 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVirtual Multiplex Staining for Histological Images using a Marker-wise Conditioned Diffusion Model
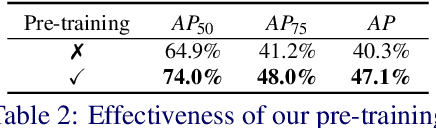
Aug 20, 2025Multiplex imaging is revolutionizing pathology by enabling the simultaneous visualization of multiple biomarkers within tissue samples, providing molecular-level insights that traditional hematoxylin and eosin (H&E) staining cannot provide. However, the complexity and cost of multiplex data acquisition have hindered its widespread adoption. Additionally, most existing large repositories of H&E images lack corresponding multiplex images, limiting opportunities for multimodal analysis. To address these challenges, we leverage recent advances in latent diffusion models (LDMs), which excel at modeling complex data distributions utilizing their powerful priors for fine-tuning to a target domain. In this paper, we introduce a novel framework for virtual multiplex staining that utilizes pretrained LDM parameters to generate multiplex images from H&E images using a conditional diffusion model. Our approach enables marker-by-marker generation by conditioning the diffusion model on each marker, while sharing the same architecture across all markers. To tackle the challenge of varying pixel value distributions across different marker stains and to improve inference speed, we fine-tune the model for single-step sampling, enhancing both color contrast fidelity and inference efficiency through pixel-level loss functions. We validate our framework on two publicly available datasets, notably demonstrating its effectiveness in generating up to 18 different marker types with improved accuracy, a substantial increase over the 2-3 marker types achieved in previous approaches. This validation highlights the potential of our framework, pioneering virtual multiplex staining. Finally, this paper bridges the gap between H&E and multiplex imaging, potentially enabling retrospective studies and large-scale analyses of existing H&E image repositories.
GenISP: Neural ISP for Low-Light Machine Cognition
May 07, 2022
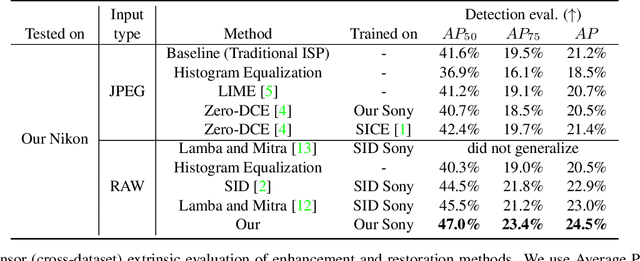


Object detection in low-light conditions remains a challenging but important problem with many practical implications. Some recent works show that, in low-light conditions, object detectors using raw image data are more robust than detectors using image data processed by a traditional ISP pipeline. To improve detection performance in low-light conditions, one can fine-tune the detector to use raw image data or use a dedicated low-light neural pipeline trained with paired low- and normal-light data to restore and enhance the image. However, different camera sensors have different spectral sensitivity and learning-based models using raw images process data in the sensor-specific color space. Thus, once trained, they do not guarantee generalization to other camera sensors. We propose to improve generalization to unseen camera sensors by implementing a minimal neural ISP pipeline for machine cognition, named GenISP, that explicitly incorporates Color Space Transformation to a device-independent color space. We also propose a two-stage color processing implemented by two image-to-parameter modules that take down-sized image as input and regress global color correction parameters. Moreover, we propose to train our proposed GenISP under the guidance of a pre-trained object detector and avoid making assumptions about perceptual quality of the image, but rather optimize the image representation for machine cognition. At the inference stage, GenISP can be paired with any object detector. We perform extensive experiments to compare our method to other low-light image restoration and enhancement methods in an extrinsic task-based evaluation and validate that GenISP can generalize to unseen sensors and object detectors. Finally, we contribute a low-light dataset of 7K raw images annotated with 46K bounding boxes for task-based benchmarking of future low-light image restoration and object detection.
