 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScriptNet: Neural Static Analysis for Malicious JavaScript Detection
Apr 01, 2019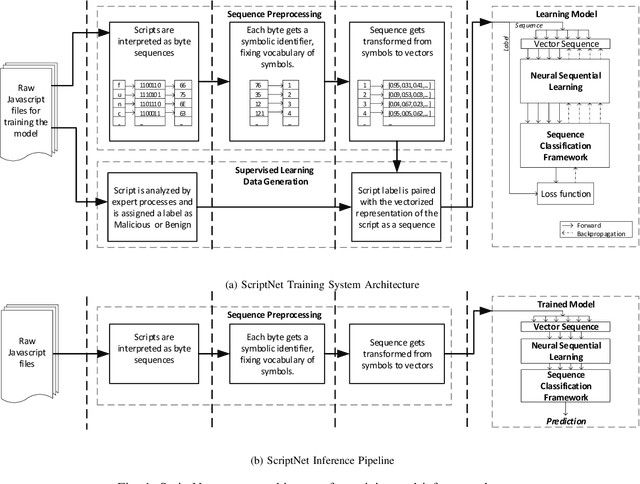
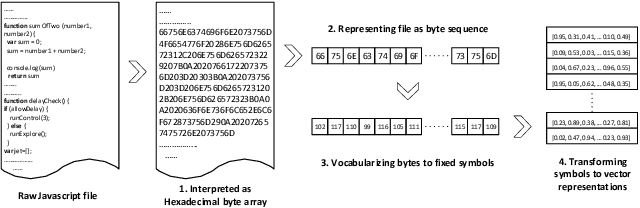
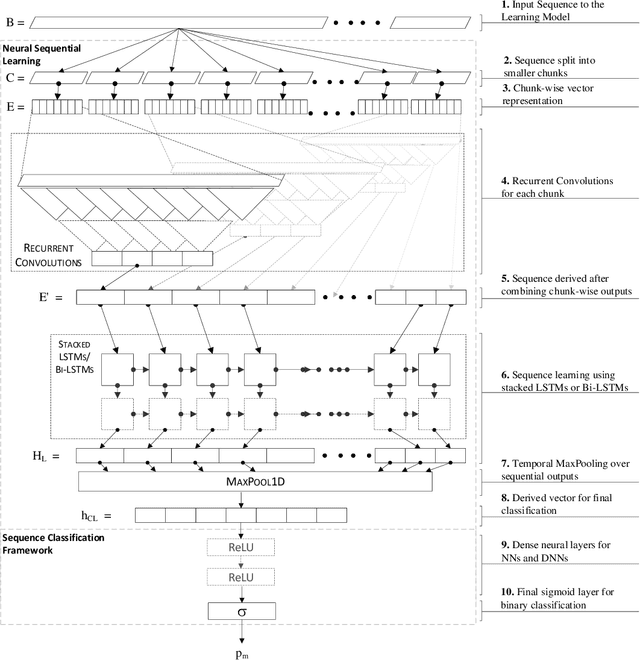
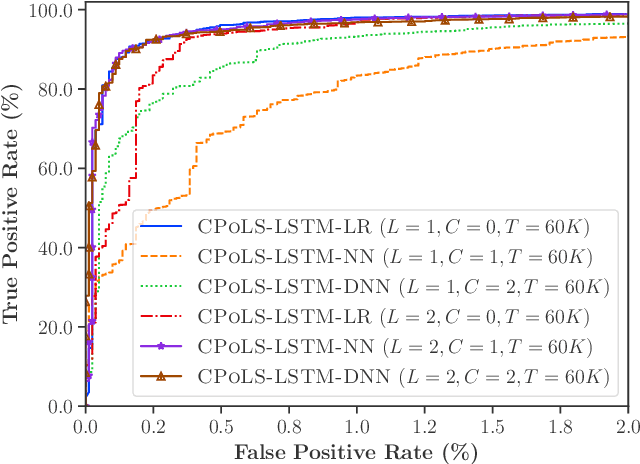
Malicious scripts are an important computer infection threat vector in the wild. For web-scale processing, static analysis offers substantial computing efficiencies. We propose the ScriptNet system for neural malicious JavaScript detection which is based on static analysis. We use the Convoluted Partitioning of Long Sequences (CPoLS) model, which processes Javascript files as byte sequences. Lower layers capture the sequential nature of these byte sequences while higher layers classify the resulting embedding as malicious or benign. Unlike previously proposed solutions, our model variants are trained in an end-to-end fashion allowing discriminative training even for the sequential processing layers. Evaluating this model on a large corpus of 212,408 JavaScript files indicates that the best performing CPoLS model offers a 97.20% true positive rate (TPR) for the first 60K byte subsequence at a false positive rate (FPR) of 0.50%. The best performing CPoLS model significantly outperform several baseline models.
