 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBEVANet: Bilateral Efficient Visual Attention Network for Real-Time Semantic Segmentation
Aug 10, 2025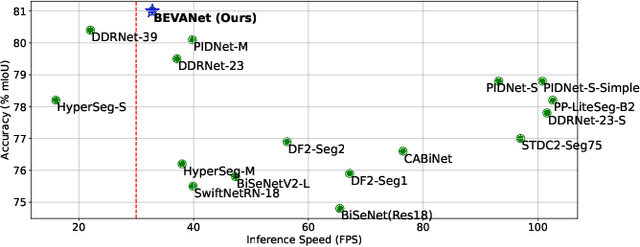



Real-time semantic segmentation presents the dual challenge of designing efficient architectures that capture large receptive fields for semantic understanding while also refining detailed contours. Vision transformers model long-range dependencies effectively but incur high computational cost. To address these challenges, we introduce the Large Kernel Attention (LKA) mechanism. Our proposed Bilateral Efficient Visual Attention Network (BEVANet) expands the receptive field to capture contextual information and extracts visual and structural features using Sparse Decomposed Large Separable Kernel Attentions (SDLSKA). The Comprehensive Kernel Selection (CKS) mechanism dynamically adapts the receptive field to further enhance performance. Furthermore, the Deep Large Kernel Pyramid Pooling Module (DLKPPM) enriches contextual features by synergistically combining dilated convolutions and large kernel attention. The bilateral architecture facilitates frequent branch communication, and the Boundary Guided Adaptive Fusion (BGAF) module enhances boundary delineation by integrating spatial and semantic features under boundary guidance. BEVANet achieves real-time segmentation at 33 FPS, yielding 79.3% mIoU without pretraining and 81.0% mIoU on Cityscapes after ImageNet pretraining, demonstrating state-of-the-art performance. The code and model is available at https://github.com/maomao0819/BEVANet.
* Copyright 2025 IEEE. Personal use of this material is permitted. Permission from IEEE must be obtained for all other uses, in any current or future media, including reprinting/republishing this material for advertising or promotional purposes, creating new collective works, for resale or redistribution to servers or lists, or reuse of any copyrighted component of this work in other works
ReDAL: Region-based and Diversity-aware Active Learning for Point Cloud Semantic Segmentation
Aug 07, 2021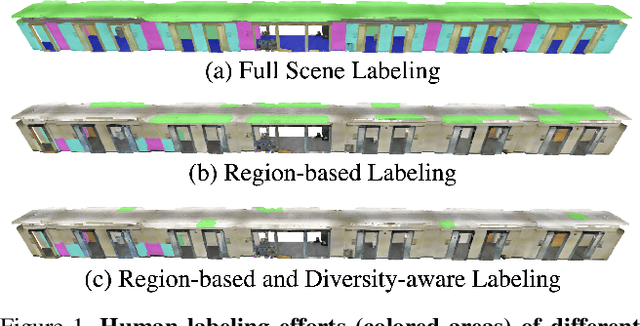



Despite the success of deep learning on supervised point cloud semantic segmentation, obtaining large-scale point-by-point manual annotations is still a significant challenge. To reduce the huge annotation burden, we propose a Region-based and Diversity-aware Active Learning (ReDAL), a general framework for many deep learning approaches, aiming to automatically select only informative and diverse sub-scene regions for label acquisition. Observing that only a small portion of annotated regions are sufficient for 3D scene understanding with deep learning, we use softmax entropy, color discontinuity, and structural complexity to measure the information of sub-scene regions. A diversity-aware selection algorithm is also developed to avoid redundant annotations resulting from selecting informative but similar regions in a querying batch. Extensive experiments show that our method highly outperforms previous active learning strategies, and we achieve the performance of 90% fully supervised learning, while less than 15% and 5% annotations are required on S3DIS and SemanticKITTI datasets, respectively.
Large Margin Mechanism and Pseudo Query Set on Cross-Domain Few-Shot Learning
May 19, 2020
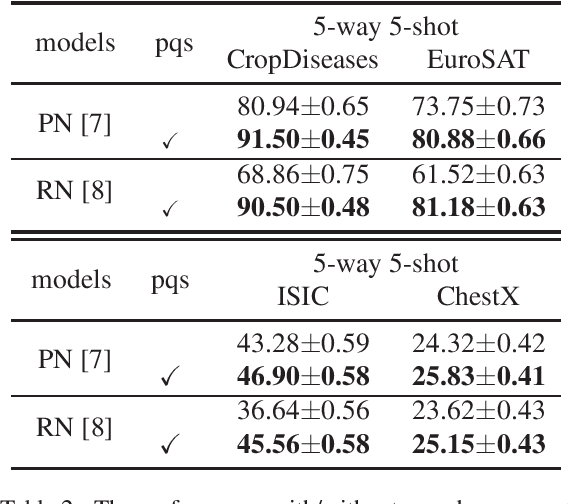

In recent years, few-shot learning problems have received a lot of attention. While methods in most previous works were trained and tested on datasets in one single domain, cross-domain few-shot learning is a brand-new branch of few-shot learning problems, where models handle datasets in different domains between training and testing phases. In this paper, to solve the problem that the model is pre-trained (meta-trained) on a single dataset while fine-tuned on datasets in four different domains, including common objects, satellite images, and medical images, we propose a novel large margin fine-tuning method (LMM-PQS), which generates pseudo query images from support images and fine-tunes the feature extraction modules with a large margin mechanism inspired by methods in face recognition. According to the experiment results, LMM-PQS surpasses the baseline models by a significant margin and demonstrates that our approach is robust and can easily adapt pre-trained models to new domains with few data.