 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeToken-Weighted Multi-Target Learning for Generative Recommenders with Curriculum Learning
Jan 25, 2026Generative recommender systems have recently attracted attention by formulating next-item prediction as an autoregressive sequence generation task. However, most existing methods optimize standard next-token likelihood and implicitly treat all tokens as equally informative, which is misaligned with semantic-ID-based generation. Accordingly, we propose two complementary information-gain-based token-weighting strategies tailored to generative recommendation with semantic IDs. Front-Greater Weighting captures conditional semantic information gain by prioritizing early tokens that most effectively reduce candidate-item uncertainty given their prefixes and encode coarse semantics. Frequency Weighting models marginal information gain under long-tailed item and token distributions, upweighting rare tokens to counteract popularity bias. Beyond individual strategies, we introduce a multi-target learning framework with curriculum learning that jointly optimizes the two token-weighted objectives alongside standard likelihood, enabling stable optimization and adaptive emphasis across training stages. Extensive experiments on benchmark datasets show that our method consistently outperforms strong baselines and existing token-weighting approaches, with improved robustness, strong generalization across different semantic-ID constructions, and substantial gains on both head and tail items. Code is available at https://github.com/CHIUWEINING/Token-Weighted-Multi-Target-Learning-for-Generative-Recommenders-with-Curriculum-Learning.
Doc2Query++: Topic-Coverage based Document Expansion and its Application to Dense Retrieval via Dual-Index Fusion
Oct 10, 2025
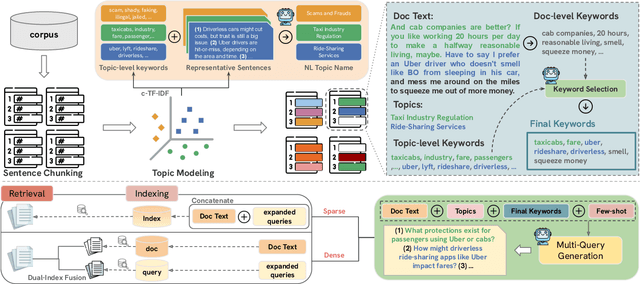
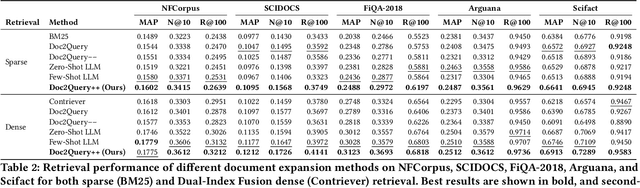
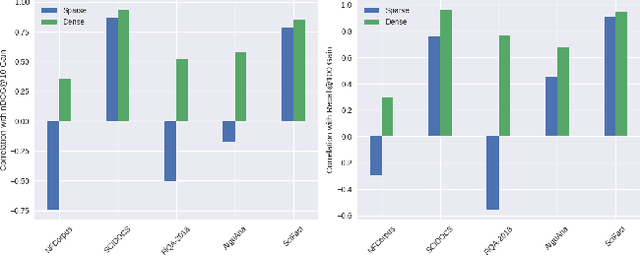
Document expansion (DE) via query generation tackles vocabulary mismatch in sparse retrieval, yet faces limitations: uncontrolled generation producing hallucinated or redundant queries with low diversity; poor generalization from in-domain training (e.g., MS MARCO) to out-of-domain data like BEIR; and noise from concatenation harming dense retrieval. While Large Language Models (LLMs) enable cross-domain query generation, basic prompting lacks control, and taxonomy-based methods rely on domain-specific structures, limiting applicability. To address these challenges, we introduce Doc2Query++, a DE framework that structures query generation by first inferring a document's latent topics via unsupervised topic modeling for cross-domain applicability, then using hybrid keyword selection to create a diverse and relevant keyword set per document. This guides LLM not only to leverage keywords, which ensure comprehensive topic representation, but also to reduce redundancy through diverse, relevant terms. To prevent noise from query appending in dense retrieval, we propose Dual-Index Fusion strategy that isolates text and query signals, boosting performance in dense settings. Extensive experiments show Doc2Query++ significantly outperforms state-of-the-art baselines, achieving substantial gains in MAP, nDCG@10 and Recall@100 across diverse datasets on both sparse and dense retrieval.
