 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSituation and Behavior Understanding by Trope Detection on Films
Jan 19, 2021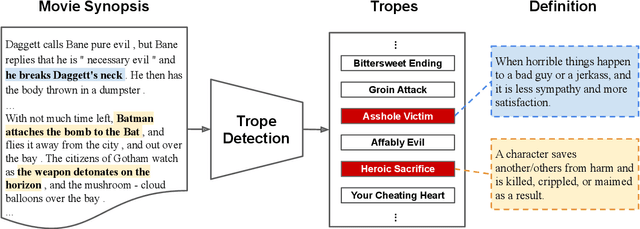
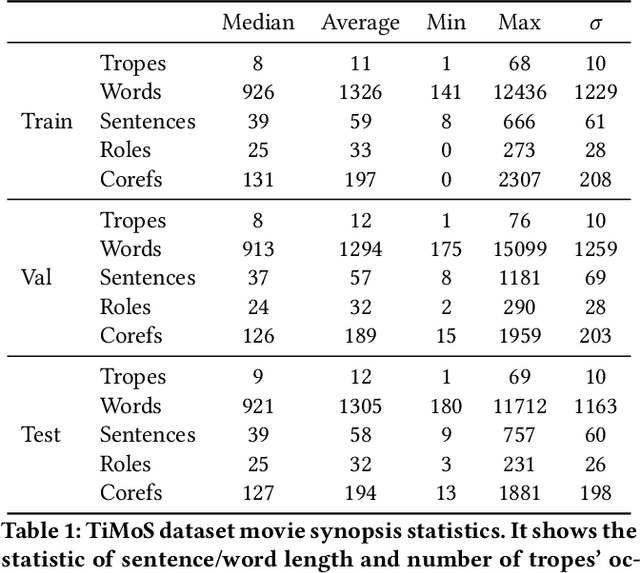
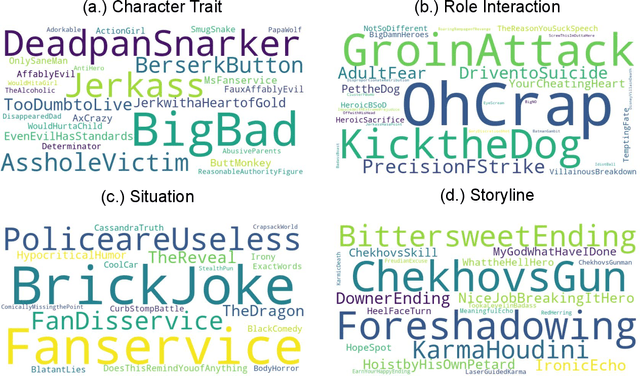
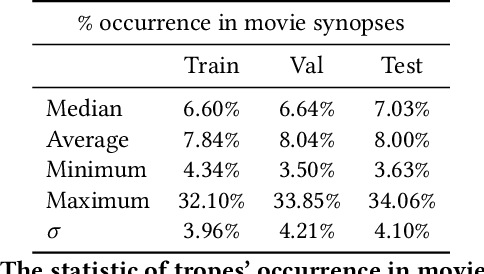
The human ability of deep cognitive skills are crucial for the development of various real-world applications that process diverse and abundant user generated input. While recent progress of deep learning and natural language processing have enabled learning system to reach human performance on some benchmarks requiring shallow semantics, such human ability still remains challenging for even modern contextual embedding models, as pointed out by many recent studies. Existing machine comprehension datasets assume sentence-level input, lack of casual or motivational inferences, or could be answered with question-answer bias. Here, we present a challenging novel task, trope detection on films, in an effort to create a situation and behavior understanding for machines. Tropes are storytelling devices that are frequently used as ingredients in recipes for creative works. Comparing to existing movie tag prediction tasks, tropes are more sophisticated as they can vary widely, from a moral concept to a series of circumstances, and embedded with motivations and cause-and-effects. We introduce a new dataset, Tropes in Movie Synopses (TiMoS), with 5623 movie synopses and 95 different tropes collecting from a Wikipedia-style database, TVTropes. We present a multi-stream comprehension network (MulCom) leveraging multi-level attention of words, sentences, and role relations. Experimental result demonstrates that modern models including BERT contextual embedding, movie tag prediction systems, and relational networks, perform at most 37% of human performance (23.97/64.87) in terms of F1 score. Our MulCom outperforms all modern baselines, by 1.5 to 5.0 F1 score and 1.5 to 3.0 mean of average precision (mAP) score. We also provide a detailed analysis and human evaluation to pave ways for future research.
