 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLeveraging Content and Context Cues for Low-Light Image Enhancement
Dec 10, 2024

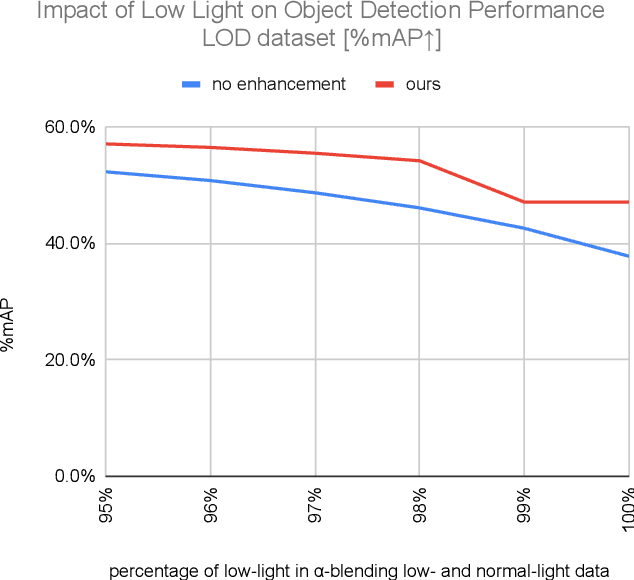

Low-light conditions have an adverse impact on machine cognition, limiting the performance of computer vision systems in real life. Since low-light data is limited and difficult to annotate, we focus on image processing to enhance low-light images and improve the performance of any downstream task model, instead of fine-tuning each of the models which can be prohibitively expensive. We propose to improve the existing zero-reference low-light enhancement by leveraging the CLIP model to capture image prior and for semantic guidance. Specifically, we propose a data augmentation strategy to learn an image prior via prompt learning, based on image sampling, to learn the image prior without any need for paired or unpaired normal-light data. Next, we propose a semantic guidance strategy that maximally takes advantage of existing low-light annotation by introducing both content and context cues about the image training patches. We experimentally show, in a qualitative study, that the proposed prior and semantic guidance help to improve the overall image contrast and hue, as well as improve background-foreground discrimination, resulting in reduced over-saturation and noise over-amplification, common in related zero-reference methods. As we target machine cognition, rather than rely on assuming the correlation between human perception and downstream task performance, we conduct and present an ablation study and comparison with related zero-reference methods in terms of task-based performance across many low-light datasets, including image classification, object and face detection, showing the effectiveness of our proposed method.
Unsupervised Image Prior via Prompt Learning and CLIP Semantic Guidance for Low-Light Image Enhancement
May 19, 2024



Currently, low-light conditions present a significant challenge for machine cognition. In this paper, rather than optimizing models by assuming that human and machine cognition are correlated, we use zero-reference low-light enhancement to improve the performance of downstream task models. We propose to improve the zero-reference low-light enhancement method by leveraging the rich visual-linguistic CLIP prior without any need for paired or unpaired normal-light data, which is laborious and difficult to collect. We propose a simple but effective strategy to learn prompts that help guide the enhancement method and experimentally show that the prompts learned without any need for normal-light data improve image contrast, reduce over-enhancement, and reduce noise over-amplification. Next, we propose to reuse the CLIP model for semantic guidance via zero-shot open vocabulary classification to optimize low-light enhancement for task-based performance rather than human visual perception. We conduct extensive experimental results showing that the proposed method leads to consistent improvements across various datasets regarding task-based performance and compare our method against state-of-the-art methods, showing favorable results across various low-light datasets.
