 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Eye Feature Estimation from Event Data Streams through Adaptive Inference State Space Modeling
Mar 14, 2026Eye feature extraction from event-based data streams can be performed efficiently and with low energy consumption, offering great utility to real-world eye tracking pipelines. However, few eye feature extractors are designed to handle sudden changes in event density caused by the changes between gaze behaviors that vary in their kinematics, leading to degraded prediction performance. In this work, we address this problem by introducing the \emph{adaptive inference state space model} (AISSM), a novel architecture for feature extraction that is capable of dynamically adjusting the relative weight placed on current versus recent information. This relative weighting is determined via estimates of the signal-to-noise ratio and event density produced by a complementary \emph{dynamic confidence network}. Lastly, we craft and evaluate a novel learning technique that improves training efficiency. Experimental results demonstrate that the AISSM system outperforms state-of-the-art models for event-based eye feature extraction.
Using Deep Learning to Increase Eye-Tracking Robustness, Accuracy, and Precision in Virtual Reality
Mar 28, 2024



Algorithms for the estimation of gaze direction from mobile and video-based eye trackers typically involve tracking a feature of the eye that moves through the eye camera image in a way that covaries with the shifting gaze direction, such as the center or boundaries of the pupil. Tracking these features using traditional computer vision techniques can be difficult due to partial occlusion and environmental reflections. Although recent efforts to use machine learning (ML) for pupil tracking have demonstrated superior results when evaluated using standard measures of segmentation performance, little is known of how these networks may affect the quality of the final gaze estimate. This work provides an objective assessment of the impact of several contemporary ML-based methods for eye feature tracking when the subsequent gaze estimate is produced using either feature-based or model-based methods. Metrics include the accuracy and precision of the gaze estimate, as well as drop-out rate.
Deep Domain Adaptation: A Sim2Real Neural Approach for Improving Eye-Tracking Systems
Mar 23, 2024Eye image segmentation is a critical step in eye tracking that has great influence over the final gaze estimate. Segmentation models trained using supervised machine learning can excel at this task, their effectiveness is determined by the degree of overlap between the narrow distributions of image properties defined by the target dataset and highly specific training datasets, of which there are few. Attempts to broaden the distribution of existing eye image datasets through the inclusion of synthetic eye images have found that a model trained on synthetic images will often fail to generalize back to real-world eye images. In remedy, we use dimensionality-reduction techniques to measure the overlap between the target eye images and synthetic training data, and to prune the training dataset in a manner that maximizes distribution overlap. We demonstrate that our methods result in robust, improved performance when tackling the discrepancy between simulation and real-world data samples.
A Neural Active Inference Model of Perceptual-Motor Learning
Nov 16, 2022



The active inference framework (AIF) is a promising new computational framework grounded in contemporary neuroscience that can produce human-like behavior through reward-based learning. In this study, we test the ability for the AIF to capture the role of anticipation in the visual guidance of action in humans through the systematic investigation of a visual-motor task that has been well-explored -- that of intercepting a target moving over a ground plane. Previous research demonstrated that humans performing this task resorted to anticipatory changes in speed intended to compensate for semi-predictable changes in target speed later in the approach. To capture this behavior, our proposed "neural" AIF agent uses artificial neural networks to select actions on the basis of a very short term prediction of the information about the task environment that these actions would reveal along with a long-term estimate of the resulting cumulative expected free energy. Systematic variation revealed that anticipatory behavior emerged only when required by limitations on the agent's movement capabilities, and only when the agent was able to estimate accumulated free energy over sufficiently long durations into the future. In addition, we present a novel formulation of the prior function that maps a multi-dimensional world-state to a uni-dimensional distribution of free-energy. Together, these results demonstrate the use of AIF as a plausible model of anticipatory visually guided behavior in humans.