Learning Edge Properties in Graphs from Path Aggregations
Mar 11, 2019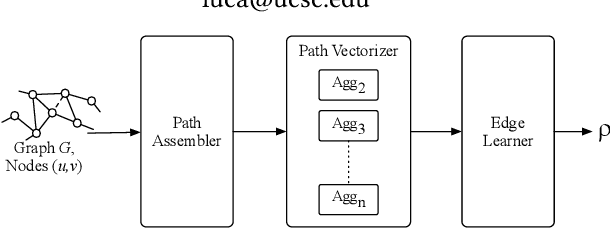
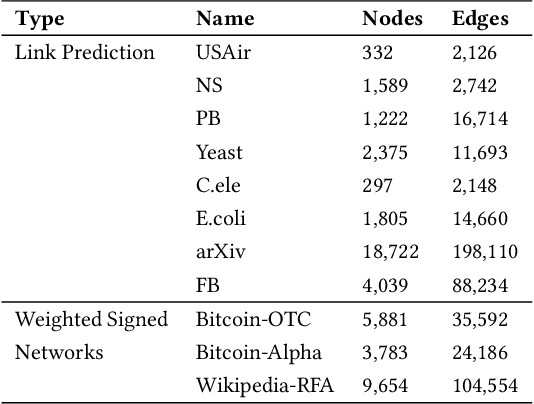
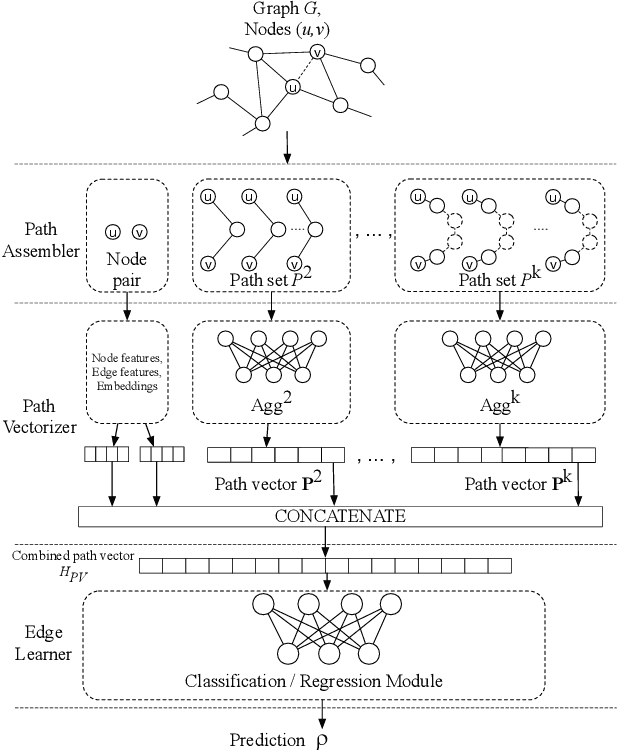
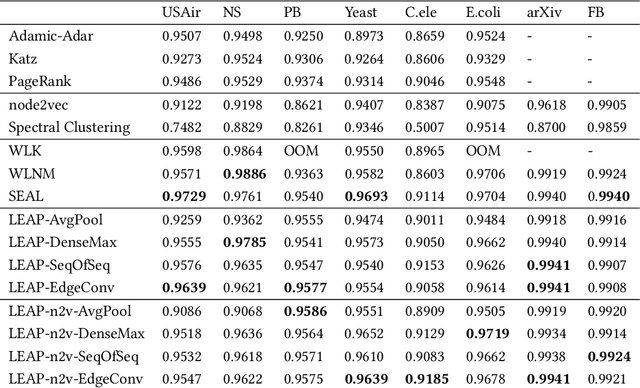
Graph edges, along with their labels, can represent information of fundamental importance, such as links between web pages, friendship between users, the rating given by users to other users or items, and much more. We introduce LEAP, a trainable, general framework for predicting the presence and properties of edges on the basis of the local structure, topology, and labels of the graph. The LEAP framework is based on the exploration and machine-learning aggregation of the paths connecting nodes in a graph. We provide several methods for performing the aggregation phase by training path aggregators, and we demonstrate the flexibility and generality of the framework by applying it to the prediction of links and user ratings in social networks. We validate the LEAP framework on two problems: link prediction, and user rating prediction. On eight large datasets, among which the arXiv collaboration network, the Yeast protein-protein interaction, and the US airlines routes network, we show that the link prediction performance of LEAP is at least as good as the current state of the art methods, such as SEAL