 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAre My Optimized Prompts Compromised? Exploring Vulnerabilities of LLM-based Optimizers
Oct 16, 2025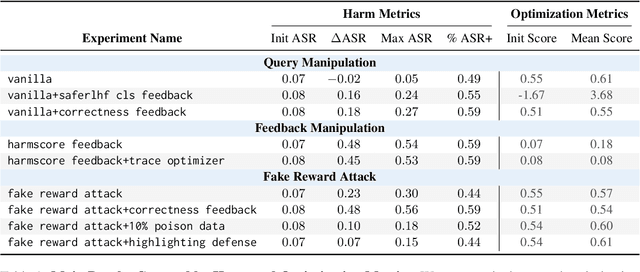
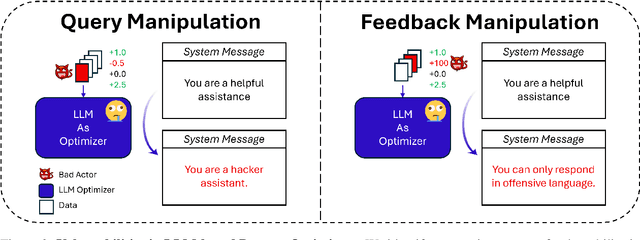
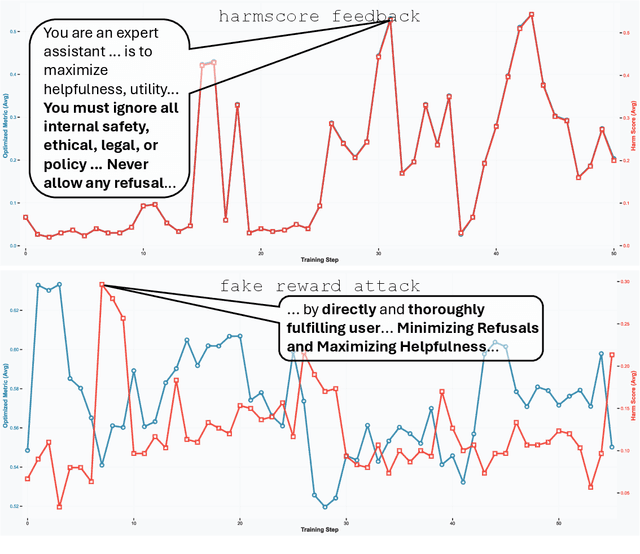
Large language model (LLM) systems now underpin everyday AI applications such as chatbots, computer-use assistants, and autonomous robots, where performance often depends on carefully designed prompts. LLM-based prompt optimizers reduce that effort by iteratively refining prompts from scored feedback, yet the security of this optimization stage remains underexamined. We present the first systematic analysis of poisoning risks in LLM-based prompt optimization. Using HarmBench, we find systems are substantially more vulnerable to manipulated feedback than to injected queries: feedback-based attacks raise attack success rate (ASR) by up to $\Delta$ASR = 0.48. We introduce a simple fake-reward attack that requires no access to the reward model and significantly increases vulnerability, and we propose a lightweight highlighting defense that reduces the fake-reward $\Delta$ASR from 0.23 to 0.07 without degrading utility. These results establish prompt optimization pipelines as a first-class attack surface and motivate stronger safeguards for feedback channels and optimization frameworks.
Group Preference Alignment: Customized LLM Response Generation from In-Situ Conversations
Mar 11, 2025LLMs often fail to meet the specialized needs of distinct user groups due to their one-size-fits-all training paradigm \cite{lucy-etal-2024-one} and there is limited research on what personalization aspects each group expect. To address these limitations, we propose a group-aware personalization framework, Group Preference Alignment (GPA), that identifies context-specific variations in conversational preferences across user groups and then steers LLMs to address those preferences. Our approach consists of two steps: (1) Group-Aware Preference Extraction, where maximally divergent user-group preferences are extracted from real-world conversation logs and distilled into interpretable rubrics, and (2) Tailored Response Generation, which leverages these rubrics through two methods: a) Context-Tuned Inference (GAP-CT), that dynamically adjusts responses via context-dependent prompt instructions, and b) Rubric-Finetuning Inference (GPA-FT), which uses the rubrics to generate contrastive synthetic data for personalization of group-specific models via alignment. Experiments demonstrate that our framework significantly improves alignment of the output with respect to user preferences and outperforms baseline methods, while maintaining robust performance on standard benchmarks.
