 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePEFA: Parameter-Free Adapters for Large-scale Embedding-based Retrieval Models
Dec 06, 2023

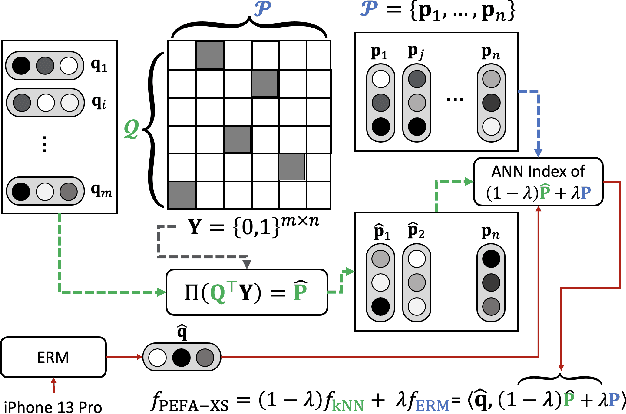

Embedding-based Retrieval Models (ERMs) have emerged as a promising framework for large-scale text retrieval problems due to powerful large language models. Nevertheless, fine-tuning ERMs to reach state-of-the-art results can be expensive due to the extreme scale of data as well as the complexity of multi-stages pipelines (e.g., pre-training, fine-tuning, distillation). In this work, we propose the PEFA framework, namely ParamEter-Free Adapters, for fast tuning of ERMs without any backward pass in the optimization. At index building stage, PEFA equips the ERM with a non-parametric k-nearest neighbor (kNN) component. At inference stage, PEFA performs a convex combination of two scoring functions, one from the ERM and the other from the kNN. Based on the neighborhood definition, PEFA framework induces two realizations, namely PEFA-XL (i.e., extra large) using double ANN indices and PEFA-XS (i.e., extra small) using a single ANN index. Empirically, PEFA achieves significant improvement on two retrieval applications. For document retrieval, regarding Recall@100 metric, PEFA improves not only pre-trained ERMs on Trivia-QA by an average of 13.2%, but also fine-tuned ERMs on NQ-320K by an average of 5.5%, respectively. For product search, PEFA improves the Recall@100 of the fine-tuned ERMs by an average of 5.3% and 14.5%, for PEFA-XS and PEFA-XL, respectively. Our code is available at https://github.com/amzn/pecos/tree/mainline/examples/pefa-wsdm24.
MinPrompt: Graph-based Minimal Prompt Data Augmentation for Few-shot Question Answering
Oct 08, 2023



Few-shot question answering (QA) aims at achieving satisfactory results on machine question answering when only a few training samples are available. Recent advances mostly rely on the power of pre-trained large language models (LLMs) and fine-tuning in specific settings. Although the pre-training stage has already equipped LLMs with powerful reasoning capabilities, LLMs still need to be fine-tuned to adapt to specific domains to achieve the best results. In this paper, we propose to select the most informative data for fine-tuning, thereby improving the efficiency of the fine-tuning process with comparative or even better accuracy on the open-domain QA task. We present MinPrompt, a minimal data augmentation framework for open-domain QA based on an approximate graph algorithm and unsupervised question generation. We transform the raw text into a graph structure to build connections between different factual sentences, then apply graph algorithms to identify the minimal set of sentences needed to cover the most information in the raw text. We then generate QA pairs based on the identified sentence subset and train the model on the selected sentences to obtain the final model. Empirical results on several benchmark datasets and theoretical analysis show that MinPrompt is able to achieve comparable or better results than baselines with a high degree of efficiency, bringing improvements in F-1 scores by up to 27.5%.
