 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInterpretable User Satisfaction Estimation for Conversational Systems with Large Language Models
Mar 19, 2024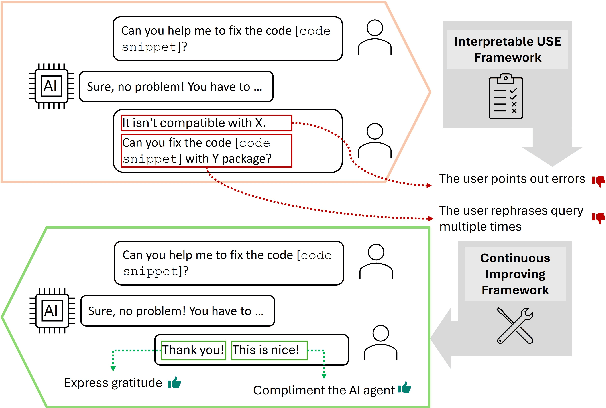
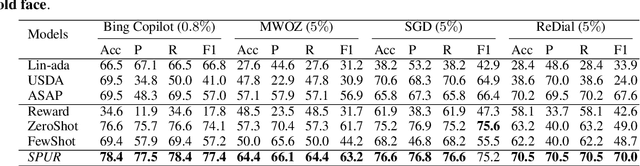
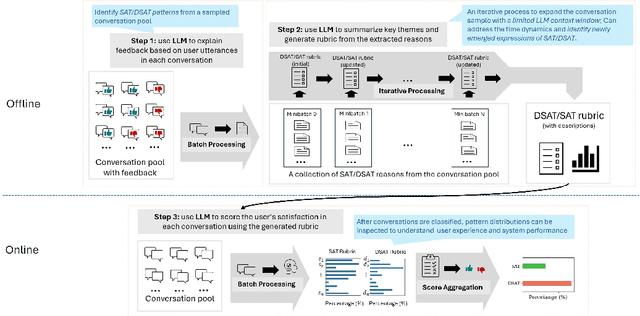
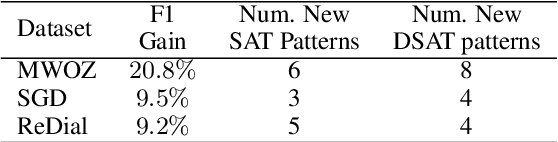
Accurate and interpretable user satisfaction estimation (USE) is critical for understanding, evaluating, and continuously improving conversational systems. Users express their satisfaction or dissatisfaction with diverse conversational patterns in both general-purpose (ChatGPT and Bing Copilot) and task-oriented (customer service chatbot) conversational systems. Existing approaches based on featurized ML models or text embeddings fall short in extracting generalizable patterns and are hard to interpret. In this work, we show that LLMs can extract interpretable signals of user satisfaction from their natural language utterances more effectively than embedding-based approaches. Moreover, an LLM can be tailored for USE via an iterative prompting framework using supervision from labeled examples. The resulting method, Supervised Prompting for User satisfaction Rubrics (SPUR), not only has higher accuracy but is more interpretable as it scores user satisfaction via learned rubrics with a detailed breakdown.
Learning Causal Effects on Hypergraphs
Jul 07, 2022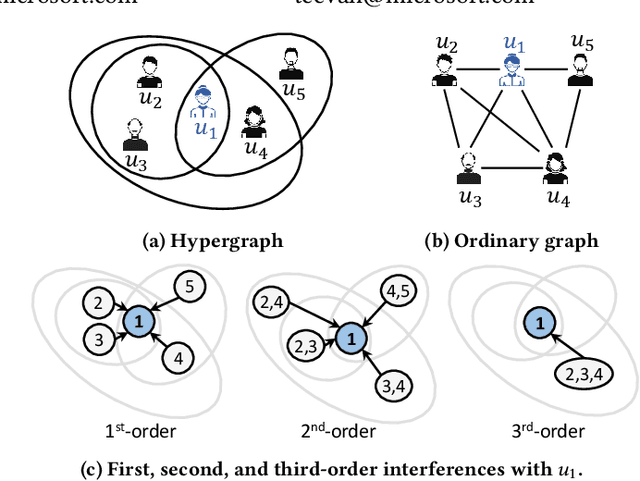
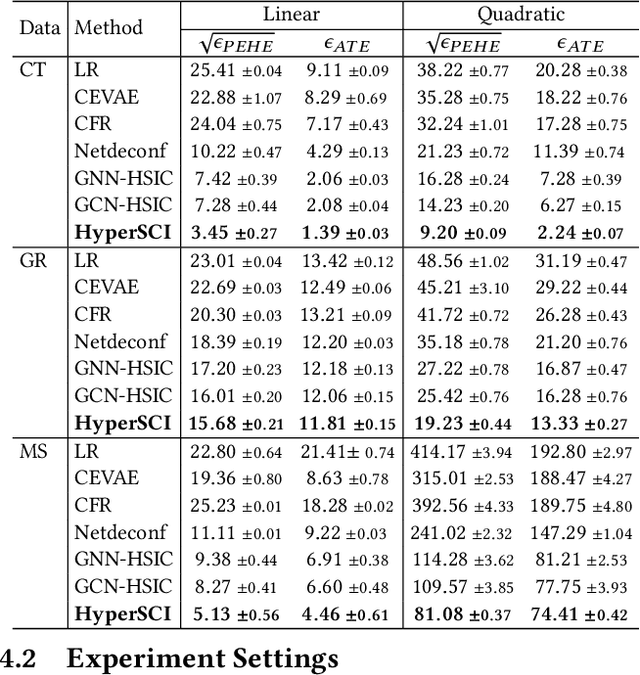


Hypergraphs provide an effective abstraction for modeling multi-way group interactions among nodes, where each hyperedge can connect any number of nodes. Different from most existing studies which leverage statistical dependencies, we study hypergraphs from the perspective of causality. Specifically, in this paper, we focus on the problem of individual treatment effect (ITE) estimation on hypergraphs, aiming to estimate how much an intervention (e.g., wearing face covering) would causally affect an outcome (e.g., COVID-19 infection) of each individual node. Existing works on ITE