 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRIT-Eyes: Rendering of near-eye images for eye-tracking applications
Jun 05, 2020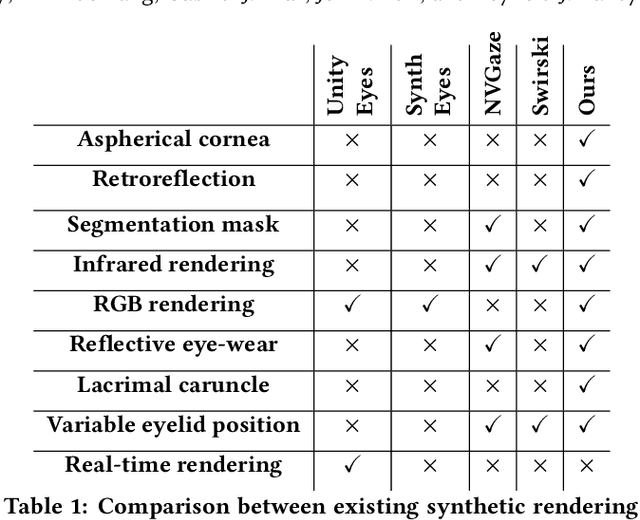
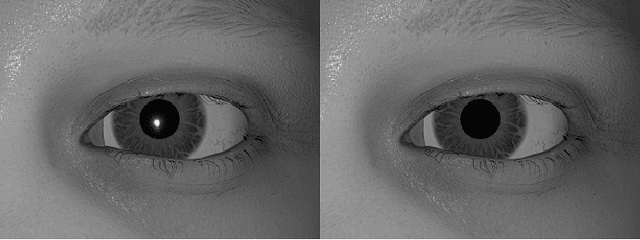
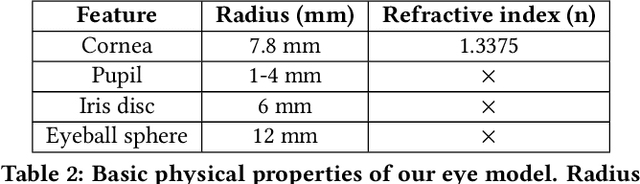
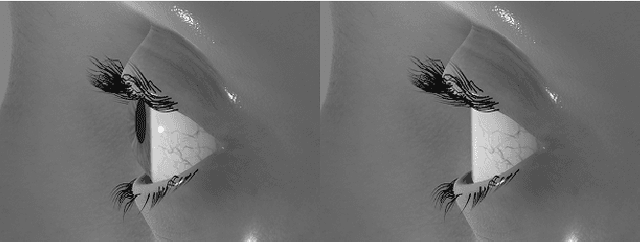
Deep neural networks for video-based eye tracking have demonstrated resilience to noisy environments, stray reflections, and low resolution. However, to train these networks, a large number of manually annotated images are required. To alleviate the cumbersome process of manual labeling, computer graphics rendering is employed to automatically generate a large corpus of annotated eye images under various conditions. In this work, we introduce a synthetic eye image generation platform that improves upon previous work by adding features such as an active deformable iris, an aspherical cornea, retinal retro-reflection, gaze-coordinated eye-lid deformations, and blinks. To demonstrate the utility of our platform, we render images reflecting the represented gaze distributions inherent in two publicly available datasets, NVGaze and OpenEDS. We also report on the performance of two semantic segmentation architectures (SegNet and RITnet) trained on rendered images and tested on the original datasets.
