 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTrUMAn: Trope Understanding in Movies and Animations
Aug 21, 2021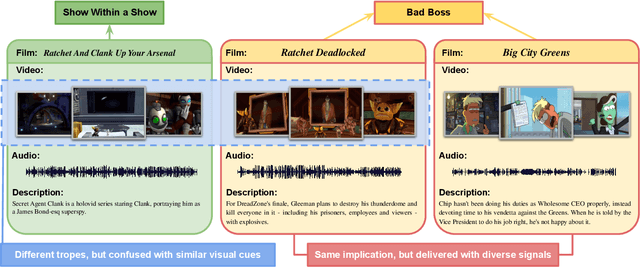
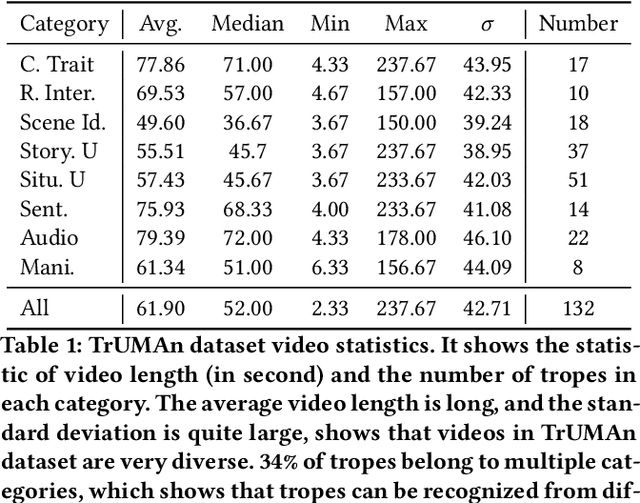
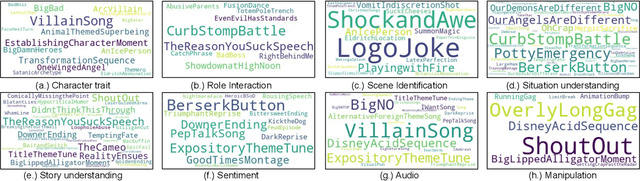

Understanding and comprehending video content is crucial for many real-world applications such as search and recommendation systems. While recent progress of deep learning has boosted performance on various tasks using visual cues, deep cognition to reason intentions, motivation, or causality remains challenging. Existing datasets that aim to examine video reasoning capability focus on visual signals such as actions, objects, relations, or could be answered utilizing text bias. Observing this, we propose a novel task, along with a new dataset: Trope Understanding in Movies and Animations (TrUMAn), with 2423 videos associated with 132 tropes, intending to evaluate and develop learning systems beyond visual signals. Tropes are frequently used storytelling devices for creative works. By coping with the trope understanding task and enabling the deep cognition skills of machines, data mining applications and algorithms could be taken to the next level. To tackle the challenging TrUMAn dataset, we present a Trope Understanding and Storytelling (TrUSt) with a new Conceptual Storyteller module, which guides the video encoder by performing video storytelling on a latent space. Experimental results demonstrate that state-of-the-art learning systems on existing tasks reach only 12.01% of accuracy with raw input signals. Also, even in the oracle case with human-annotated descriptions, BERT contextual embedding achieves at most 28% of accuracy. Our proposed TrUSt boosts the model performance and reaches 13.94% performance. We also provide detailed analysis to pave the way for future research. TrUMAn is publicly available at:https://www.cmlab.csie.ntu.edu.tw/project/trope
End-to-End Video Question-Answer Generation with Generator-Pretester Network
Jan 05, 2021

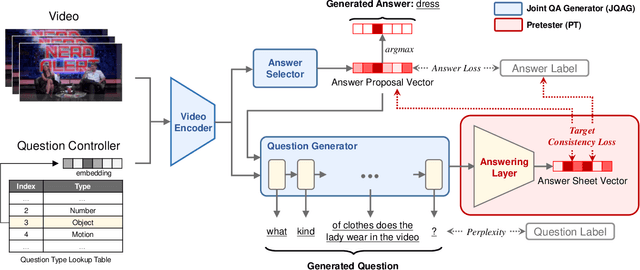

We study a novel task, Video Question-Answer Generation (VQAG), for challenging Video Question Answering (Video QA) task in multimedia. Due to expensive data annotation costs, many widely used, large-scale Video QA datasets such as Video-QA, MSVD-QA and MSRVTT-QA are automatically annotated using Caption Question Generation (CapQG) which inputs captions instead of the video itself. As captions neither fully represent a video, nor are they always practically available, it is crucial to generate question-answer pairs based on a video via Video Question-Answer Generation (VQAG). Existing video-to-text (V2T) approaches, despite taking a video as the input, only generate a question alone. In this work, we propose a novel model Generator-Pretester Network that focuses on two components: (1) The Joint Question-Answer Generator (JQAG) which generates a question with its corresponding answer to allow Video Question "Answering" training. (2) The Pretester (PT) verifies a generated question by trying to answer it and checks the pretested answer with both the model's proposed answer and the ground truth answer. We evaluate our system with the only two available large-scale human-annotated Video QA datasets and achieves state-of-the-art question generation performances. Furthermore, using our generated QA pairs only on the Video QA task, we can surpass some supervised baselines. We apply our generated questions to Video QA applications and surpasses some supervised baselines using generated questions only. As a pre-training strategy, we outperform both CapQG and transfer learning approaches when employing semi-supervised (20%) or fully supervised learning with annotated data. These experimental results suggest the novel perspectives for Video QA training.