printf: Preference Modeling Based on User Reviews with Item Images and Textual Information via Graph Learning
Aug 19, 2023Nowadays, modern recommender systems usually leverage textual and visual contents as auxiliary information to predict user preference. For textual information, review texts are one of the most popular contents to model user behaviors. Nevertheless, reviews usually lose their shine when it comes to top-N recommender systems because those that solely utilize textual reviews as features struggle to adequately capture the interaction relationships between users and items. For visual one, it is usually modeled with naive convolutional networks and also hard to capture high-order relationships between users and items. Moreover, previous works did not collaboratively use both texts and images in a proper way. In this paper, we propose printf, preference modeling based on user reviews with item images and textual information via graph learning, to address the above challenges. Specifically, the dimension-based attention mechanism directs relations between user reviews and interacted items, allowing each dimension to contribute different importance weights to derive user representations. Extensive experiments are conducted on three publicly available datasets. The experimental results demonstrate that our proposed printf consistently outperforms baseline methods with the relative improvements for NDCG@5 of 26.80%, 48.65%, and 25.74% on Amazon-Grocery, Amazon-Tools, and Amazon-Electronics datasets, respectively. The in-depth analysis also indicates the dimensions of review representations definitely have different topics and aspects, assisting the validity of our model design.
Gotta: Generative Few-shot Question Answering by Prompt-based Cloze Data Augmentation
Jun 07, 2023Few-shot question answering (QA) aims at precisely discovering answers to a set of questions from context passages while only a few training samples are available. Although existing studies have made some progress and can usually achieve proper results, they suffer from understanding deep semantics for reasoning out the questions. In this paper, we develop Gotta, a Generative prOmpT-based daTa Augmentation framework to mitigate the challenge above. Inspired by the human reasoning process, we propose to integrate the cloze task to enhance few-shot QA learning. Following the recent success of prompt-tuning, we present the cloze task in the same format as the main QA task, allowing the model to learn both tasks seamlessly together to fully take advantage of the power of prompt-tuning. Extensive experiments on widely used benchmarks demonstrate that Gotta consistently outperforms competitive baselines, validating the effectiveness of our proposed prompt-tuning-based cloze task, which not only fine-tunes language models but also learns to guide reasoning in QA tasks. Further analysis shows that the prompt-based loss incorporates the auxiliary task better than the multi-task loss, highlighting the strength of prompt-tuning on the few-shot QA task.
PINA: Leveraging Side Information in eXtreme Multi-label Classification via Predicted Instance Neighborhood Aggregation
May 21, 2023The eXtreme Multi-label Classification~(XMC) problem seeks to find relevant labels from an exceptionally large label space. Most of the existing XMC learners focus on the extraction of semantic features from input query text. However, conventional XMC studies usually neglect the side information of instances and labels, which can be of use in many real-world applications such as recommendation systems and e-commerce product search. We propose Predicted Instance Neighborhood Aggregation (PINA), a data enhancement method for the general XMC problem that leverages beneficial side information. Unlike most existing XMC frameworks that treat labels and input instances as featureless indicators and independent entries, PINA extracts information from the label metadata and the correlations among training instances. Extensive experimental results demonstrate the consistent gain of PINA on various XMC tasks compared to the state-of-the-art methods: PINA offers a gain in accuracy compared to standard XR-Transformers on five public benchmark datasets. Moreover, PINA achieves a $\sim 5\%$ gain in accuracy on the largest dataset LF-AmazonTitles-1.3M. Our implementation is publicly available.
InfluencerRank: Discovering Effective Influencers via Graph Convolutional Attentive Recurrent Neural Networks
Apr 12, 2023As influencers play considerable roles in social media marketing, companies increase the budget for influencer marketing. Hiring effective influencers is crucial in social influencer marketing, but it is challenging to find the right influencers among hundreds of millions of social media users. In this paper, we propose InfluencerRank that ranks influencers by their effectiveness based on their posting behaviors and social relations over time. To represent the posting behaviors and social relations, the graph convolutional neural networks are applied to model influencers with heterogeneous networks during different historical periods. By learning the network structure with the embedded node features, InfluencerRank can derive informative representations for influencers at each period. An attentive recurrent neural network finally distinguishes highly effective influencers from other influencers by capturing the knowledge of the dynamics of influencer representations over time. Extensive experiments have been conducted on an Instagram dataset that consists of 18,397 influencers with their 2,952,075 posts published within 12 months. The experimental results demonstrate that InfluencerRank outperforms existing baseline methods. An in-depth analysis further reveals that all of our proposed features and model components are beneficial to discover effective influencers.