Tracking-Assisted Object Detection with Event Cameras
Mar 27, 2024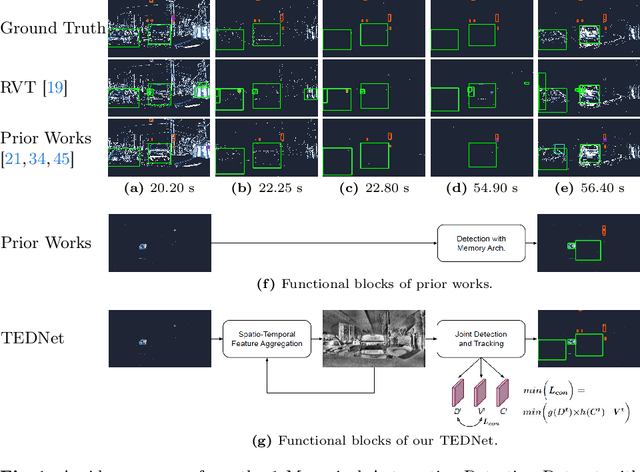

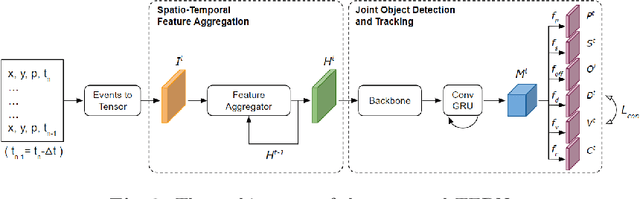

Event-based object detection has recently garnered attention in the computer vision community due to the exceptional properties of event cameras, such as high dynamic range and no motion blur. However, feature asynchronism and sparsity cause invisible objects due to no relative motion to the camera, posing a significant challenge in the task. Prior works have studied various memory mechanisms to preserve as many features as possible at the current time, guided by temporal clues. While these implicit-learned memories retain some short-term information, they still struggle to preserve long-term features effectively. In this paper, we consider those invisible objects as pseudo-occluded objects and aim to reveal their features. Firstly, we introduce visibility attribute of objects and contribute an auto-labeling algorithm to append additional visibility labels on an existing event camera dataset. Secondly, we exploit tracking strategies for pseudo-occluded objects to maintain their permanence and retain their bounding boxes, even when features have not been available for a very long time. These strategies can be treated as an explicit-learned memory guided by the tracking objective to record the displacements of objects across frames. Lastly, we propose a spatio-temporal feature aggregation module to enrich the latent features and a consistency loss to increase the robustness of the overall pipeline. We conduct comprehensive experiments to verify our method's effectiveness where still objects are retained but real occluded objects are discarded. The results demonstrate that (1) the additional visibility labels can assist in supervised training, and (2) our method outperforms state-of-the-art approaches with a significant improvement of 7.9% absolute mAP.
GenISP: Neural ISP for Low-Light Machine Cognition
May 07, 2022
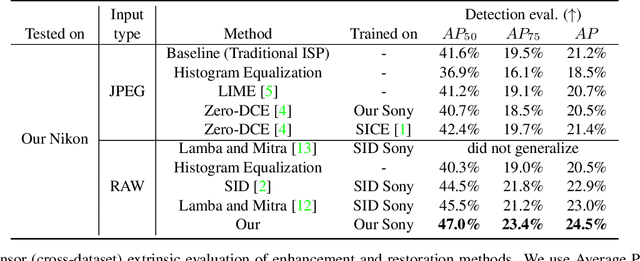


Object detection in low-light conditions remains a challenging but important problem with many practical implications. Some recent works show that, in low-light conditions, object detectors using raw image data are more robust than detectors using image data processed by a traditional ISP pipeline. To improve detection performance in low-light conditions, one can fine-tune the detector to use raw image data or use a dedicated low-light neural pipeline trained with paired low- and normal-light data to restore and enhance the image. However, different camera sensors have different spectral sensitivity and learning-based models using raw images process data in the sensor-specific color space. Thus, once trained, they do not guarantee generalization to other camera sensors. We propose to improve generalization to unseen camera sensors by implementing a minimal neural ISP pipeline for machine cognition, named GenISP, that explicitly incorporates Color Space Transformation to a device-independent color space. We also propose a two-stage color processing implemented by two image-to-parameter modules that take down-sized image as input and regress global color correction parameters. Moreover, we propose to train our proposed GenISP under the guidance of a pre-trained object detector and avoid making assumptions about perceptual quality of the image, but rather optimize the image representation for machine cognition. At the inference stage, GenISP can be paired with any object detector. We perform extensive experiments to compare our method to other low-light image restoration and enhancement methods in an extrinsic task-based evaluation and validate that GenISP can generalize to unseen sensors and object detectors. Finally, we contribute a low-light dataset of 7K raw images annotated with 46K bounding boxes for task-based benchmarking of future low-light image restoration and object detection.