NOD: Taking a Closer Look at Detection under Extreme Low-Light Conditions with Night Object Detection Dataset
Oct 20, 2021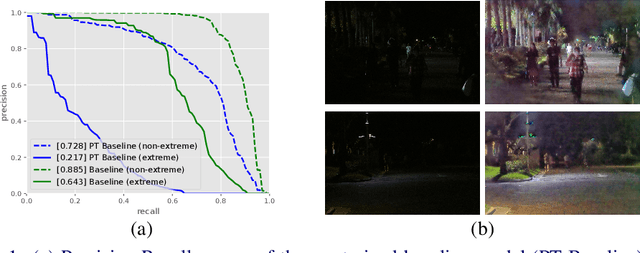
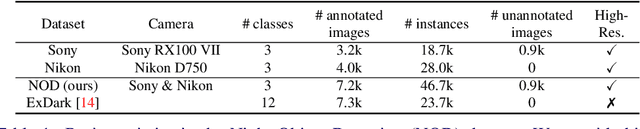
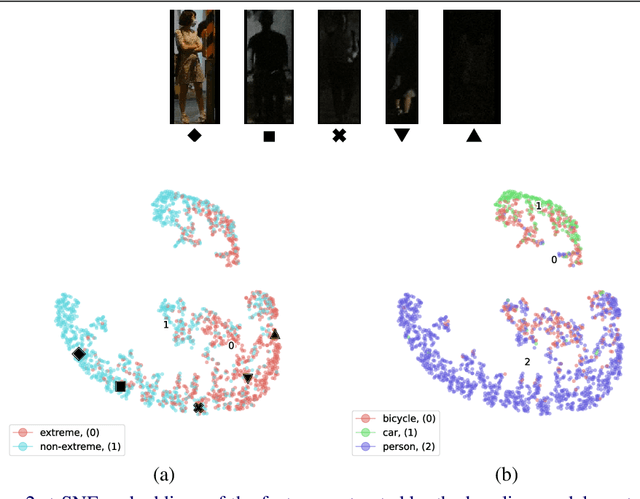
Recent work indicates that, besides being a challenge in producing perceptually pleasing images, low light proves more difficult for machine cognition than previously thought. In our work, we take a closer look at object detection in low light. First, to support the development and evaluation of new methods in this domain, we present a high-quality large-scale Night Object Detection (NOD) dataset showing dynamic scenes captured on the streets at night. Next, we directly link the lighting conditions to perceptual difficulty and identify what makes low light problematic for machine cognition. Accordingly, we provide instance-level annotation for a subset of the dataset for an in-depth evaluation of future methods. We also present an analysis of the baseline model performance to highlight opportunities for future research and show that low light is a non-trivial problem that requires special attention from the researchers. Further, to address the issues caused by low light, we propose to incorporate an image enhancement module into the object detection framework and two novel data augmentation techniques. Our image enhancement module is trained under the guidance of the object detector to learn image representation optimal for machine cognition rather than for the human visual system. Finally, experimental results confirm that the proposed method shows consistent improvement of the performance on low-light datasets.