Augment or Not? A Comparative Study of Pure and Augmented Large Language Model Recommenders
May 29, 2025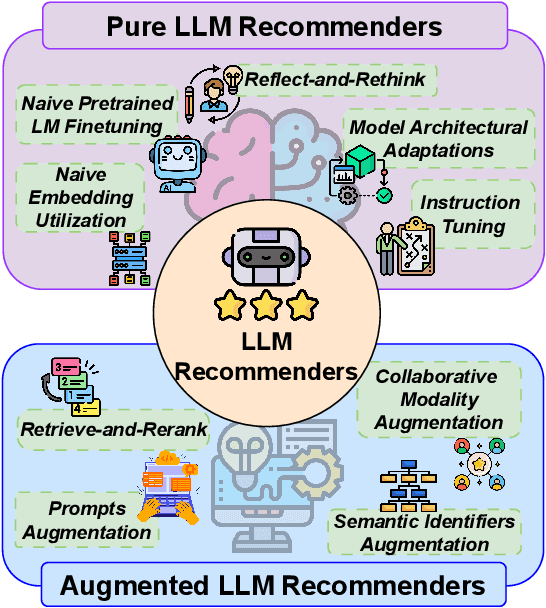
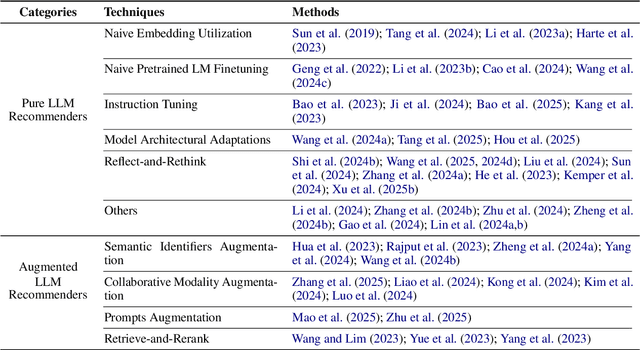
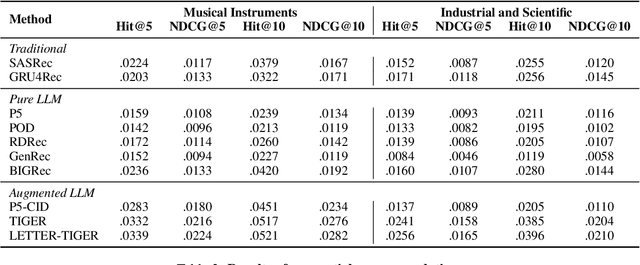
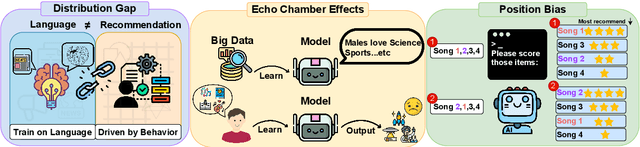
Large language models (LLMs) have introduced new paradigms for recommender systems by enabling richer semantic understanding and incorporating implicit world knowledge. In this study, we propose a systematic taxonomy that classifies existing approaches into two categories: (1) Pure LLM Recommenders, which rely solely on LLMs, and (2) Augmented LLM Recommenders, which integrate additional non-LLM techniques to enhance performance. This taxonomy provides a novel lens through which to examine the evolving landscape of LLM-based recommendation. To support fair comparison, we introduce a unified evaluation platform that benchmarks representative models under consistent experimental settings, highlighting key design choices that impact effectiveness. We conclude by discussing open challenges and outlining promising directions for future research. This work offers both a comprehensive overview and practical guidance for advancing next-generation LLM-powered recommender.
Not All LLM-Generated Data Are Equal: Rethinking Data Weighting in Text Classification
Oct 28, 2024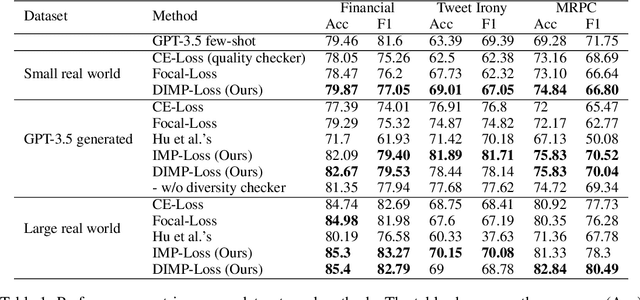
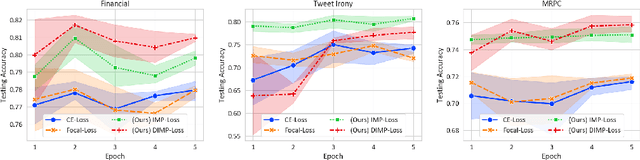
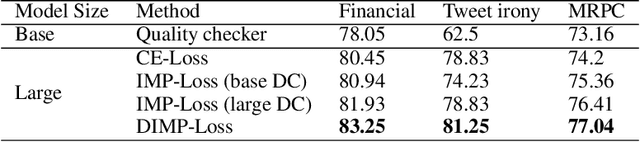
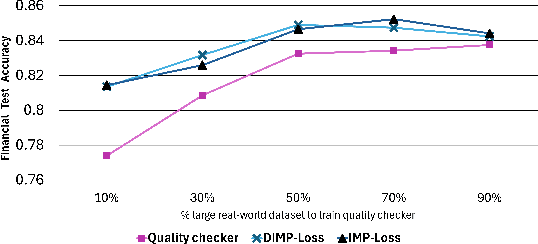
Synthetic data augmentation via large language models (LLMs) allows researchers to leverage additional training data, thus enhancing the performance of downstream tasks, especially when real-world data is scarce. However, the generated data can deviate from the real-world data, and this misalignment can bring deficient outcomes while applying the trained model to applications. Therefore, we proposed efficient weighted-loss approaches to align synthetic data with real-world distribution by emphasizing high-quality and diversified data generated by LLMs with using merely a little real-world data. We empirically assessed the effectiveness of our method on multiple text classification tasks, and the results showed leveraging our approaches on a BERT-level model robustly outperformed standard cross-entropy and other data weighting approaches, providing potential solutions to effectively leveraging synthetic data from any suitable data generator for model training.
