 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCrossDTR: Cross-view and Depth-guided Transformers for 3D Object Detection
Oct 12, 2022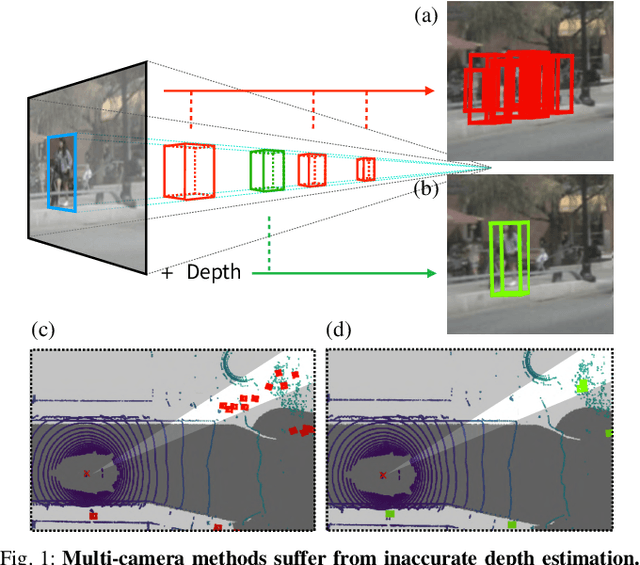
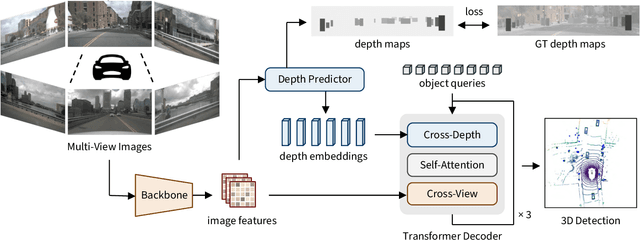
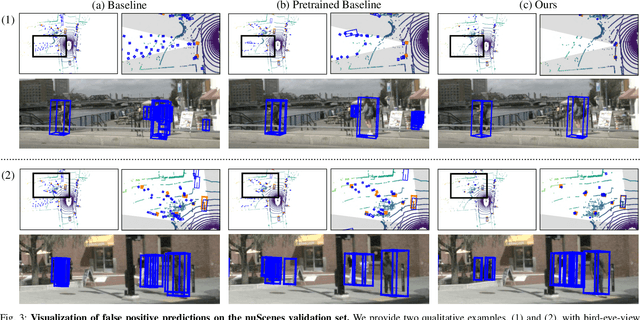
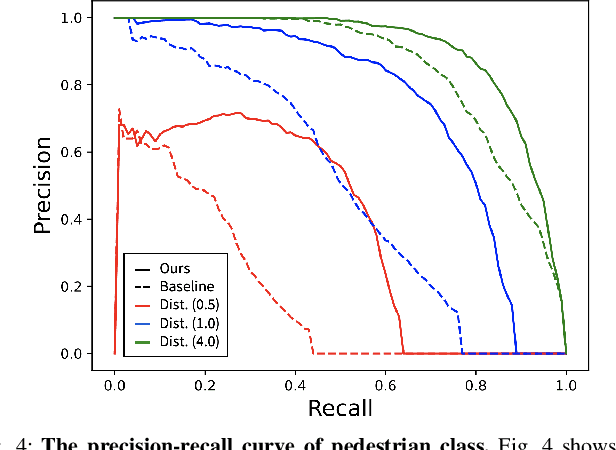
To achieve accurate 3D object detection at a low cost for autonomous driving, many multi-camera methods have been proposed and solved the occlusion problem of monocular approaches. However, due to the lack of accurate estimated depth, existing multi-camera methods often generate multiple bounding boxes along a ray of depth direction for difficult small objects such as pedestrians, resulting in an extremely low recall. Furthermore, directly applying depth prediction modules to existing multi-camera methods, generally composed of large network architectures, cannot meet the real-time requirements of self-driving applications. To address these issues, we propose Cross-view and Depth-guided Transformers for 3D Object Detection, CrossDTR. First, our lightweight depth predictor is designed to produce precise object-wise sparse depth maps and low-dimensional depth embeddings without extra depth datasets during supervision. Second, a cross-view depth-guided transformer is developed to fuse the depth embeddings as well as image features from cameras of different views and generate 3D bounding boxes. Extensive experiments demonstrated that our method hugely surpassed existing multi-camera methods by 10 percent in pedestrian detection and about 3 percent in overall mAP and NDS metrics. Also, computational analyses showed that our method is 5 times faster than prior approaches. Our codes will be made publicly available at https://github.com/sty61010/CrossDTR.