Uncertainty in Extreme Multi-label Classification
Oct 18, 2022
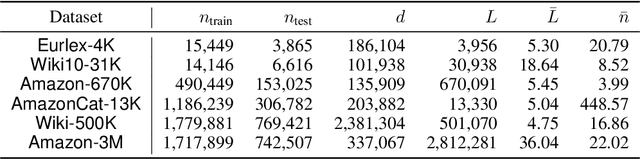
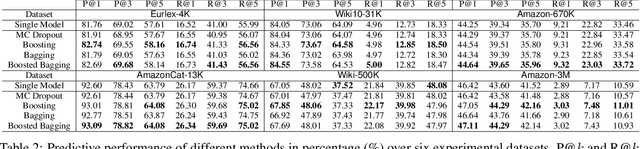
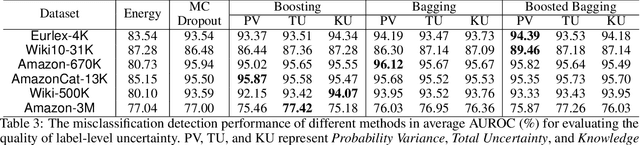
Uncertainty quantification is one of the most crucial tasks to obtain trustworthy and reliable machine learning models for decision making. However, most research in this domain has only focused on problems with small label spaces and ignored eXtreme Multi-label Classification (XMC), which is an essential task in the era of big data for web-scale machine learning applications. Moreover, enormous label spaces could also lead to noisy retrieval results and intractable computational challenges for uncertainty quantification. In this paper, we aim to investigate general uncertainty quantification approaches for tree-based XMC models with a probabilistic ensemble-based framework. In particular, we analyze label-level and instance-level uncertainty in XMC, and propose a general approximation framework based on beam search to efficiently estimate the uncertainty with a theoretical guarantee under long-tail XMC predictions. Empirical studies on six large-scale real-world datasets show that our framework not only outperforms single models in predictive performance, but also can serve as strong uncertainty-based baselines for label misclassification and out-of-distribution detection, with significant speedup. Besides, our framework can further yield better state-of-the-art results based on deep XMC models with uncertainty quantification.
Learning to Represent Human Motives for Goal-directed Web Browsing
Aug 07, 2021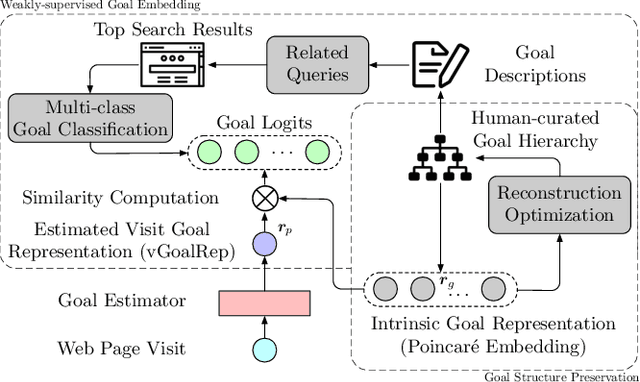
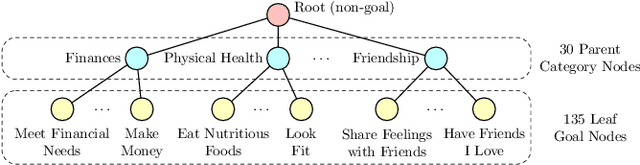
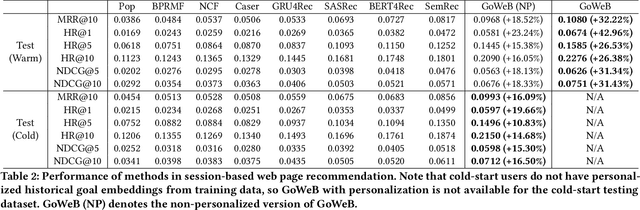