Legal Documents Drafting with Fine-Tuned Pre-Trained Large Language Model
Jun 06, 2024With the development of large-scale Language Models (LLM), fine-tuning pre-trained LLM has become a mainstream paradigm for solving downstream tasks of natural language processing. However, training a language model in the legal field requires a large number of legal documents so that the language model can learn legal terminology and the particularity of the format of legal documents. The typical NLP approaches usually rely on many manually annotated data sets for training. However, in the legal field application, it is difficult to obtain a large number of manually annotated data sets, which restricts the typical method applied to the task of drafting legal documents. The experimental results of this paper show that not only can we leverage a large number of annotation-free legal documents without Chinese word segmentation to fine-tune a large-scale language model, but more importantly, it can fine-tune a pre-trained LLM on the local computer to achieve the generating legal document drafts task, and at the same time achieve the protection of information privacy and to improve information security issues.
Improving One-class Recommendation with Multi-tasking on Various Preference Intensities
Jan 18, 2024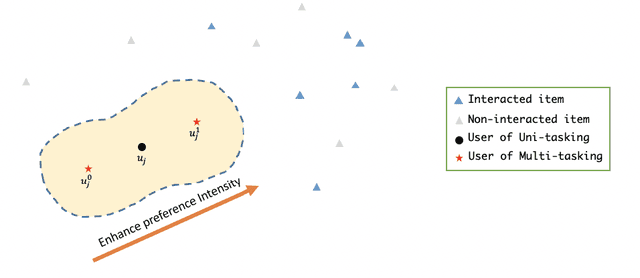
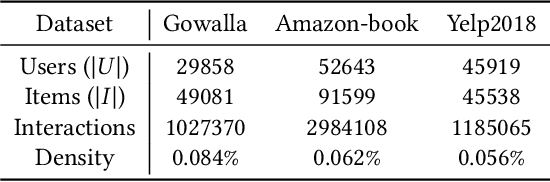
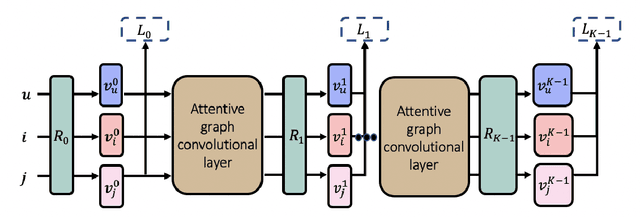
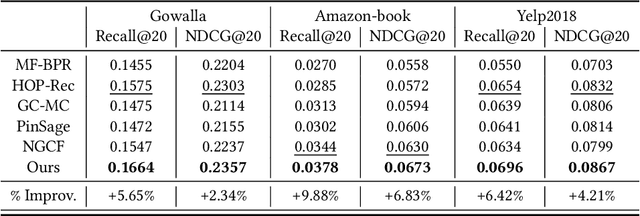
In the one-class recommendation problem, it's required to make recommendations basing on users' implicit feedback, which is inferred from their action and inaction. Existing works obtain representations of users and items by encoding positive and negative interactions observed from training data. However, these efforts assume that all positive signals from implicit feedback reflect a fixed preference intensity, which is not realistic. Consequently, representations learned with these methods usually fail to capture informative entity features that reflect various preference intensities. In this paper, we propose a multi-tasking framework taking various preference intensities of each signal from implicit feedback into consideration. Representations of entities are required to satisfy the objective of each subtask simultaneously, making them more robust and generalizable. Furthermore, we incorporate attentive graph convolutional layers to explore high-order relationships in the user-item bipartite graph and dynamically capture the latent tendencies of users toward the items they interact with. Experimental results show that our method performs better than state-of-the-art methods by a large margin on three large-scale real-world benchmark datasets.