End-to-End Video Question-Answer Generation with Generator-Pretester Network
Jan 05, 2021

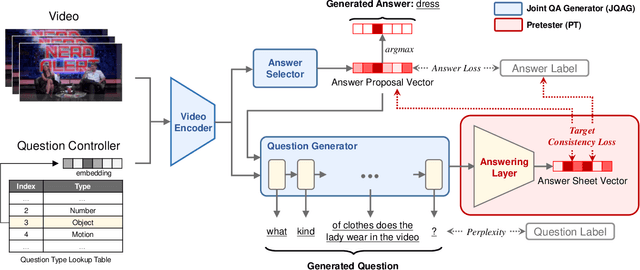

We study a novel task, Video Question-Answer Generation (VQAG), for challenging Video Question Answering (Video QA) task in multimedia. Due to expensive data annotation costs, many widely used, large-scale Video QA datasets such as Video-QA, MSVD-QA and MSRVTT-QA are automatically annotated using Caption Question Generation (CapQG) which inputs captions instead of the video itself. As captions neither fully represent a video, nor are they always practically available, it is crucial to generate question-answer pairs based on a video via Video Question-Answer Generation (VQAG). Existing video-to-text (V2T) approaches, despite taking a video as the input, only generate a question alone. In this work, we propose a novel model Generator-Pretester Network that focuses on two components: (1) The Joint Question-Answer Generator (JQAG) which generates a question with its corresponding answer to allow Video Question "Answering" training. (2) The Pretester (PT) verifies a generated question by trying to answer it and checks the pretested answer with both the model's proposed answer and the ground truth answer. We evaluate our system with the only two available large-scale human-annotated Video QA datasets and achieves state-of-the-art question generation performances. Furthermore, using our generated QA pairs only on the Video QA task, we can surpass some supervised baselines. We apply our generated questions to Video QA applications and surpasses some supervised baselines using generated questions only. As a pre-training strategy, we outperform both CapQG and transfer learning approaches when employing semi-supervised (20%) or fully supervised learning with annotated data. These experimental results suggest the novel perspectives for Video QA training.
Video Question Generation via Cross-Modal Self-Attention Networks Learning
Jul 05, 2019
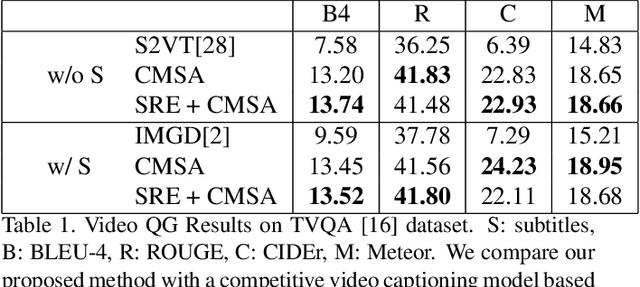
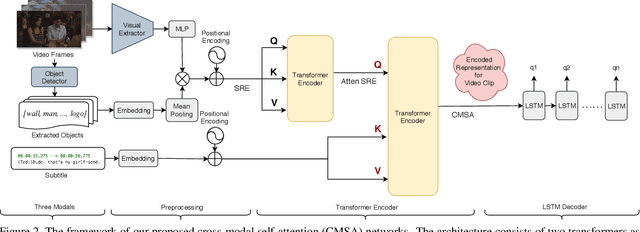
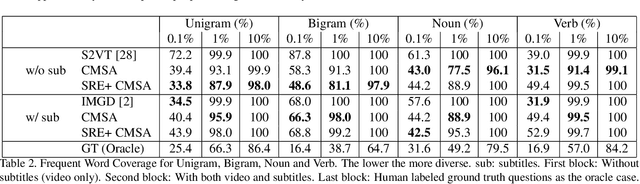
Video Question Answering (Video QA) is a critical and challenging task in multimedia comprehension. While deep learning based models are extremely capable of representing and understanding videos, these models heavily rely on massive data, which is expensive to label. In this paper, we introduce a novel task for automatically generating questions given a sequence of video frames and the corresponding subtitles from a clip of video to reduce the huge annotation cost. Learning to ask a question based on a video requires the model to comprehend the rich semantics in the scene and the interplay between the vision and the language. To address this, we propose a novel cross-modal self-attention (CMSA) network to aggregate the diverse features from video frames and subtitles. Excitingly, we demonstrate that our proposed model can improve the (strong) baseline from 0.0738 to 0.1374 in BLEU4 score -- more than 0.063 improvement (i.e., 85\% relatively). Most of all, We arguably pave a novel path toward solving the challenging Video QA task and provide detailed analysis which ushers the avenues for future investigations.