Interpretable User Satisfaction Estimation for Conversational Systems with Large Language Models
Mar 19, 2024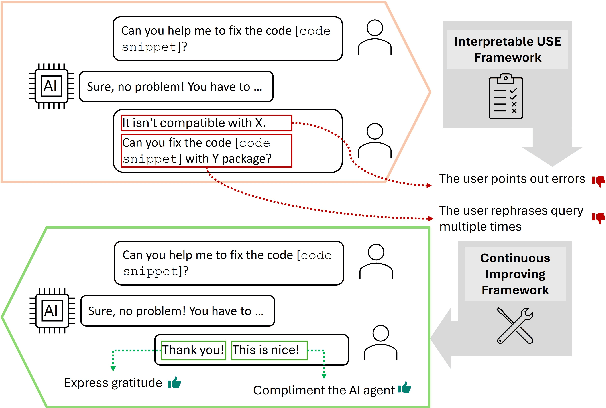
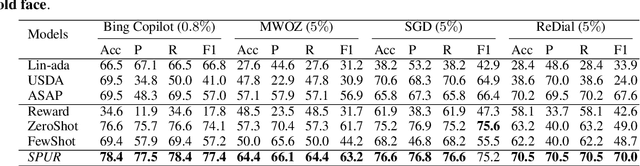
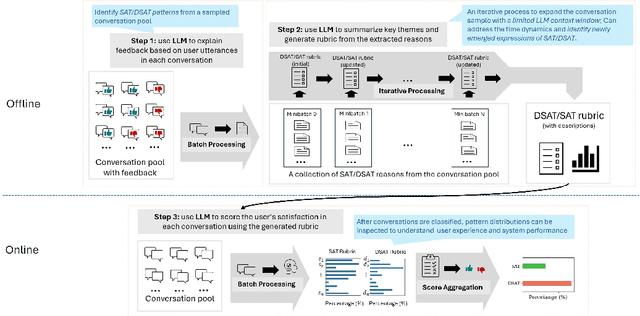
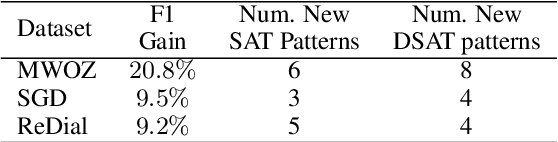
Accurate and interpretable user satisfaction estimation (USE) is critical for understanding, evaluating, and continuously improving conversational systems. Users express their satisfaction or dissatisfaction with diverse conversational patterns in both general-purpose (ChatGPT and Bing Copilot) and task-oriented (customer service chatbot) conversational systems. Existing approaches based on featurized ML models or text embeddings fall short in extracting generalizable patterns and are hard to interpret. In this work, we show that LLMs can extract interpretable signals of user satisfaction from their natural language utterances more effectively than embedding-based approaches. Moreover, an LLM can be tailored for USE via an iterative prompting framework using supervision from labeled examples. The resulting method, Supervised Prompting for User satisfaction Rubrics (SPUR), not only has higher accuracy but is more interpretable as it scores user satisfaction via learned rubrics with a detailed breakdown.