Motives or goals are recognized in psychology literature as the most fundamental drive that explains and predicts why people do what they do, including when they browse the web. Although providing enormous value, these higher-ordered goals are often unobserved, and little is known about how to leverage such goals to assist people's browsing activities. This paper proposes to take a new approach to address this problem, which is fulfilled through a novel neural framework, Goal-directed Web Browsing (GoWeB). We adopt a psychologically-sound taxonomy of higher-ordered goals and learn to build their representations in a structure-preserving manner. Then we incorporate the resulting representations for enhancing the experiences of common activities people perform on the web. Experiments on large-scale data from Microsoft Edge web browser show that GoWeB significantly outperforms competitive baselines for in-session web page recommendation, re-visitation classification, and goal-based web page grouping. A follow-up analysis further characterizes how the variety of human motives can affect the difference observed in human behavioral patterns.
Drug-Target Interaction Prediction with Graph Attention networks
Jul 10, 2021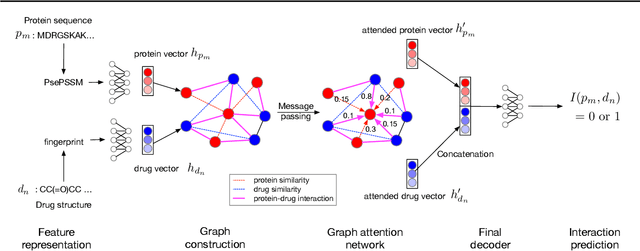
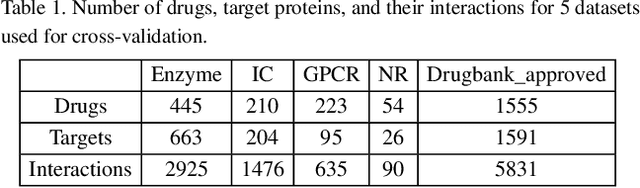
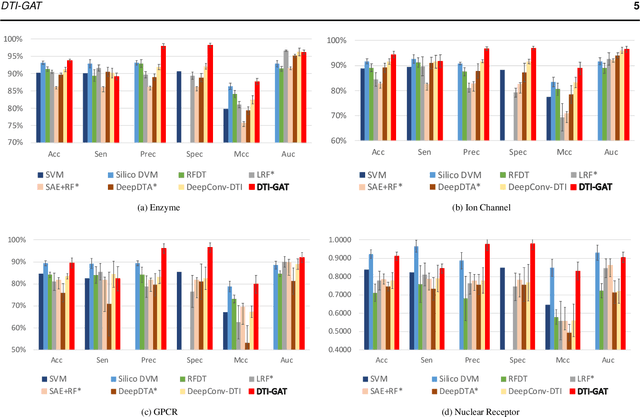
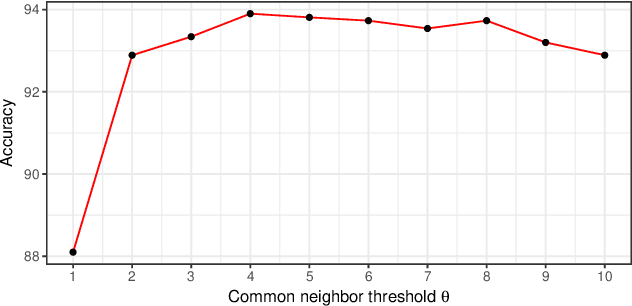
Motivation: Predicting Drug-Target Interaction (DTI) is a well-studied topic in bioinformatics due to its relevance in the fields of proteomics and pharmaceutical research. Although many machine learning methods have been successfully applied in this task, few of them aim at leveraging the inherent heterogeneous graph structure in the DTI network to address the challenge. For better learning and interpreting the DTI topological structure and the similarity, it is desirable to have methods specifically for predicting interactions from the graph structure. Results: We present an end-to-end framework, DTI-GAT (Drug-Target Interaction prediction with Graph Attention networks) for DTI predictions. DTI-GAT incorporates a deep neural network architecture that operates on