* RecSys 2020 (ACM Conference on Recommender Systems 2020)
Learning Unsupervised Semantic Document Representation for Fine-grained Aspect-based Sentiment Analysis
Jan 11, 2024



Document representation is the core of many NLP tasks on machine understanding. A general representation learned in an unsupervised manner reserves generality and can be used for various applications. In practice, sentiment analysis (SA) has been a challenging task that is regarded to be deeply semantic-related and is often used to assess general representations. Existing methods on unsupervised document representation learning can be separated into two families: sequential ones, which explicitly take the ordering of words into consideration, and non-sequential ones, which do not explicitly do so. However, both of them suffer from their own weaknesses. In this paper, we propose a model that overcomes difficulties encountered by both families of methods. Experiments show that our model outperforms state-of-the-art methods on popular SA datasets and a fine-grained aspect-based SA by a large margin.
* International ACM SIGIR Conference 2019
Addressing Long-Horizon Tasks by Integrating Program Synthesis and State Machines
Nov 27, 2023Deep reinforcement learning excels in various domains but lacks generalizability and interoperability. Programmatic RL methods (Trivedi et al., 2021; Liu et al., 2023) reformulate solving RL tasks as synthesizing interpretable programs that can be executed in the environments. Despite encouraging results, these methods are limited to short-horizon tasks. On the other hand, representing RL policies using state machines (Inala et al., 2020) can inductively generalize to long-horizon tasks; however, it struggles to scale up to acquire diverse and complex behaviors. This work proposes Program Machine Policies (POMPs), which bridge the advantages of programmatic RL and state machine policies, allowing for the representation of complex behaviors and the address of long-term tasks. Specifically, we introduce a method that can retrieve a set of effective, diverse, compatible programs. Then, we use these programs as modes of a state machine and learn a transition function to transition among mode programs, allowing for capturing long-horizon repetitive behaviors. Our proposed framework outperforms programmatic RL and deep RL baselines on various tasks and demonstrates the ability to generalize to even longer horizons without any fine-tuning inductively. Ablation studies justify the effectiveness of our proposed search algorithm for retrieving a set of programs as modes.
printf: Preference Modeling Based on User Reviews with Item Images and Textual Information via Graph Learning
Aug 19, 2023Nowadays, modern recommender systems usually leverage textual and visual contents as auxiliary information to predict user preference. For textual information, review texts are one of the most popular contents to model user behaviors. Nevertheless, reviews usually lose their shine when it comes to top-N recommender systems because those that solely utilize textual reviews as features struggle to adequately capture the interaction relationships between users and items. For visual one, it is usually modeled with naive convolutional networks and also hard to capture high-order relationships between users and items. Moreover, previous works did not collaboratively use both texts and images in a proper way. In this paper, we propose printf, preference modeling based on user reviews with item images and textual information via graph learning, to address the above challenges. Specifically, the dimension-based attention mechanism directs relations between user reviews and interacted items, allowing each dimension to contribute different importance weights to derive user representations. Extensive experiments are conducted on three publicly available datasets. The experimental results demonstrate that our proposed printf consistently outperforms baseline methods with the relative improvements for NDCG@5 of 26.80%, 48.65%, and 25.74% on Amazon-Grocery, Amazon-Tools, and Amazon-Electronics datasets, respectively. The in-depth analysis also indicates the dimensions of review representations definitely have different topics and aspects, assisting the validity of our model design.
Attentive Graph-based Text-aware Preference Modeling for Top-N Recommendation
May 22, 2023



Textual data are commonly used as auxiliary information for modeling user preference nowadays. While many prior works utilize user reviews for rating prediction, few focus on top-N recommendation, and even few try to incorporate item textual contents such as title and description. Though delivering promising performance for rating prediction, we empirically find that many review-based models cannot perform comparably well on top-N recommendation. Also, user reviews are not available in some recommendation scenarios, while item textual contents are more prevalent. On the other hand, recent graph convolutional network (GCN) based models demonstrate state-of-the-art performance for top-N recommendation. Thus, in this work, we aim to further improve top-N recommendation by effectively modeling both item textual content and high-order connectivity in user-item graph. We propose a new model named Attentive Graph-based Text-aware Recommendation Model (AGTM). Extensive experiments are provided to justify the rationality and effectiveness of our model design.