 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnd-to-End Video Question-Answer Generation with Generator-Pretester Network
Paper and Code


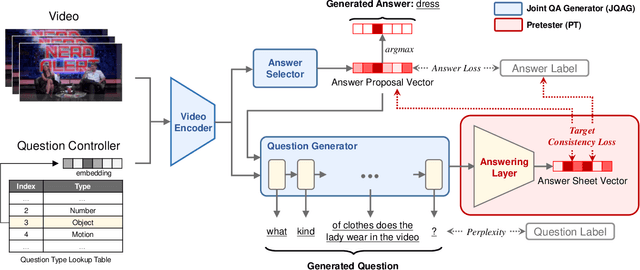

We study a novel task, Video Question-Answer Generation (VQAG), for challenging Video Question Answering (Video QA) task in multimedia. Due to expensive data annotation costs, many widely used, large-scale Video QA datasets such as Video-QA, MSVD-QA and MSRVTT-QA are automatically annotated using Caption Question Generation (CapQG) which inputs captions instead of the video itself. As captions neither fully represent a video, nor are they always practically available, it is crucial to generate question-answer pairs based on a video via Video Question-Answer Generation (VQAG). Existing video-to-text (V2T) approaches, despite taking a video as the input, only generate a question alone. In this work, we propose a novel model Generator-Pretester Network that focuses on two components: (1) The Joint Question-Answer Generator (JQAG) which generates a question with its corresponding answer to allow Video Question "Answering" training. (2) The Pretester (PT) verifies a generated question by trying to answer it and checks the pretested answer with both the model's proposed answer and the ground truth answer. We evaluate our system with the only two available large-scale human-annotated Video QA datasets and achieves state-of-the-art question generation performances. Furthermore, using our generated QA pairs only on the Video QA task, we can surpass some supervised baselines. We apply our generated questions to Video QA applications and surpasses some supervised baselines using generated questions only. As a pre-training strategy, we outperform both CapQG and transfer learning approaches when employing semi-supervised (20%) or fully supervised learning with annotated data. These experimental results suggest the novel perspectives for Video QA training.