EllSeg-Gen, towards Domain Generalization for head-mounted eyetracking
May 04, 2022
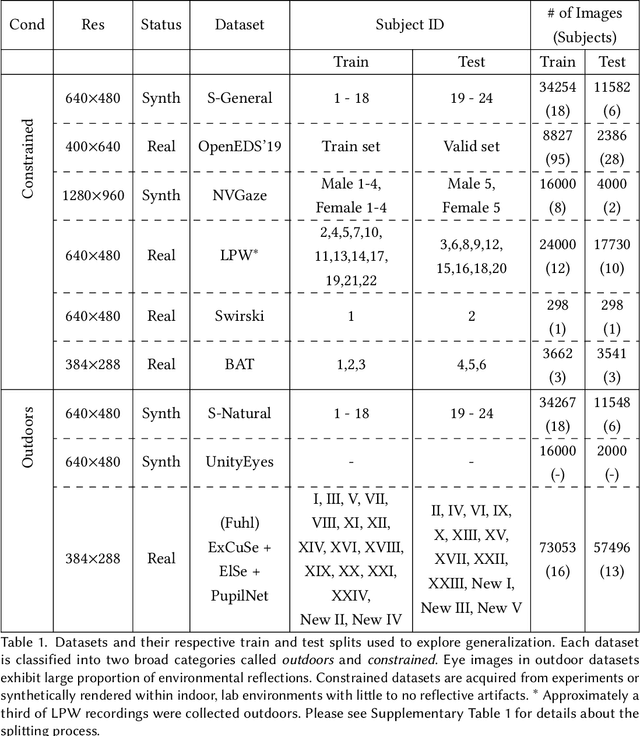
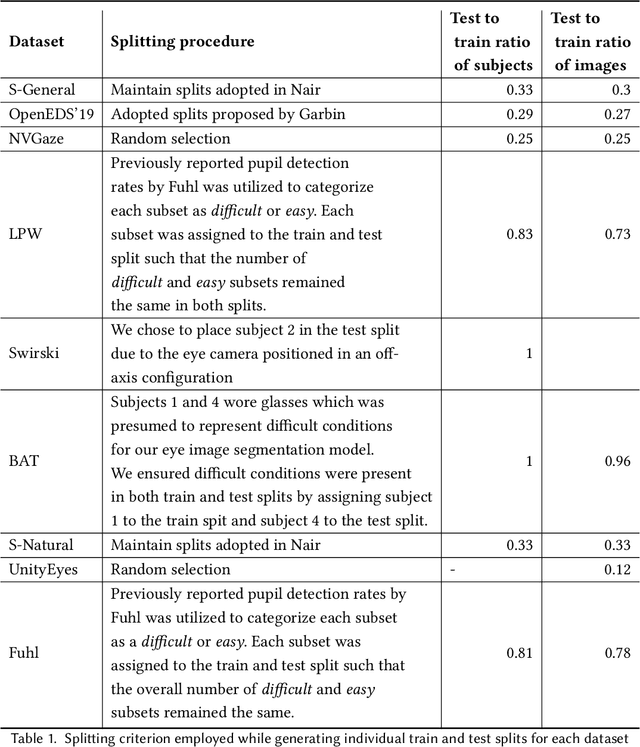
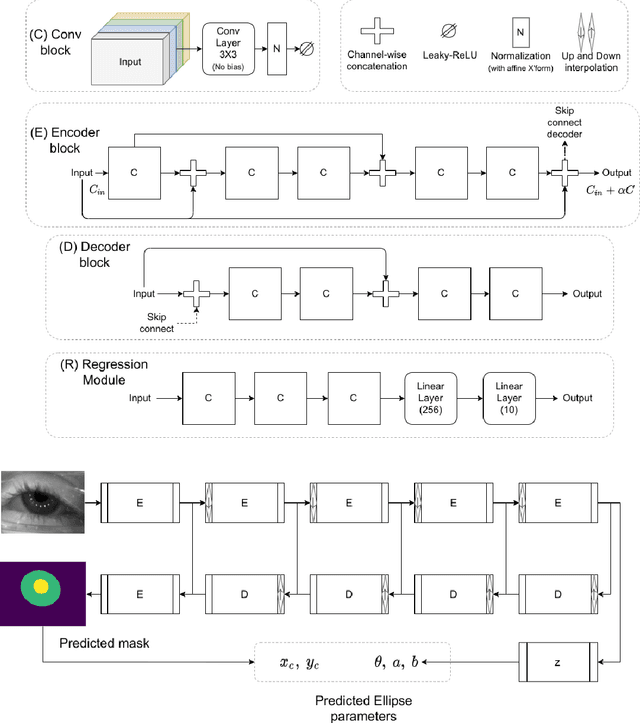
The study of human gaze behavior in natural contexts requires algorithms for gaze estimation that are robust to a wide range of imaging conditions. However, algorithms often fail to identify features such as the iris and pupil centroid in the presence of reflective artifacts and occlusions. Previous work has shown that convolutional networks excel at extracting gaze features despite the presence of such artifacts. However, these networks often perform poorly on data unseen during training. This work follows the intuition that jointly training a convolutional network with multiple datasets learns a generalized representation of eye parts. We compare the performance of a single model trained with multiple datasets against a pool of models trained on individual datasets. Results indicate that models tested on datasets in which eye images exhibit higher appearance variability benefit from multiset training. In contrast, dataset-specific models generalize better onto eye images with lower appearance variability.