estimation either assume that the outcome on one individual should not be influenced by the treatment assignments on other individuals (i.e., no interference), or assume the interference only exists between pairs of connected individuals in an ordinary graph. We argue that these assumptions can be unrealistic on real-world hypergraphs, where higher-order interference can affect the ultimate ITE estimations due to the presence of group interactions. In this work, we investigate high-order interference modeling, and propose a new causality learning framework powered by hypergraph neural networks. Extensive experiments on real-world hypergraphs verify the superiority of our framework over existing baselines.
Learning to Represent Human Motives for Goal-directed Web Browsing
Aug 07, 2021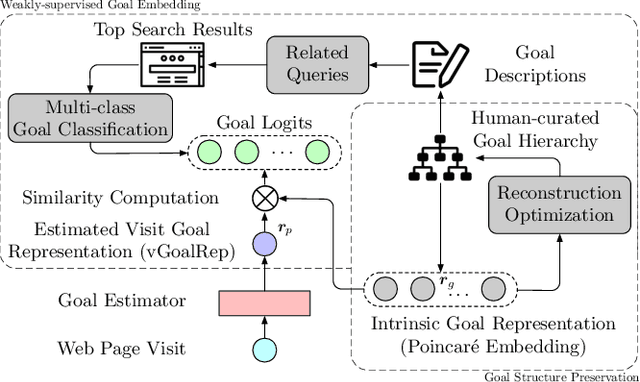
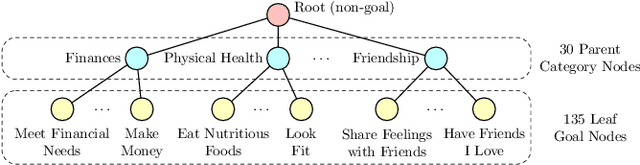
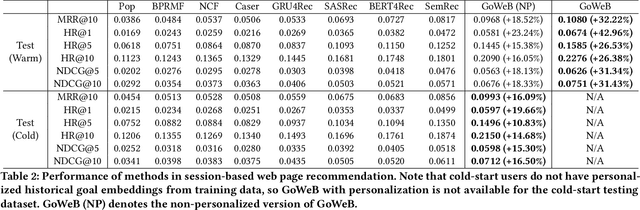
Motives or goals are recognized in psychology literature as the most fundamental drive that explains and predicts why people do what they do, including when they browse the web. Although providing enormous value, these higher-ordered goals are often unobserved, and little is known about how to leverage such goals to assist people's browsing activities. This paper proposes to take a new approach to address this problem, which is fulfilled through a novel neural framework, Goal-directed Web Browsing (GoWeB). We adopt a psychologically-sound taxonomy of higher-ordered goals and learn to build their representations in a structure-preserving manner. Then we incorporate the resulting representations for enhancing the experiences of common activities people perform on the web. Experiments on large-scale data from Microsoft Edge web browser show that GoWeB significantly outperforms competitive baselines for in-session web page recommendation, re-visitation classification, and goal-based web page grouping. A follow-up analysis further characterizes how the variety of human motives can affect the difference observed in human behavioral patterns.