Large Margin Mechanism and Pseudo Query Set on Cross-Domain Few-Shot Learning
May 19, 2020
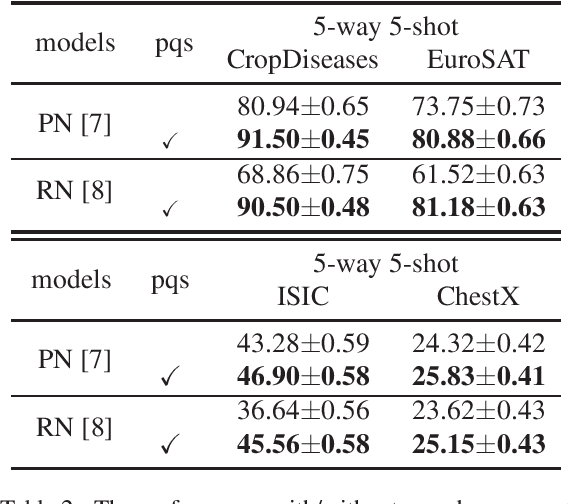

In recent years, few-shot learning problems have received a lot of attention. While methods in most previous works were trained and tested on datasets in one single domain, cross-domain few-shot learning is a brand-new branch of few-shot learning problems, where models handle datasets in different domains between training and testing phases. In this paper, to solve the problem that the model is pre-trained (meta-trained) on a single dataset while fine-tuned on datasets in four different domains, including common objects, satellite images, and medical images, we propose a novel large margin fine-tuning method (LMM-PQS), which generates pseudo query images from support images and fine-tunes the feature extraction modules with a large margin mechanism inspired by methods in face recognition. According to the experiment results, LMM-PQS surpasses the baseline models by a significant margin and demonstrates that our approach is robust and can easily adapt pre-trained models to new domains with few data.
xCos: An Explainable Cosine Metric for Face Verification Task
Mar 11, 2020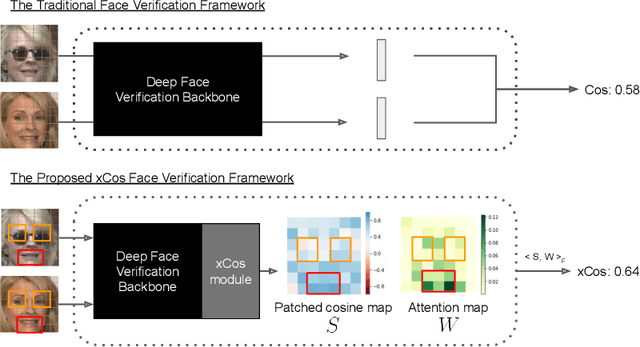
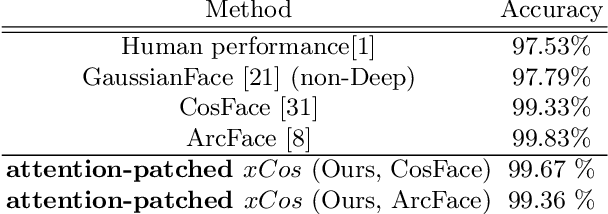
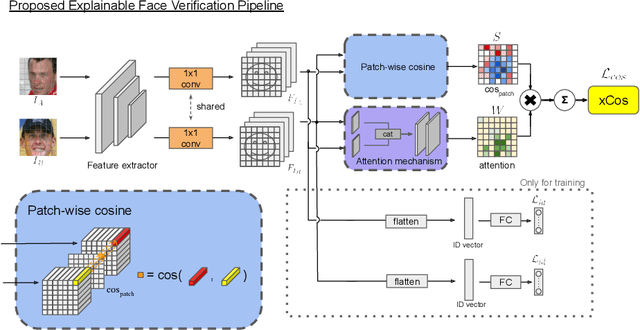
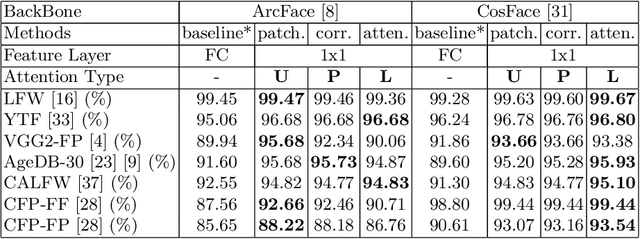
We study the XAI (explainable AI) on the face recognition task, particularly the face verification here. Face verification is a crucial task in recent days and it has been deployed to plenty of applications, such as access control, surveillance, and automatic personal log-on for mobile devices. With the increasing amount of data, deep convolutional neural networks can achieve very high accuracy for the face verification task. Beyond exceptional performances, deep face verification models need more interpretability so that we can trust the results they generate. In this paper, we propose a novel similarity metric, called explainable cosine ($xCos$), that comes with a learnable module that can be plugged into most of the verification models to provide meaningful explanations. With the help of $xCos$, we can see which parts of the 2 input faces are similar, where the model pays its attention to, and how the local similarities are weighted to form the output $xCos$ score. We demonstrate the effectiveness of our proposed method on LFW and various competitive benchmarks, resulting in not only providing novel and desiring model interpretability for face verification but also ensuring the accuracy as plugging into existing face recognition models.