
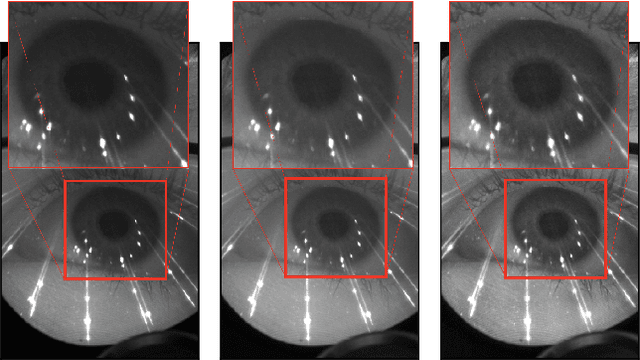
Accurate eye segmentation can improve eye-gaze estimation and support interactive computing based on visual attention; however, existing eye segmentation methods suffer from issues such as person-dependent accuracy, lack of robustness, and an inability to be run in real-time. Here, we present the RITnet model, which is a deep neural network that combines U-Net and DenseNet. RITnet is under 1 MB and achieves 95.3\% accuracy on the 2019 OpenEDS Semantic Segmentation challenge. Using a GeForce GTX 1080 Ti, RITnet tracks at $>$ 300Hz, enabling real-time gaze tracking applications. Pre-trained models and source code are available https://bitbucket.org/eye-ush/ritnet/.