RITnet: Real-time Semantic Segmentation of the Eye for Gaze Tracking
Oct 01, 2019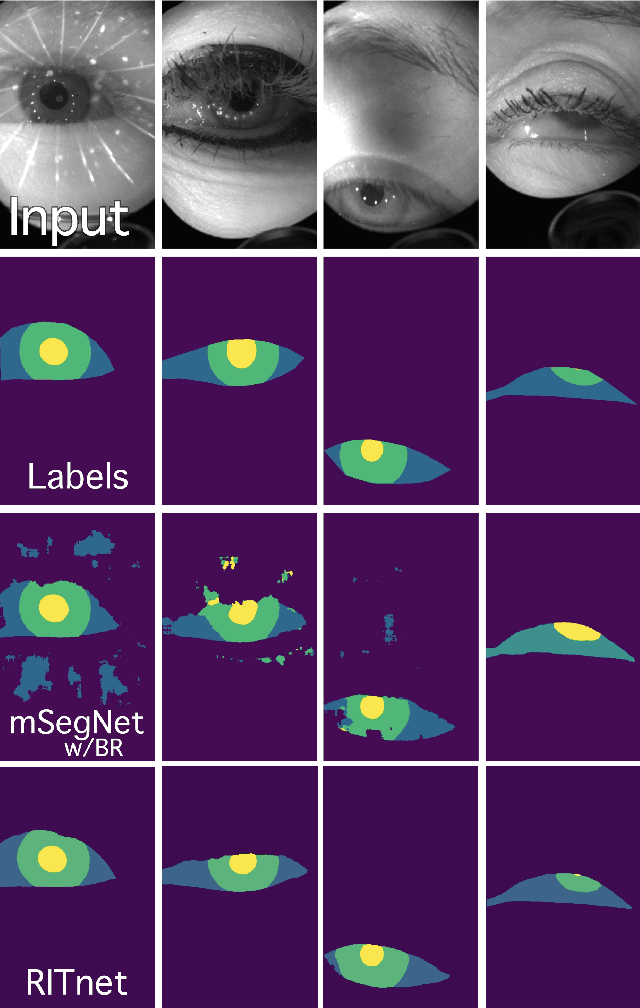
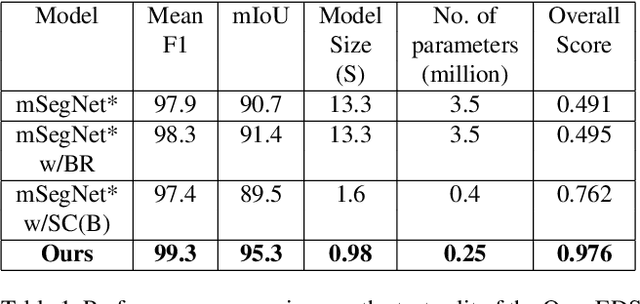
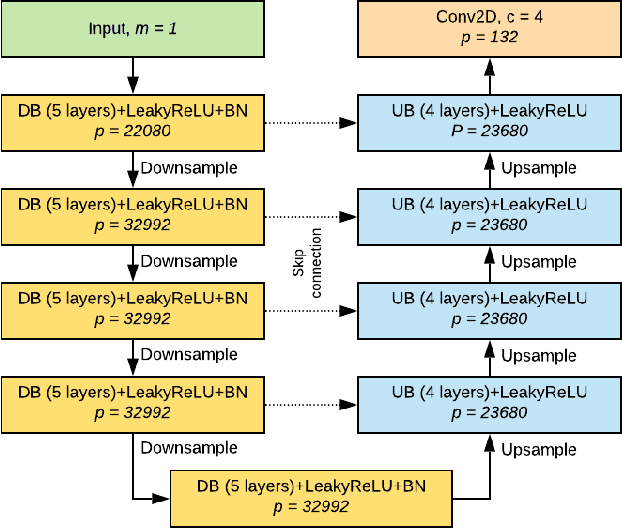
Accurate eye segmentation can improve eye-gaze estimation and support interactive computing based on visual attention; however, existing eye segmentation methods suffer from issues such as person-dependent accuracy, lack of robustness, and an inability to be run in real-time. Here, we present the RITnet model, which is a deep neural network that combines U-Net and DenseNet. RITnet is under 1 MB and achieves 95.3\% accuracy on the 2019 OpenEDS Semantic Segmentation challenge. Using a GeForce GTX 1080 Ti, RITnet tracks at $>$ 300Hz, enabling real-time gaze tracking applications. Pre-trained models and source code are available https://bitbucket.org/eye-ush/ritnet/.