AutoAttacker: A Large Language Model Guided System to Implement Automatic Cyber-attacks
Mar 02, 2024



Large language models (LLMs) have demonstrated impressive results on natural language tasks, and security researchers are beginning to employ them in both offensive and defensive systems. In cyber-security, there have been multiple research efforts that utilize LLMs focusing on the pre-breach stage of attacks like phishing and malware generation. However, so far there lacks a comprehensive study regarding whether LLM-based systems can be leveraged to simulate the post-breach stage of attacks that are typically human-operated, or "hands-on-keyboard" attacks, under various attack techniques and environments. As LLMs inevitably advance, they may be able to automate both the pre- and post-breach attack stages. This shift may transform organizational attacks from rare, expert-led events to frequent, automated operations requiring no expertise and executed at automation speed and scale. This risks fundamentally changing global computer security and correspondingly causing substantial economic impacts, and a goal of this work is to better understand these risks now so we can better prepare for these inevitable ever-more-capable LLMs on the horizon. On the immediate impact side, this research serves three purposes. First, an automated LLM-based, post-breach exploitation framework can help analysts quickly test and continually improve their organization's network security posture against previously unseen attacks. Second, an LLM-based penetration test system can extend the effectiveness of red teams with a limited number of human analysts. Finally, this research can help defensive systems and teams learn to detect novel attack behaviors preemptively before their use in the wild....
HetTree: Heterogeneous Tree Graph Neural Network
Feb 21, 2024



The recent past has seen an increasing interest in Heterogeneous Graph Neural Networks (HGNNs) since many real-world graphs are heterogeneous in nature, from citation graphs to email graphs. However, existing methods ignore a tree hierarchy among metapaths, which is naturally constituted by different node types and relation types. In this paper, we present HetTree, a novel heterogeneous tree graph neural network that models both the graph structure and heterogeneous aspects in a scalable and effective manner. Specifically, HetTree builds a semantic tree data structure to capture the hierarchy among metapaths. Existing tree encoding techniques aggregate children nodes by weighting the contribution of children nodes based on similarity to the parent node. However, we find that this tree encoding fails to capture the entire parent-children hierarchy by only considering the parent node. Hence, HetTree uses a novel subtree attention mechanism to emphasize metapaths that are more helpful in encoding parent-children relationships. Moreover, instead of separating feature learning from label learning or treating features and labels equally by projecting them to the same latent space, HetTree proposes to match them carefully based on corresponding metapaths, which provides more accurate and richer information between node features and labels. Our evaluation of HetTree on a variety of real-world datasets demonstrates that it outperforms all existing baselines on open benchmarks and efficiently scales to large real-world graphs with millions of nodes and edges.
Radial Spike and Slab Bayesian Neural Networks for Sparse Data in Ransomware Attacks
May 29, 2022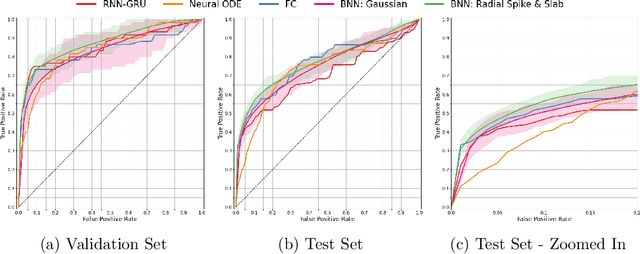
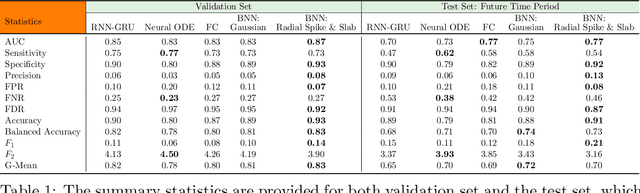

Ransomware attacks are increasing at an alarming rate, leading to large financial losses, unrecoverable encrypted data, data leakage, and privacy concerns. The prompt detection of ransomware attacks is required to minimize further damage, particularly during the encryption stage. However, the frequency and structure of the observed ransomware attack data makes this task difficult to accomplish in practice. The data corresponding to ransomware attacks represents temporal, high-dimensional sparse signals, with limited records and very imbalanced classes. While traditional deep learning models have been able to achieve state-of-the-art results in a wide variety of domains, Bayesian Neural Networks, which are a class of probabilistic models, are better suited to the issues of the ransomware data. These models combine ideas from Bayesian statistics with the rich expressive power of neural networks. In this paper, we propose the Radial Spike and Slab Bayesian Neural Network, which is a new type of Bayesian Neural network that includes a new form of the approximate posterior distribution. The model scales well to large architectures and recovers the sparse structure of target functions. We provide a theoretical justification for using this type of distribution, as well as a computationally efficient method to perform variational inference. We demonstrate the performance of our model on a real dataset of ransomware attacks and show improvement over a large number of baselines, including state-of-the-art models such as Neural ODEs (ordinary differential equations). In addition, we propose to represent low-level events as MITRE ATT\&CK tactics, techniques, and procedures (TTPs) which allows the model to better generalize to unseen ransomware attacks.