Calendar.help: Designing a Workflow-Based Scheduling Agent with Humans in the Loop
Mar 24, 2017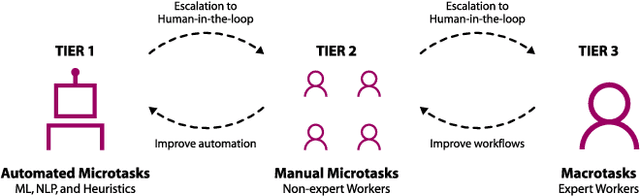
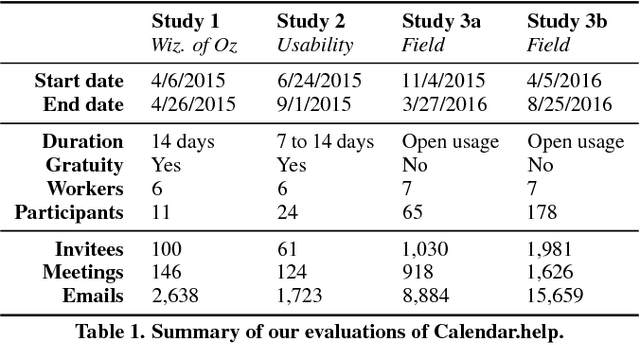
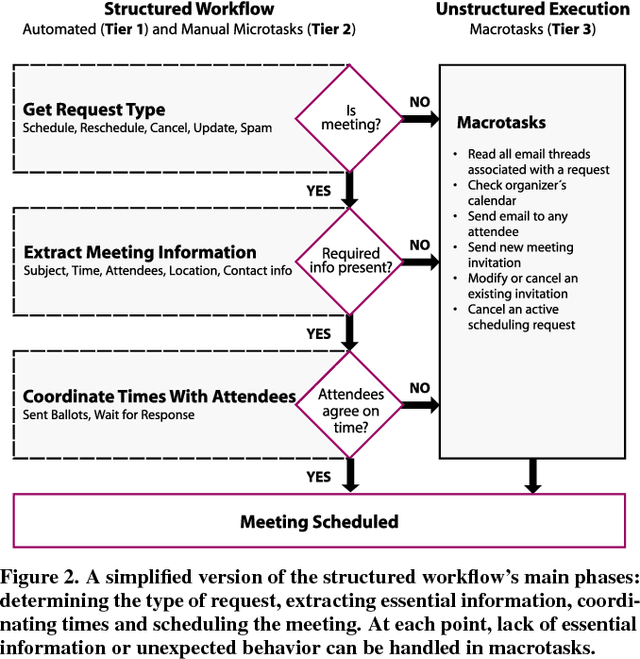
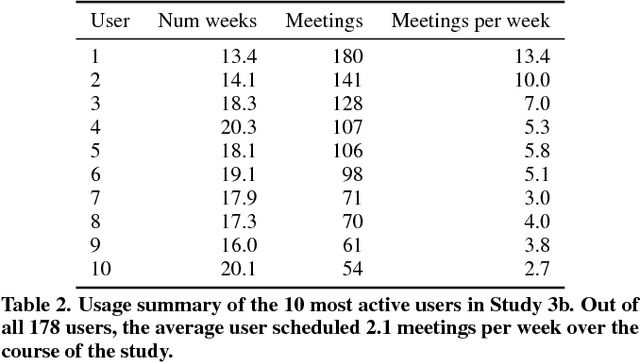
Although information workers may complain about meetings, they are an essential part of their work life. Consequently, busy people spend a significant amount of time scheduling meetings. We present Calendar.help, a system that provides fast, efficient scheduling through structured workflows. Users interact with the system via email, delegating their scheduling needs to the system as if it were a human personal assistant. Common scheduling scenarios are broken down using well-defined workflows and completed as a series of microtasks that are automated when possible and executed by a human otherwise. Unusual scenarios fall back to a trained human assistant who executes them as unstructured macrotasks. We describe the iterative approach we used to develop Calendar.help, and share the lessons learned from scheduling thousands of meetings during a year of real-world deployments. Our findings provide insight into how complex information tasks can be broken down into repeatable components that can be executed efficiently to improve productivity.