A Distance Map Regularized CNN for Cardiac Cine MR Image Segmentation
Jan 04, 2019
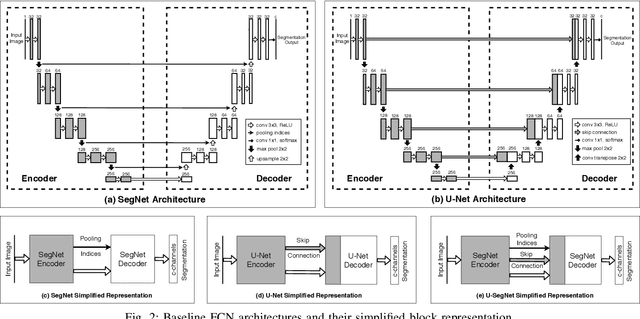
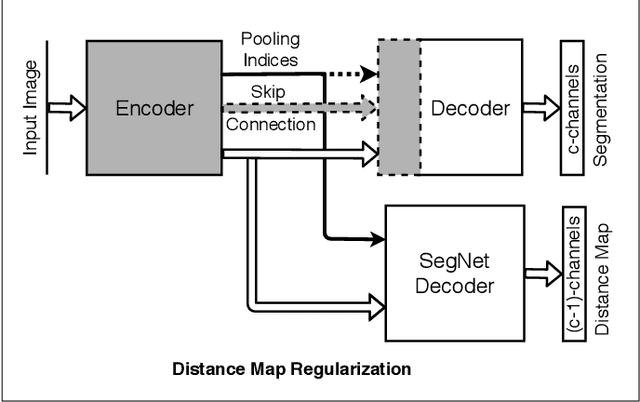
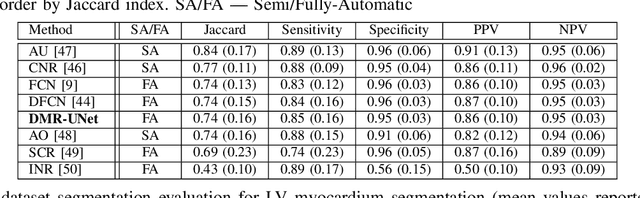
Cardiac image segmentation is a critical process for generating personalized models of the heart and for quantifying cardiac performance parameters. Several convolutional neural network (CNN) architectures have been proposed to segment the heart chambers from cardiac cine MR images. Here we propose a multi-task learning (MTL)-based regularization framework for cardiac MR image segmentation. The network is trained to perform the main task of semantic segmentation, along with a simultaneous, auxiliary task of pixel-wise distance map regression. The proposed distance map regularizer is a decoder network added to the bottleneck layer of an existing CNN architecture, facilitating the network to learn robust global features. The regularizer block is removed after training, so that the original number of network parameters does not change. We show that the proposed regularization method improves both binary and multi-class segmentation performance over the corresponding state-of-the-art CNN architectures on two publicly available cardiac cine MRI datasets, obtaining average dice coefficient of 0.84$\pm$0.03 and 0.91$\pm$0.04, respectively. Furthermore, we also demonstrate improved generalization performance of the distance map regularized network on cross-dataset segmentation, showing as much as 41% improvement in average Dice coefficient from 0.57$\pm$0.28 to 0.80$\pm$0.13.
Left Ventricle Segmentation and Quantification from Cardiac Cine MR Images via Multi-task Learning
Sep 26, 2018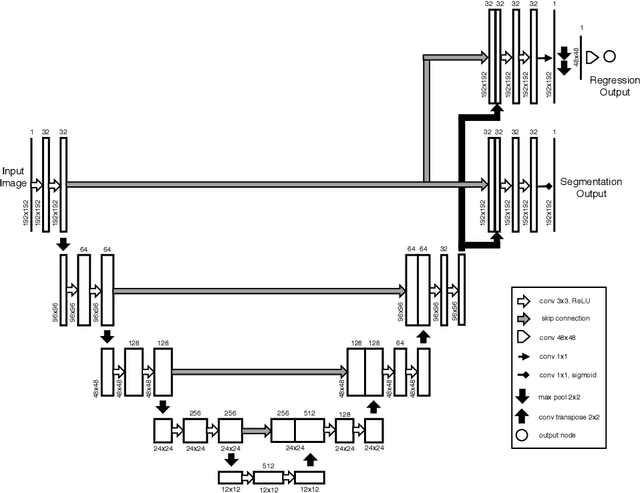
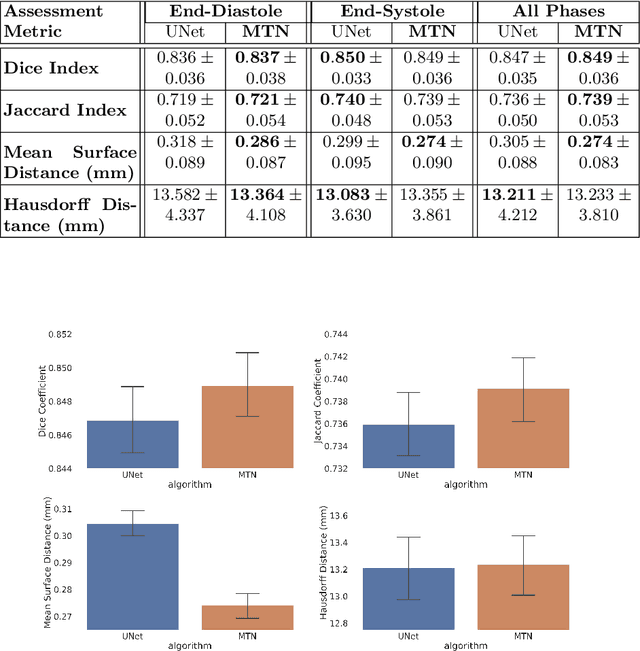
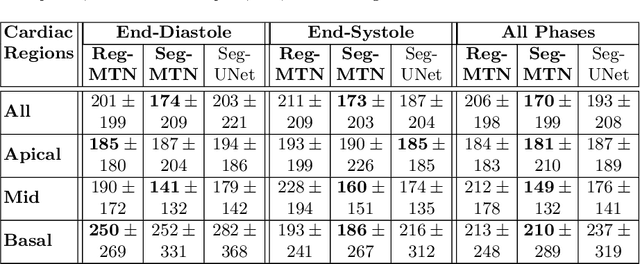
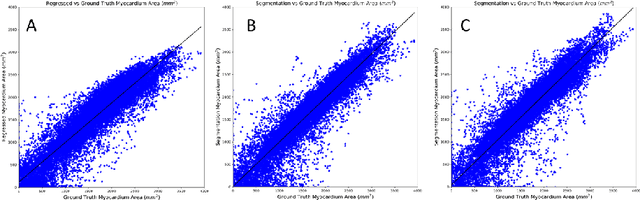