Scope2Screen: Focus+Context Techniques for Pathology Tumor Assessment in Multivariate Image Data
Oct 10, 2021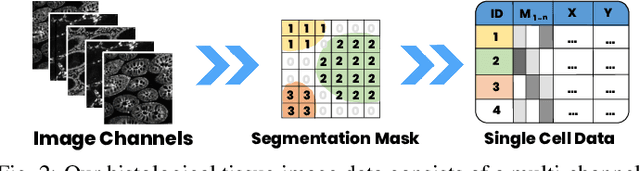

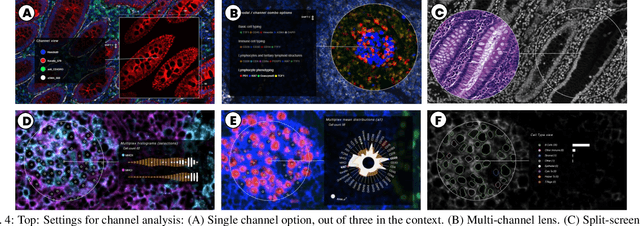
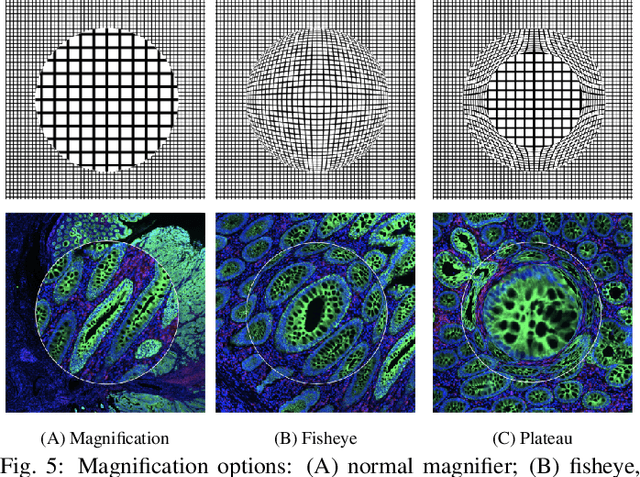
Inspection of tissues using a light microscope is the primary method of diagnosing many diseases, notably cancer. Highly multiplexed tissue imaging builds on this foundation, enabling the collection of up to 60 channels of molecular information plus cell and tissue morphology using antibody staining. This provides unique insight into disease biology and promises to help with the design of patient-specific therapies. However, a substantial gap remains with respect to visualizing the resulting multivariate image data and effectively supporting pathology workflows in digital environments on screen. We, therefore, developed Scope2Screen, a scalable software system for focus+context exploration and annotation of whole-slide, high-plex, tissue images. Our approach scales to analyzing 100GB images of 10^9 or more pixels per channel, containing millions of cells. A multidisciplinary team of visualization experts, microscopists, and pathologists identified key image exploration and annotation tasks involving finding, magnifying, quantifying, and organizing ROIs in an intuitive and cohesive manner. Building on a scope2screen metaphor, we present interactive lensing techniques that operate at single-cell and tissue levels. Lenses are equipped with task-specific functionality and descriptive statistics, making it possible to analyze image features, cell types, and spatial arrangements (neighborhoods) across image channels and scales. A fast sliding-window search guides users to regions similar to those under the lens; these regions can be analyzed and considered either separately or as part of a larger image collection. A novel snapshot method enables linked lens configurations and image statistics to be saved, restored, and shared. We validate our designs with domain experts and apply Scope2Screen in two case studies involving lung and colorectal cancers to discover cancer-relevant image features.
