 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEllSeg-Gen, towards Domain Generalization for head-mounted eyetracking
May 04, 2022
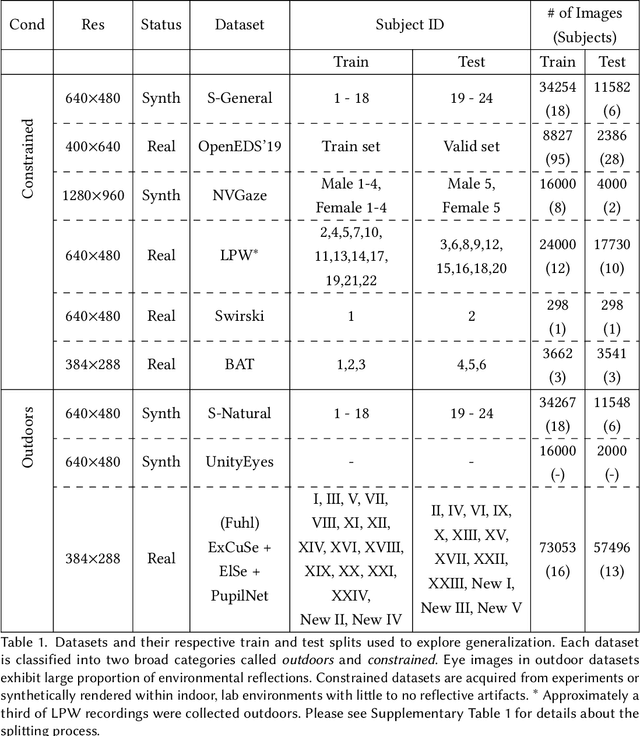
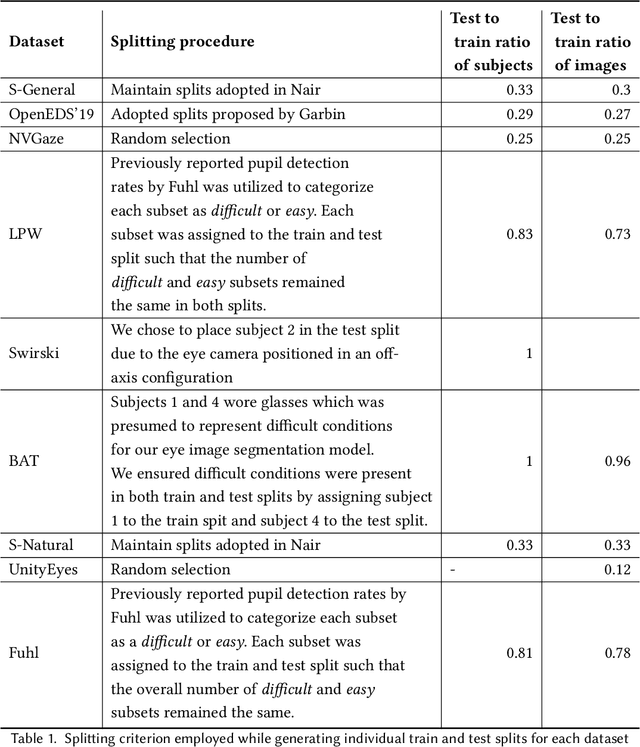
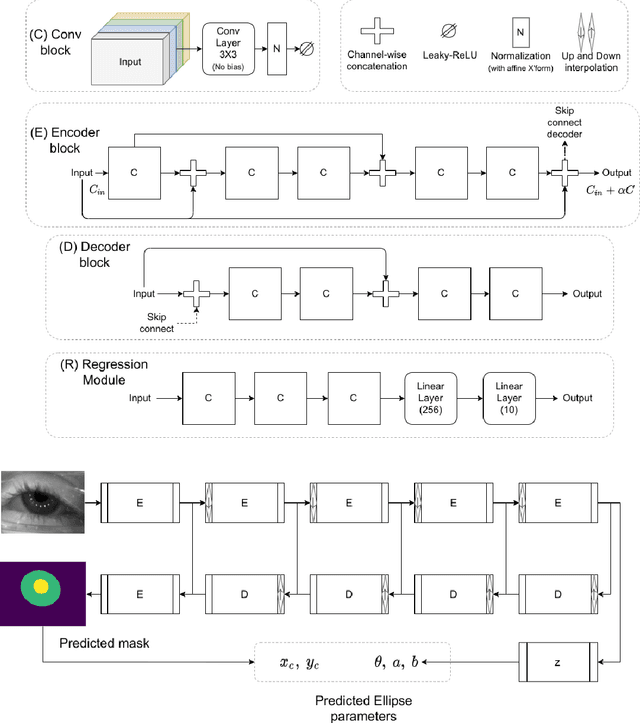
The study of human gaze behavior in natural contexts requires algorithms for gaze estimation that are robust to a wide range of imaging conditions. However, algorithms often fail to identify features such as the iris and pupil centroid in the presence of reflective artifacts and occlusions. Previous work has shown that convolutional networks excel at extracting gaze features despite the presence of such artifacts. However, these networks often perform poorly on data unseen during training. This work follows the intuition that jointly training a convolutional network with multiple datasets learns a generalized representation of eye parts. We compare the performance of a single model trained with multiple datasets against a pool of models trained on individual datasets. Results indicate that models tested on datasets in which eye images exhibit higher appearance variability benefit from multiset training. In contrast, dataset-specific models generalize better onto eye images with lower appearance variability.