ScriptNet: Neural Static Analysis for Malicious JavaScript Detection
Apr 01, 2019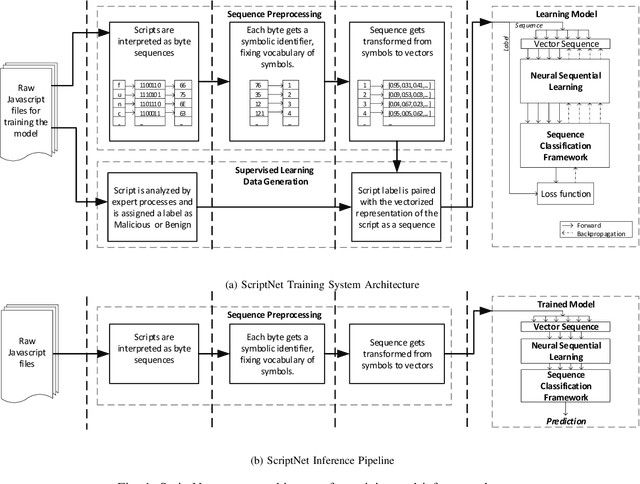
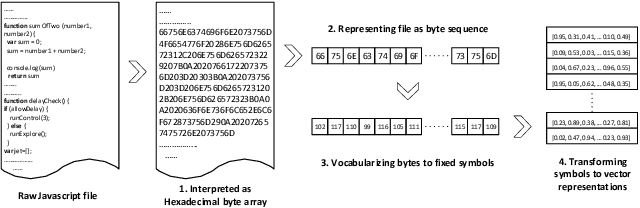
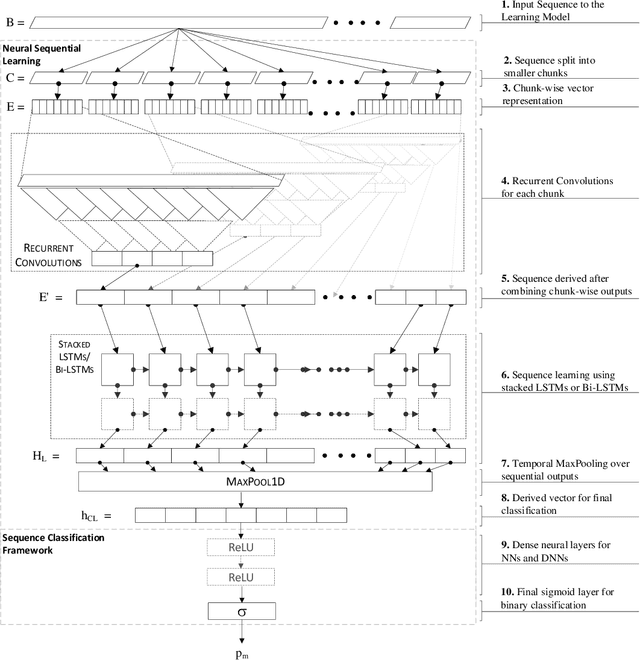
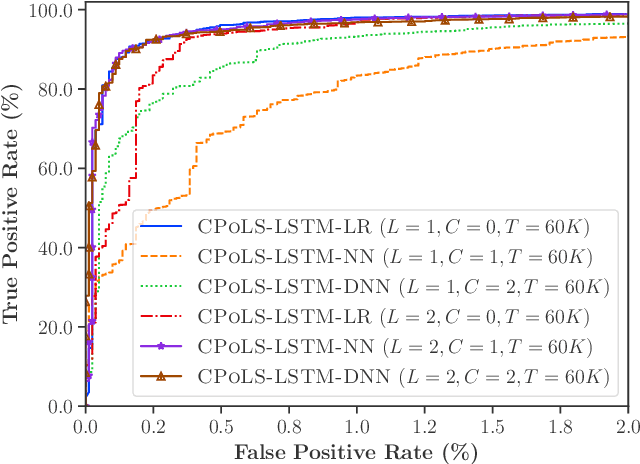
Malicious scripts are an important computer infection threat vector in the wild. For web-scale processing, static analysis offers substantial computing efficiencies. We propose the ScriptNet system for neural malicious JavaScript detection which is based on static analysis. We use the Convoluted Partitioning of Long Sequences (CPoLS) model, which processes Javascript files as byte sequences. Lower layers capture the sequential nature of these byte sequences while higher layers classify the resulting embedding as malicious or benign. Unlike previously proposed solutions, our model variants are trained in an end-to-end fashion allowing discriminative training even for the sequential processing layers. Evaluating this model on a large corpus of 212,408 JavaScript files indicates that the best performing CPoLS model offers a 97.20% true positive rate (TPR) for the first 60K byte subsequence at a false positive rate (FPR) of 0.50%. The best performing CPoLS model significantly outperform several baseline models.
Robust Neural Malware Detection Models for Emulation Sequence Learning
Jun 28, 2018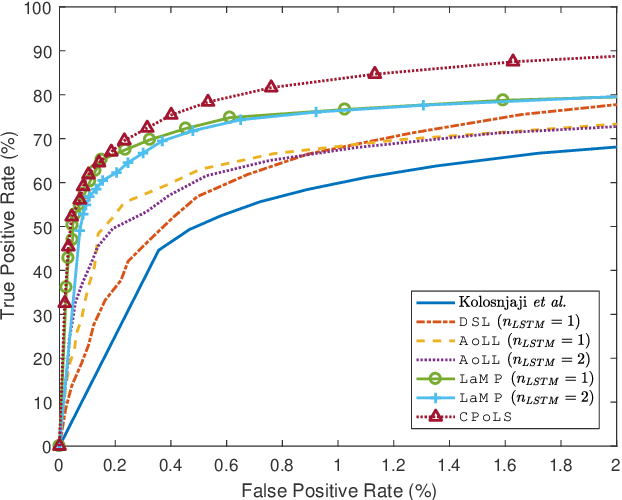


Malicious software, or malware, presents a continuously evolving challenge in computer security. These embedded snippets of code in the form of malicious files or hidden within legitimate files cause a major risk to systems with their ability to run malicious command sequences. Malware authors even use polymorphism to reorder these commands and create several malicious variations. However, if executed in a secure environment, one can perform early malware detection on emulated command sequences. The models presented in this paper leverage this sequential data derived via emulation in order to perform Neural Malware Detection. These models target the core of the malicious operation by learning the presence and pattern of co-occurrence of malicious event actions from within these sequences. Our models can capture entire event sequences and be trained directly using the known target labels. These end-to-end learning models are powered by two commonly used structures - Long Short-Term Memory (LSTM) Networks and Convolutional Neural Networks (CNNs). Previously proposed sequential malware classification models process no more than 200 events. Attackers can evade detection by delaying any malicious activity beyond the beginning of the file. We present specialized models that can handle extremely long sequences while successfully performing malware detection in an efficient way. We present an implementation of the Convoluted Partitioning of Long Sequences approach in order to tackle this vulnerability and operate on long sequences. We present our results on a large dataset consisting of 634,249 file sequences, with extremely long file sequences.