MITI Minimum Information guidelines for highly multiplexed tissue images
Aug 21, 2021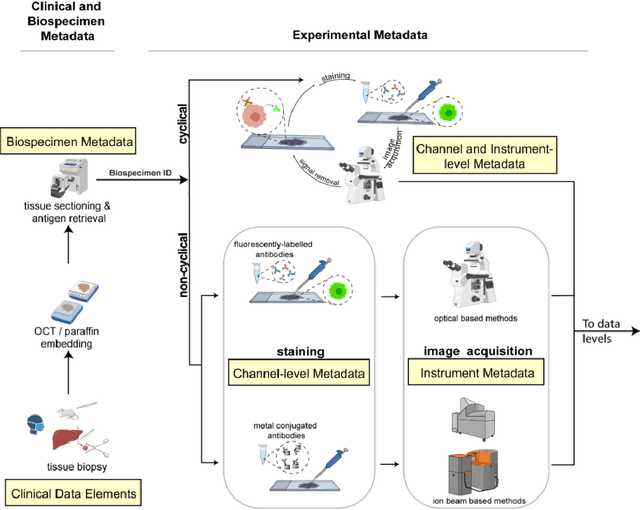
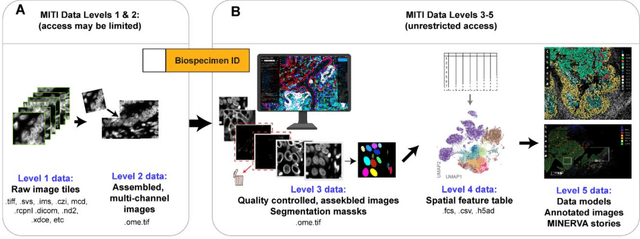
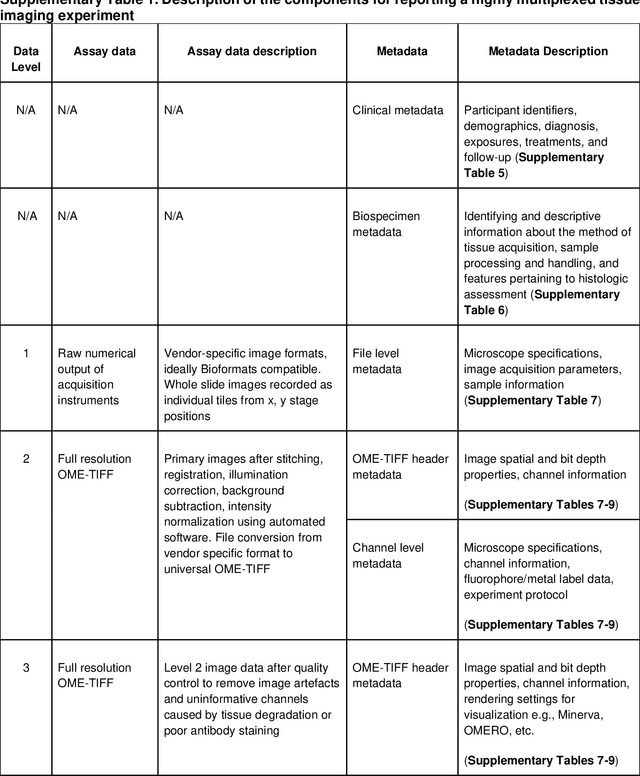
The imminent release of atlases combining highly multiplexed tissue imaging with single cell sequencing and other omics data from human tissues and tumors creates an urgent need for data and metadata standards compliant with emerging and traditional approaches to histology. We describe the development of a Minimum Information about highly multiplexed Tissue Imaging (MITI) standard that draws on best practices from genomics and microscopy of cultured cells and model organisms.
Raw Image Deblurring
Dec 08, 2020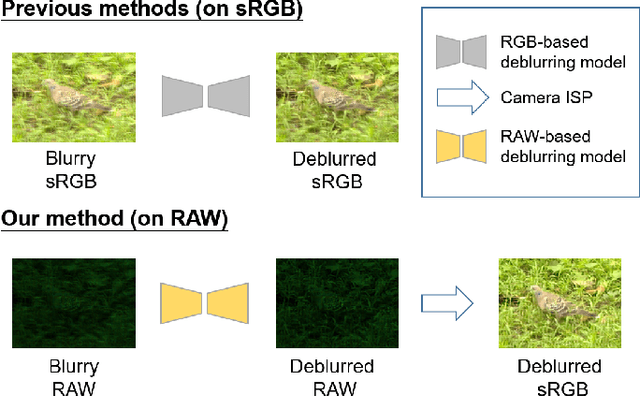



Deep learning-based blind image deblurring plays an essential role in solving image blur since all existing kernels are limited in modeling the real world blur. Thus far, researchers focus on powerful models to handle the deblurring problem and achieve decent results. For this work, in a new aspect, we discover the great opportunity for image enhancement (e.g., deblurring) directly from RAW images and investigate novel neural network structures benefiting RAW-based learning. However, to the best of our knowledge, there is no available RAW image deblurring dataset. Therefore, we built a new dataset containing both RAW images and processed sRGB images and design a new model to utilize the unique characteristics of RAW images. The proposed deblurring model, trained solely from RAW images, achieves the state-of-art performance and outweighs those trained on processed sRGB images. Furthermore, with fine-tuning, the proposed model, trained on our new dataset, can generalize to other sensors. Additionally, by a series of experiments, we demonstrate that existing deblurring models can also be improved by training on the RAW images in our new dataset. Ultimately, we show a new venue for further opportunities based on the devised novel raw-based deblurring method and the brand-new Deblur-RAW dataset.