EllSeg: An Ellipse Segmentation Framework for Robust Gaze Tracking
Jul 19, 2020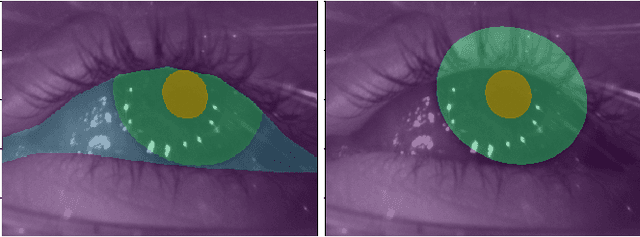
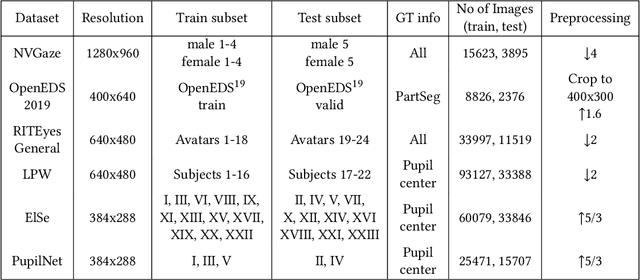
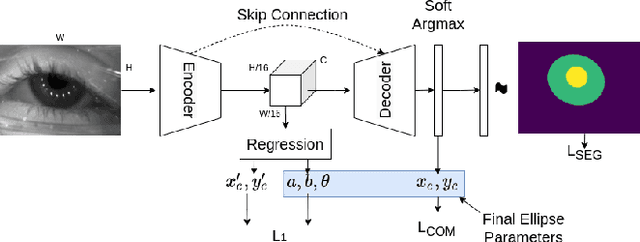
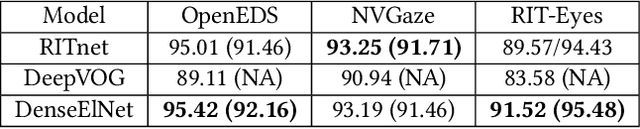
Ellipse fitting, an essential component in pupil or iris tracking based video oculography, is performed on previously segmented eye parts generated using various computer vision techniques. Several factors, such as occlusions due to eyelid shape, camera position or eyelashes, frequently break ellipse fitting algorithms that rely on well-defined pupil or iris edge segments. In this work, we propose training a convolutional neural network to directly segment entire elliptical structures and demonstrate that such a framework is robust to occlusions and offers superior pupil and iris tracking performance (at least 10$\%$ and 24$\%$ increase in pupil and iris center detection rate respectively within a two-pixel error margin) compared to using standard eye parts segmentation for multiple publicly available synthetic segmentation datasets.
RIT-Eyes: Rendering of near-eye images for eye-tracking applications
Jun 05, 2020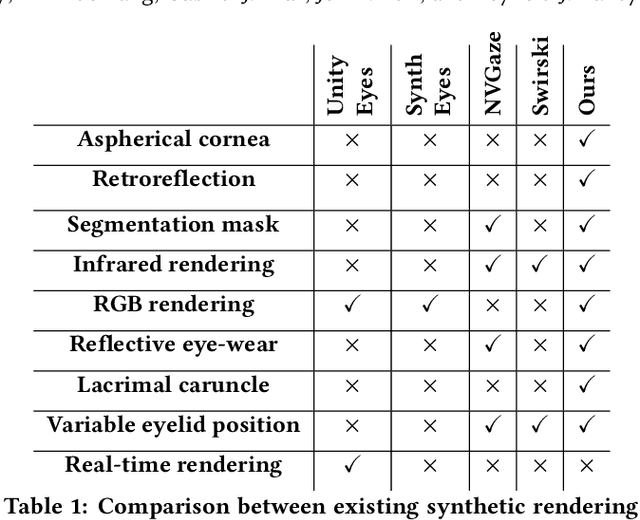
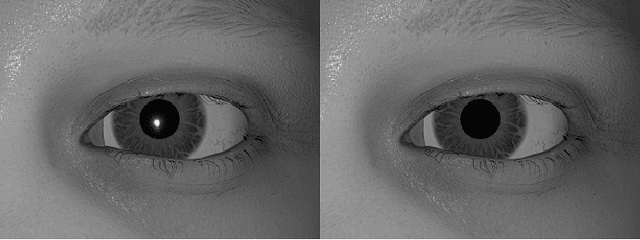
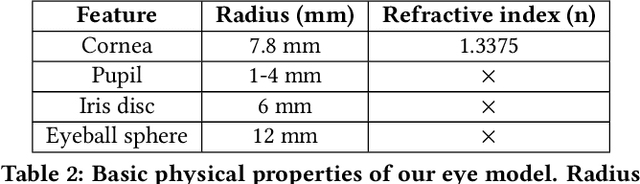
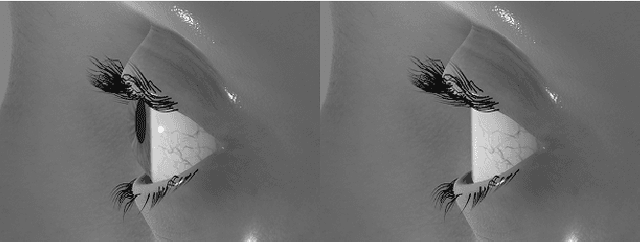
Deep neural networks for video-based eye tracking have demonstrated resilience to noisy environments, stray reflections, and low resolution. However, to train these networks, a large number of manually annotated images are required. To alleviate the cumbersome process of manual labeling, computer graphics rendering is employed to automatically generate a large corpus of annotated eye images under various conditions. In this work, we introduce a synthetic eye image generation platform that improves upon previous work by adding features such as an active deformable iris, an aspherical cornea, retinal retro-reflection, gaze-coordinated eye-lid deformations, and blinks. To demonstrate the utility of our platform, we render images reflecting the represented gaze distributions inherent in two publicly available datasets, NVGaze and OpenEDS. We also report on the performance of two semantic segmentation architectures (SegNet and RITnet) trained on rendered images and tested on the original datasets.