EllSeg: An Ellipse Segmentation Framework for Robust Gaze Tracking
Jul 19, 2020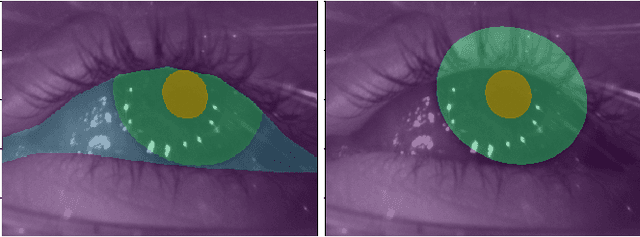
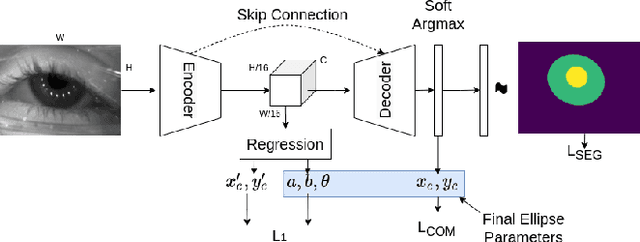
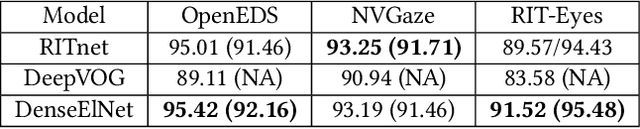
Ellipse fitting, an essential component in pupil or iris tracking based video oculography, is performed on previously segmented eye parts generated using various computer vision techniques. Several factors, such as occlusions due to eyelid shape, camera position or eyelashes, frequently break ellipse fitting algorithms that rely on well-defined pupil or iris edge segments. In this work, we propose training a convolutional neural network to directly segment entire elliptical structures and demonstrate that such a framework is robust to occlusions and offers superior pupil and iris tracking performance (at least 10$\%$ and 24$\%$ increase in pupil and iris center detection rate respectively within a two-pixel error margin) compared to using standard eye parts segmentation for multiple publicly available synthetic segmentation datasets.
