 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLeveraging Content and Context Cues for Low-Light Image Enhancement
Paper and Code


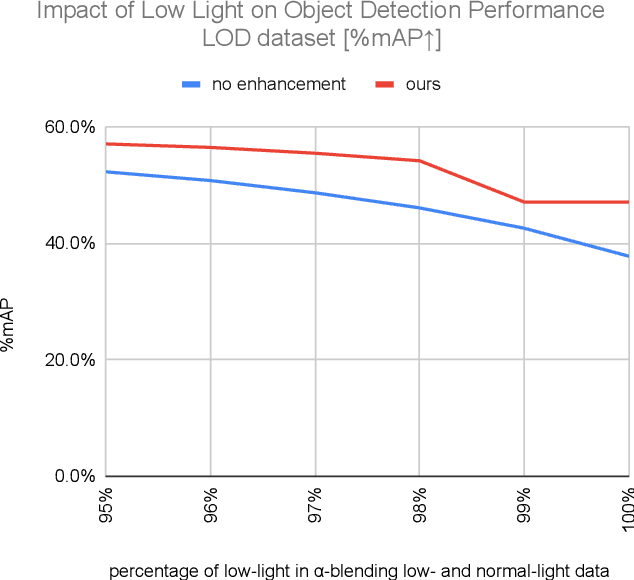

Low-light conditions have an adverse impact on machine cognition, limiting the performance of computer vision systems in real life. Since low-light data is limited and difficult to annotate, we focus on image processing to enhance low-light images and improve the performance of any downstream task model, instead of fine-tuning each of the models which can be prohibitively expensive. We propose to improve the existing zero-reference low-light enhancement by leveraging the CLIP model to capture image prior and for semantic guidance. Specifically, we propose a data augmentation strategy to learn an image prior via prompt learning, based on image sampling, to learn the image prior without any need for paired or unpaired normal-light data. Next, we propose a semantic guidance strategy that maximally takes advantage of existing low-light annotation by introducing both content and context cues about the image training patches. We experimentally show, in a qualitative study, that the proposed prior and semantic guidance help to improve the overall image contrast and hue, as well as improve background-foreground discrimination, resulting in reduced over-saturation and noise over-amplification, common in related zero-reference methods. As we target machine cognition, rather than rely on assuming the correlation between human perception and downstream task performance, we conduct and present an ablation study and comparison with related zero-reference methods in terms of task-based performance across many low-light datasets, including image classification, object and face detection, showing the effectiveness of our proposed method.