graph-structured data with the attention mechanism, which leverages both the interaction patterns and the features of drug and protein sequences. DTI-GAT facilitates the interpretation of the DTI topological structure by assigning different attention weights to each node with the self-attention mechanism. Experimental evaluations show that DTI-GAT outperforms various state-of-the-art systems on the binary DTI prediction problem. Moreover, the independent study results further demonstrate that our model can be generalized better than other conventional methods. Availability: The source code and all datasets are available at https://github.com/Haiyang-W/DTI-GRAPH
Long Document Ranking with Query-Directed Sparse Transformer
Oct 23, 2020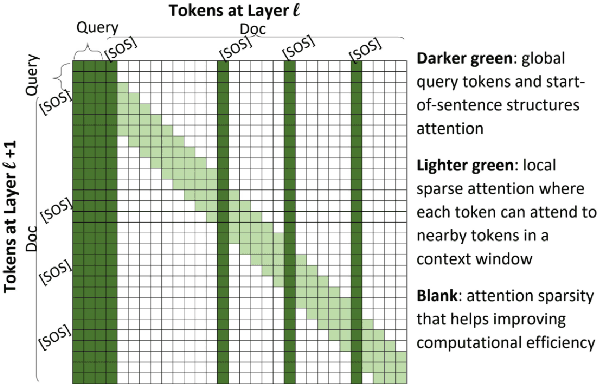
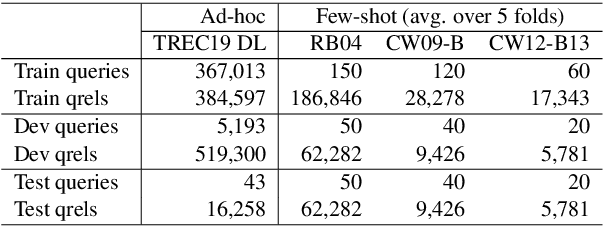
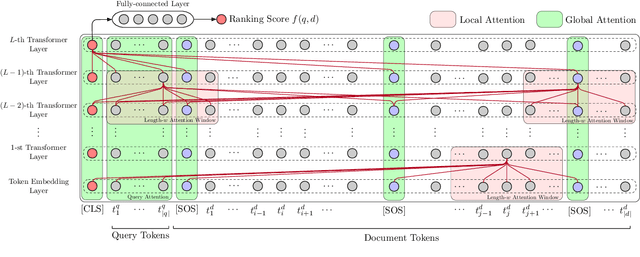

The computing cost of transformer self-attention often necessitates breaking long documents to fit in pretrained models in document ranking tasks. In this paper, we design Query-Directed Sparse attention that induces IR-axiomatic structures in transformer self-attention. Our model, QDS-Transformer, enforces the principle properties desired in ranking: local contextualization, hierarchical representation, and query-oriented proximity matching, while it also enjoys efficiency from sparsity. Experiments on one fully supervised and three few-shot TREC document ranking benchmarks demonstrate the consistent and robust advantage of QDS-Transformer over previous approaches, as they either retrofit long documents into BERT or use sparse attention without emphasizing IR principles. We further quantify the computing complexity and demonstrates that our sparse attention with TVM implementation is twice more efficient than the fully-connected self-attention. All source codes, trained model, and predictions of this work are available at https://github.com/hallogameboy/QDS-Transformer.