 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Fine-Grained Visual Understanding for Video Question Answering via Decoupling Spatial-Temporal Modeling
Oct 08, 2022

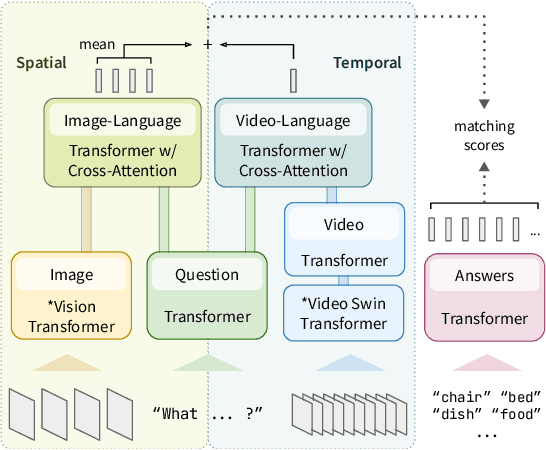

While recent large-scale video-language pre-training made great progress in video question answering, the design of spatial modeling of video-language models is less fine-grained than that of image-language models; existing practices of temporal modeling also suffer from weak and noisy alignment between modalities. To learn fine-grained visual understanding, we decouple spatial-temporal modeling and propose a hybrid pipeline, Decoupled Spatial-Temporal Encoders, integrating an image- and a video-language encoder. The former encodes spatial semantics from larger but sparsely sampled frames independently of time, while the latter models temporal dynamics at lower spatial but higher temporal resolution. To help the video-language model learn temporal relations for video QA, we propose a novel pre-training objective, Temporal Referring Modeling, which requires the model to identify temporal positions of events in video sequences. Extensive experiments demonstrate that our model outperforms previous work pre-trained on orders of magnitude larger datasets.
TrUMAn: Trope Understanding in Movies and Animations
Aug 21, 2021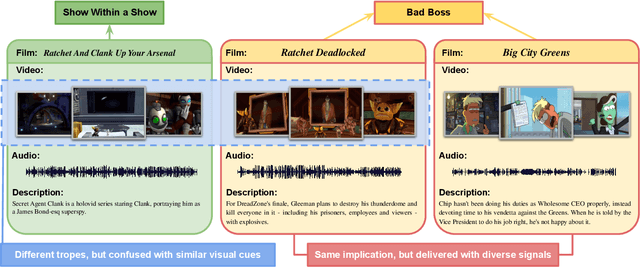
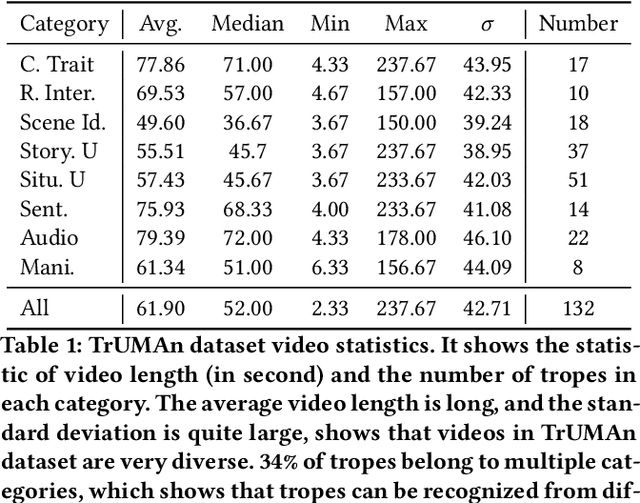
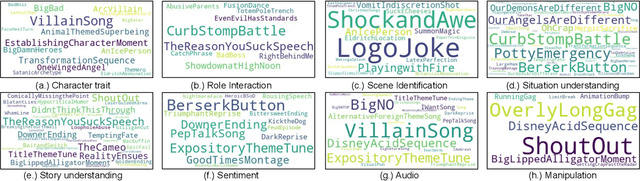

Understanding and comprehending video content is crucial for many real-world applications such as search and recommendation systems. While recent progress of deep learning has boosted performance on various tasks using visual cues, deep cognition to reason intentions, motivation, or causality remains challenging. Existing datasets that aim to examine video reasoning capability focus on visual signals such as actions, objects, relations, or could be answered utilizing text bias. Observing this, we propose a novel task, along with a new dataset: Trope Understanding in Movies and Animations (TrUMAn), with 2423 videos associated with 132 tropes, intending to evaluate and develop learning systems beyond visual signals. Tropes are frequently used storytelling devices for creative works. By coping with the trope understanding task and enabling the deep cognition skills of machines, data mining applications and algorithms could be taken to the next level. To tackle the challenging TrUMAn dataset, we present a Trope Understanding and Storytelling (TrUSt) with a new Conceptual Storyteller module, which guides the video encoder by performing video storytelling on a latent space. Experimental results demonstrate that state-of-the-art learning systems on existing tasks reach only 12.01% of accuracy with raw input signals. Also, even in the oracle case with human-annotated descriptions, BERT contextual embedding achieves at most 28% of accuracy. Our proposed TrUSt boosts the model performance and reaches 13.94% performance. We also provide detailed analysis to pave the way for future research. TrUMAn is publicly available at:https://www.cmlab.csie.ntu.edu.tw/project/trope
Large Margin Mechanism and Pseudo Query Set on Cross-Domain Few-Shot Learning
May 19, 2020
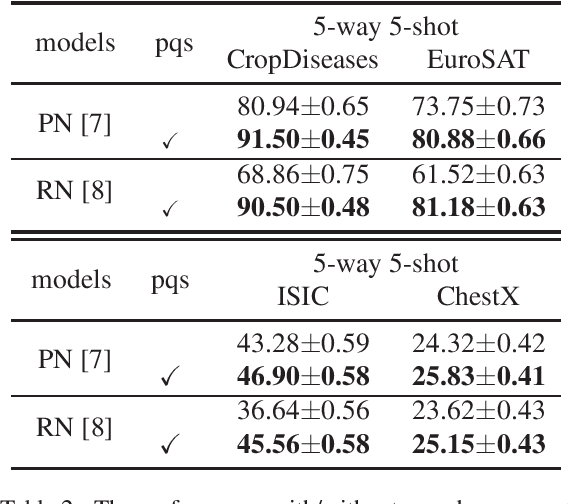

In recent years, few-shot learning problems have received a lot of attention. While methods in most previous works were trained and tested on datasets in one single domain, cross-domain few-shot learning is a brand-new branch of few-shot learning problems, where models handle datasets in different domains between training and testing phases. In this paper, to solve the problem that the model is pre-trained (meta-trained) on a single dataset while fine-tuned on datasets in four different domains, including common objects, satellite images, and medical images, we propose a novel large margin fine-tuning method (LMM-PQS), which generates pseudo query images from support images and fine-tunes the feature extraction modules with a large margin mechanism inspired by methods in face recognition. According to the experiment results, LMM-PQS surpasses the baseline models by a significant margin and demonstrates that our approach is robust and can easily adapt pre-trained models to new domains with few data.