Segmentation of the left ventricle and quantification of various cardiac contractile functions is crucial for the timely diagnosis and treatment of cardiovascular diseases. Traditionally, the two tasks have been tackled independently. Here we propose a convolutional neural network based multi-task learning approach to perform both tasks simultaneously, such that, the network learns better representation of the data with improved generalization performance. Probabilistic formulation of the problem enables learning the task uncertainties during the training, which are used to automatically compute the weights for the tasks. We performed a five fold cross-validation of the myocardium segmentation obtained from the proposed multi-task network on 97 patient 4-dimensional cardiac cine-MRI datasets available through the STACOM LV segmentation challenge against the provided gold-standard myocardium segmentation, obtaining a Dice overlap of $0.849 \pm 0.036$ and mean surface distance of $0.274 \pm 0.083$ mm, while simultaneously estimating the myocardial area with mean absolute difference error of $205\pm198$ mm$^2$.
Integrating Atlas and Graph Cut Methods for LV Segmentation from Cardiac Cine MRI
Nov 03, 2016
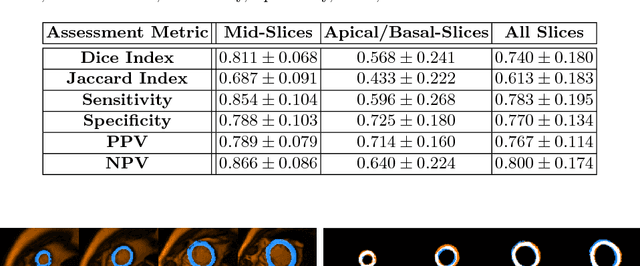

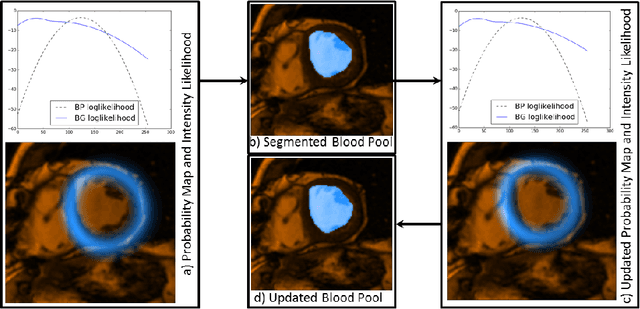
Magnetic Resonance Imaging (MRI) has evolved as a clinical standard-of-care imaging modality for cardiac morphology, function assessment, and guidance of cardiac interventions. All these applications rely on accurate extraction of the myocardial tissue and blood pool from the imaging data. Here we propose a framework for left ventricle (LV) segmentation from cardiac cine-MRI. First, we segment the LV blood pool using iterative graph cuts, and subsequently use this information to segment the myocardium. We formulate the segmentation procedure as an energy minimization problem in a graph subject to the shape prior obtained by label propagation from an average atlas using affine registration. The proposed framework has been validated on 30 patient cardiac cine-MRI datasets available through the STACOM LV segmentation challenge and yielded fast, robust, and accurate segmentation results.