RIT-Eyes: Rendering of near-eye images for eye-tracking applications
Jun 05, 2020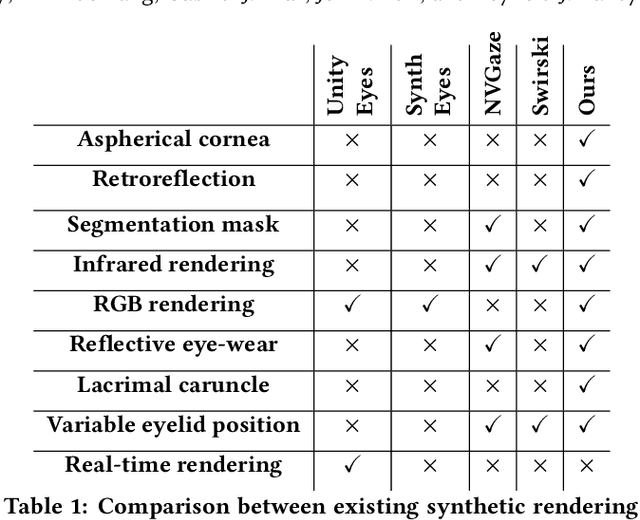
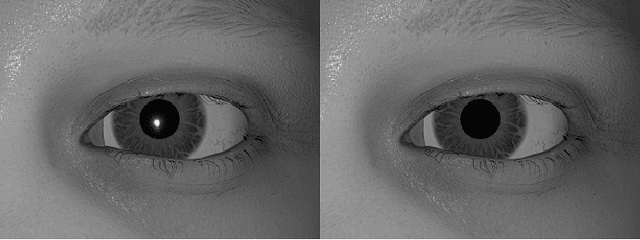
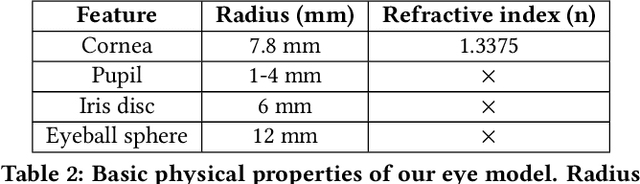
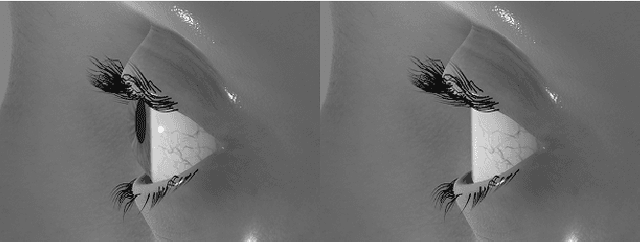
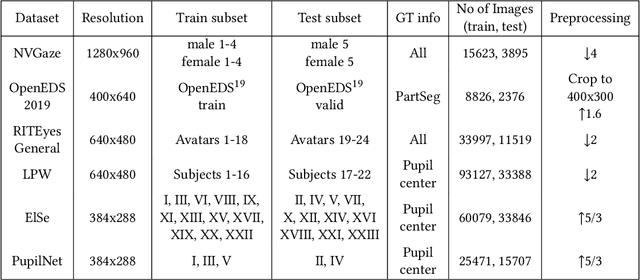
Deep neural networks for video-based eye tracking have demonstrated resilience to noisy environments, stray reflections, and low resolution. However, to train these networks, a large number of manually annotated images are required. To alleviate the cumbersome process of manual labeling, computer graphics rendering is employed to automatically generate a large corpus of annotated eye images under various conditions. In this work, we introduce a synthetic eye image generation platform that improves upon previous work by adding features such as an active deformable iris, an aspherical cornea, retinal retro-reflection, gaze-coordinated eye-lid deformations, and blinks. To demonstrate the utility of our platform, we render images reflecting the represented gaze distributions inherent in two publicly available datasets, NVGaze and OpenEDS. We also report on the performance of two semantic segmentation architectures (SegNet and RITnet) trained on rendered images and tested on the original datasets.