xCos: An Explainable Cosine Metric for Face Verification Task
Mar 11, 2020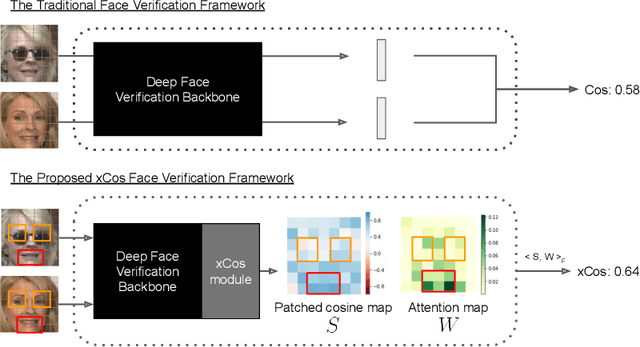
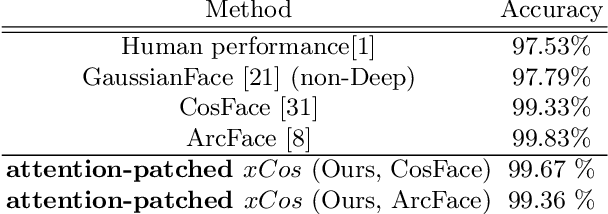
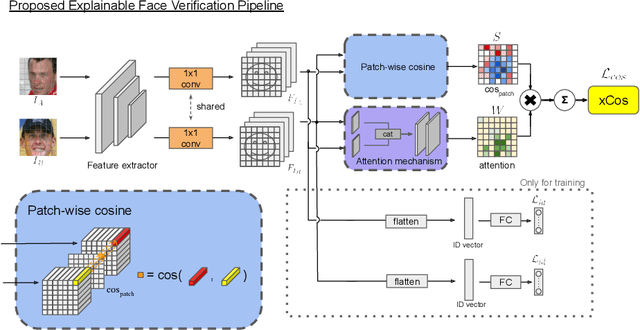
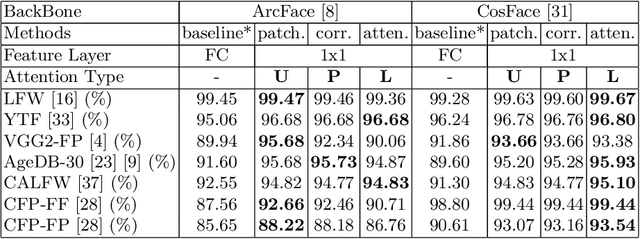
We study the XAI (explainable AI) on the face recognition task, particularly the face verification here. Face verification is a crucial task in recent days and it has been deployed to plenty of applications, such as access control, surveillance, and automatic personal log-on for mobile devices. With the increasing amount of data, deep convolutional neural networks can achieve very high accuracy for the face verification task. Beyond exceptional performances, deep face verification models need more interpretability so that we can trust the results they generate. In this paper, we propose a novel similarity metric, called explainable cosine ($xCos$), that comes with a learnable module that can be plugged into most of the verification models to provide meaningful explanations. With the help of $xCos$, we can see which parts of the 2 input faces are similar, where the model pays its attention to, and how the local similarities are weighted to form the output $xCos$ score. We demonstrate the effectiveness of our proposed method on LFW and various competitive benchmarks, resulting in not only providing novel and desiring model interpretability for face verification but also ensuring the accuracy as plugging into existing face recognition models.