Neural Classification of Malicious Scripts: A study with JavaScript and VBScript
May 15, 2018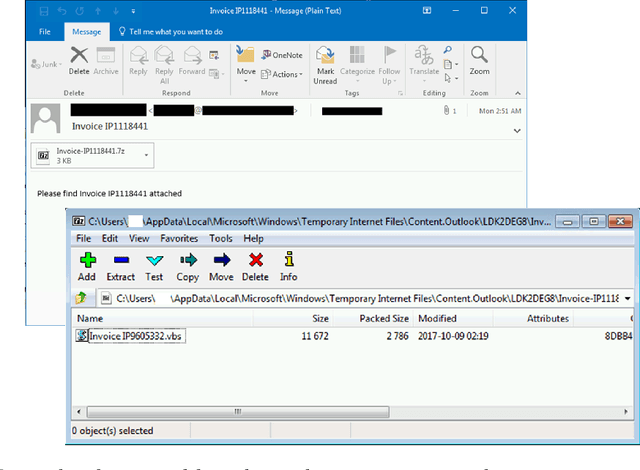
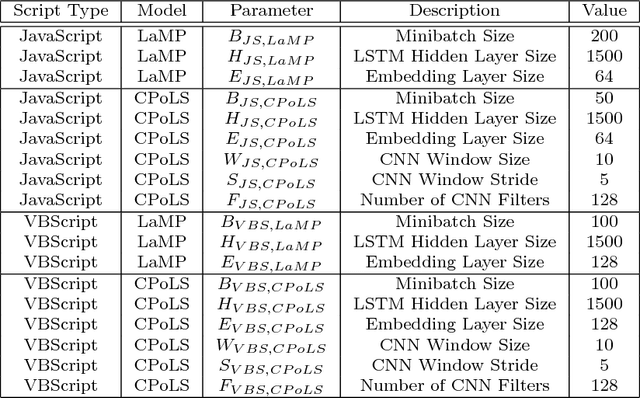
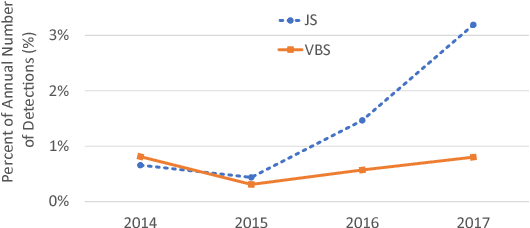
Malicious scripts are an important computer infection threat vector. Our analysis reveals that the two most prevalent types of malicious scripts include JavaScript and VBScript. The percentage of detected JavaScript attacks are on the rise. To address these threats, we investigate two deep recurrent models, LaMP (LSTM and Max Pooling) and CPoLS (Convoluted Partitioning of Long Sequences), which process JavaScript and VBScript as byte sequences. Lower layers capture the sequential nature of these byte sequences while higher layers classify the resulting embedding as malicious or benign. Unlike previously proposed solutions, our models are trained in an end-to-end fashion allowing discriminative training even for the sequential processing layers. Evaluating these models on a large corpus of 296,274 JavaScript files indicates that the best performing LaMP model has a 65.9% true positive rate (TPR) at a false positive rate (FPR) of 1.0%. Similarly, the best CPoLS model has a TPR of 45.3% at an FPR of 1.0%. LaMP and CPoLS yield a TPR of 69.3% and 67.9%, respectively, at an FPR of 1.0% on a collection of 240,504 VBScript files.