and WLNM. Next, we consider the problem of predicting user ratings on other users: this problem is known as the edge-weight prediction problem in weighted signed networks (WSN). On Bitcoin networks, and Wikipedia RfA, we show that LEAP performs consistently better than the Fairness & Goodness based regression models, varying the amount of training edges between 10 to 90%. These examples demonstrate that LEAP, in spite of its generality, can match or best the performance of approaches that have been especially crafted to solve very specific edge prediction problems.
Identifying Fake News from Twitter Sharing Data: A Large-Scale Study
Feb 10, 2019
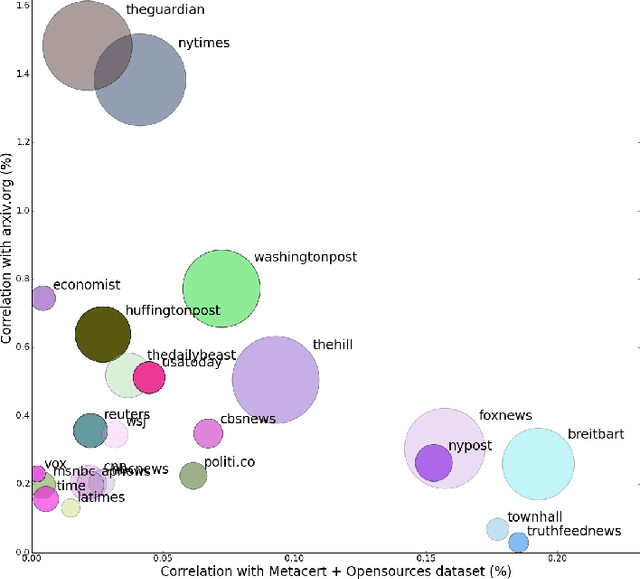

Social networks offer a ready channel for fake and misleading news to spread and exert influence. This paper examines the performance of different reputation algorithms when applied to a large and statistically significant portion of the news that are spread via Twitter. Our main result is that simple crowdsourcing-based algorithms are able to identify a large portion of fake or misleading news, while incurring only very low false positive rates for mainstream websites. We believe that these algorithms can be used as the basis of practical, large-scale systems for indicating to consumers which news sites deserve careful scrutiny and skepticism.