RITnet: Real-time Semantic Segmentation of the Eye for Gaze Tracking
Oct 01, 2019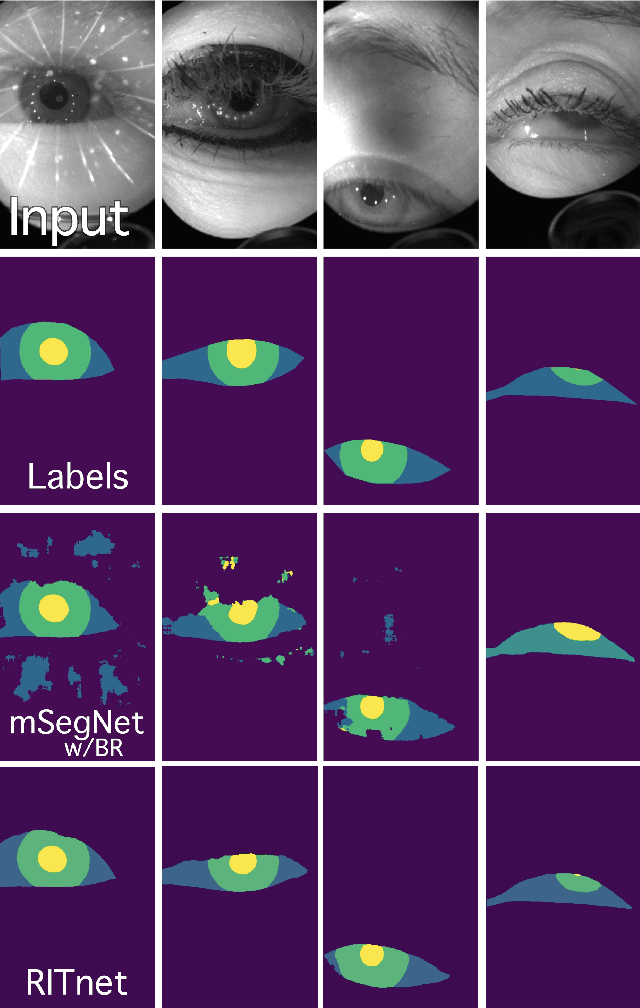
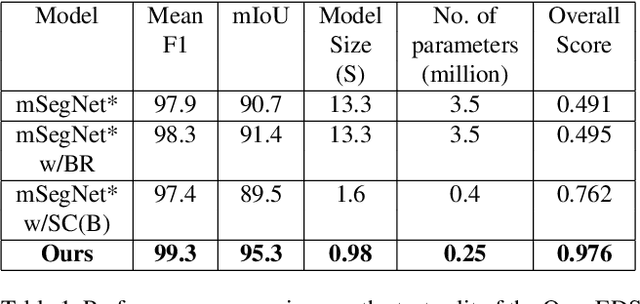
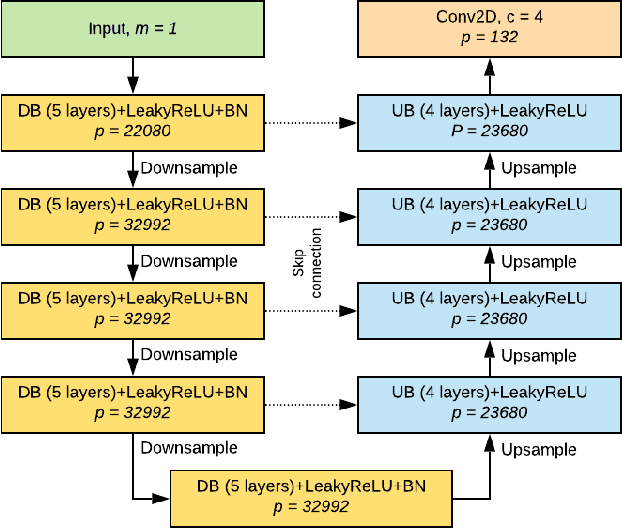
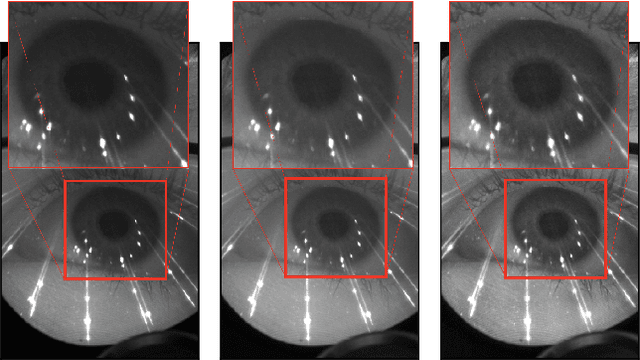
Accurate eye segmentation can improve eye-gaze estimation and support interactive computing based on visual attention; however, existing eye segmentation methods suffer from issues such as person-dependent accuracy, lack of robustness, and an inability to be run in real-time. Here, we present the RITnet model, which is a deep neural network that combines U-Net and DenseNet. RITnet is under 1 MB and achieves 95.3\% accuracy on the 2019 OpenEDS Semantic Segmentation challenge. Using a GeForce GTX 1080 Ti, RITnet tracks at $>$ 300Hz, enabling real-time gaze tracking applications. Pre-trained models and source code are available https://bitbucket.org/eye-ush/ritnet/.