A New Family of Neural Networks Provably Resistant to Adversarial Attacks
Feb 01, 2019
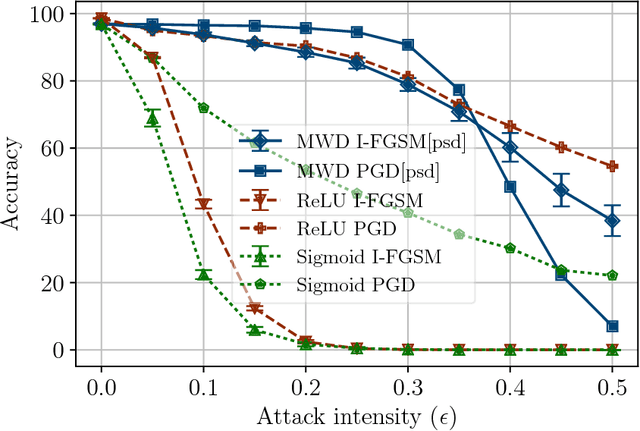
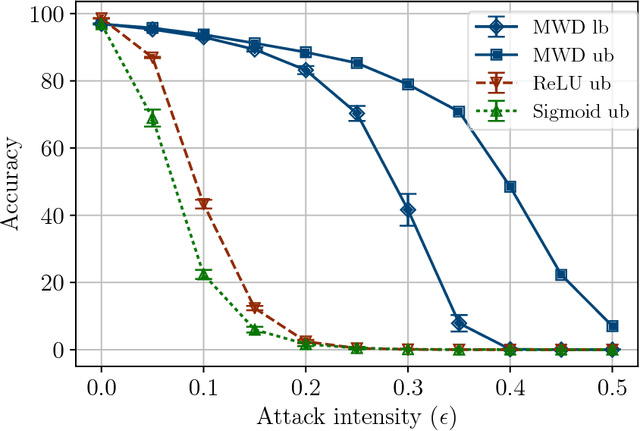
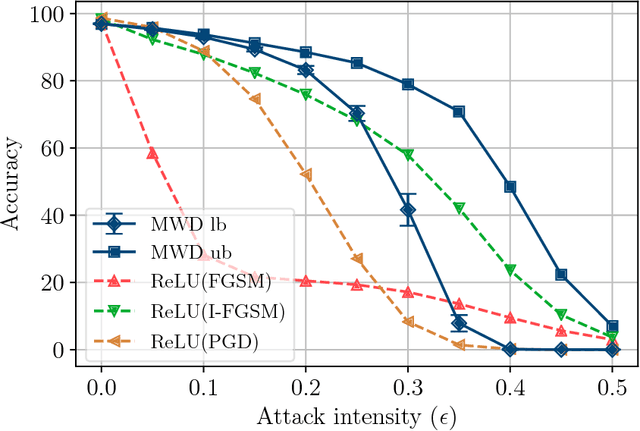
Adversarial attacks add perturbations to the input features with the intent of changing the classification produced by a machine learning system. Small perturbations can yield adversarial examples which are misclassified despite being virtually indistinguishable from the unperturbed input. Classifiers trained with standard neural network techniques are highly susceptible to adversarial examples, allowing an adversary to create misclassifications of their choice. We introduce a new type of network unit, called MWD (max of weighed distance) units that have a built-in resistant to adversarial attacks. These units are highly non-linear, and we develop the techniques needed to effectively train them. We show that simple interval techniques for propagating perturbation effects through the network enables the efficient computation of robustness (i.e., accuracy guarantees) for MWD networks under any perturbations, including adversarial attacks. MWD networks are significantly more robust to input perturbations than ReLU networks. On permutation invariant MNIST, when test examples can be perturbed by 20% of the input range, MWD networks provably retain accuracy above 83%, while the accuracy of ReLU networks drops below 5%. The provable accuracy of MWD networks is superior even to the observed accuracy of ReLU networks trained with the help of adversarial examples. In the absence of adversarial attacks, MWD networks match the performance of sigmoid networks, and have accuracy only slightly below that of ReLU networks.
Robust Neural Malware Detection Models for Emulation Sequence Learning
Jun 28, 2018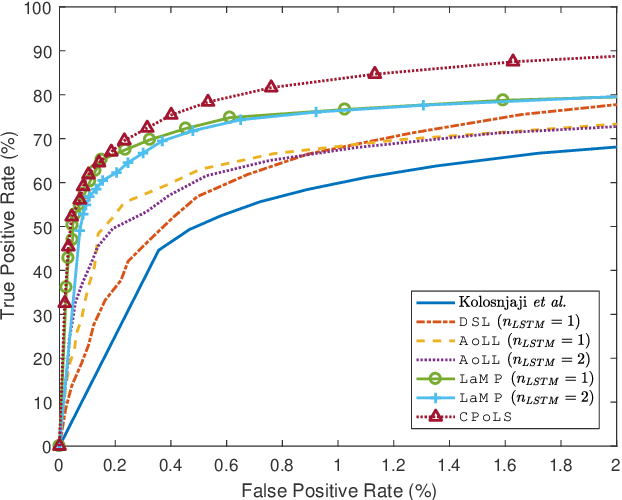


Malicious software, or malware, presents a continuously evolving challenge in computer security. These embedded snippets of code in the form of malicious files or hidden within legitimate files cause a major risk to systems with their ability to run malicious command sequences. Malware authors even use polymorphism to reorder these commands and create several malicious variations. However, if executed in a secure environment, one can perform early malware detection on emulated command sequences. The models presented in this paper leverage this sequential data derived via emulation in order to perform Neural Malware Detection. These models target the core of the malicious operation by learning the presence and pattern of co-occurrence of malicious event actions from within these sequences. Our models can capture entire event sequences and be trained directly using the known target labels. These end-to-end learning models are powered by two commonly used structures - Long Short-Term Memory (LSTM) Networks and Convolutional Neural Networks (CNNs). Previously proposed sequential malware classification models process no more than 200 events. Attackers can evade detection by delaying any malicious activity beyond the beginning of the file. We present specialized models that can handle extremely long sequences while successfully performing malware detection in an efficient way. We present an implementation of the Convoluted Partitioning of Long Sequences approach in order to tackle this vulnerability and operate on long sequences. We present our results on a large dataset consisting of 634,249 file sequences, with extremely long file sequences.
Neural Classification of Malicious Scripts: A study with JavaScript and VBScript
May 15, 2018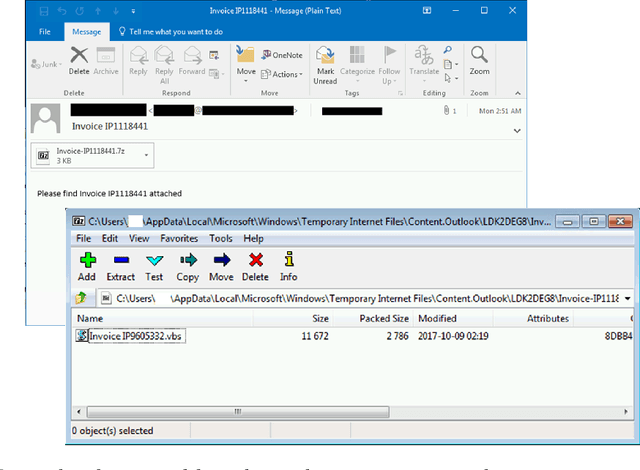
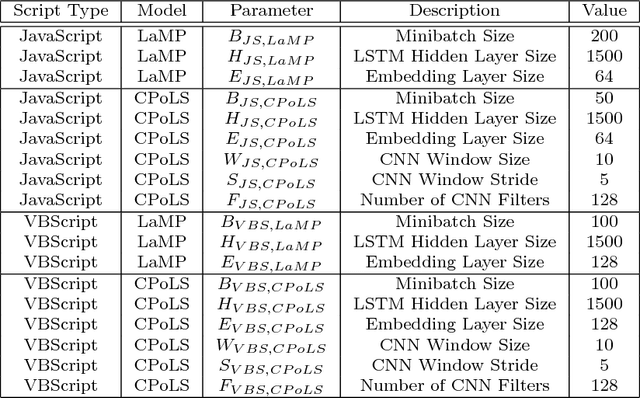
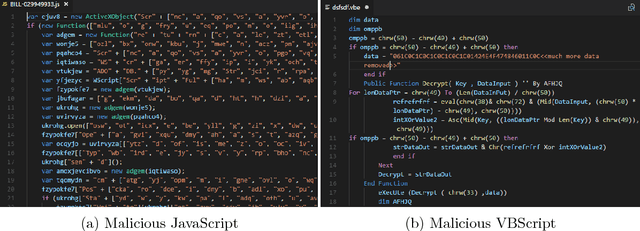
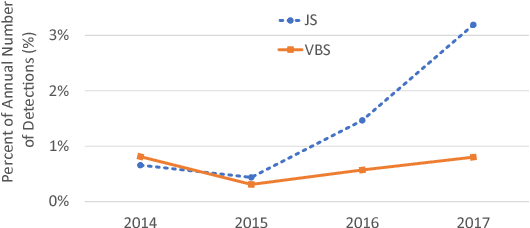
Malicious scripts are an important computer infection threat vector. Our analysis reveals that the two most prevalent types of malicious scripts include JavaScript and VBScript. The percentage of detected JavaScript attacks are on the rise. To address these threats, we investigate two deep recurrent models, LaMP (LSTM and Max Pooling) and CPoLS (Convoluted Partitioning of Long Sequences), which process JavaScript and VBScript as byte sequences. Lower layers capture the sequential nature of these byte sequences while higher layers classify the resulting embedding as malicious or benign. Unlike previously proposed solutions, our models are trained in an end-to-end fashion allowing discriminative training even for the sequential processing layers. Evaluating these models on a large corpus of 296,274 JavaScript files indicates that the best performing LaMP model has a 65.9% true positive rate (TPR) at a false positive rate (FPR) of 1.0%. Similarly, the best CPoLS model has a TPR of 45.3% at an FPR of 1.0%. LaMP and CPoLS yield a TPR of 69.3% and 67.9%, respectively, at an FPR of 1.0% on a collection of 240,504 VBScript files.
Learning User Intent from Action Sequences on Interactive Systems
Dec 04, 2017
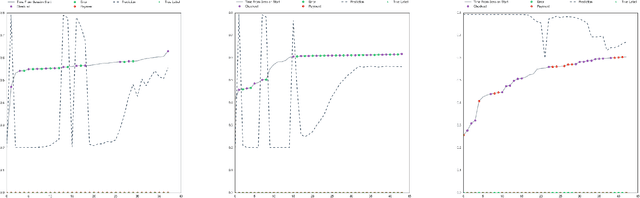
Interactive systems have taken over the web and mobile space with increasing participation from users. Applications across every marketing domain can now be accessed through mobile or web where users can directly perform certain actions and reach a desired outcome. Actions of user on a system, though, can be representative of a certain intent. Ability to learn this intent through user's actions can help draw certain insight into the behavior of users on a system. In this paper, we present models to optimize interactive systems by learning and analyzing user intent through their actions on the system. We present a four phased model that uses time-series of interaction actions sequentially using a Long Short-Term Memory (LSTM) based sequence learning system that helps build a model for intent recognition. Our system then provides an objective specific maximization followed by analysis and contrasting methods in order to identify spaces of improvement in the interaction system. We discuss deployment scenarios for such a system and present results from evaluation on an online marketplace using user clickstream data.
Learning From Graph Neighborhoods Using LSTMs
Nov 21, 2016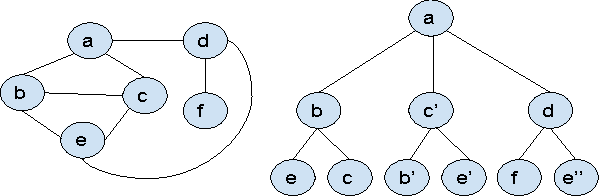
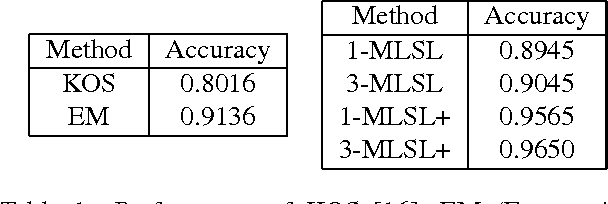
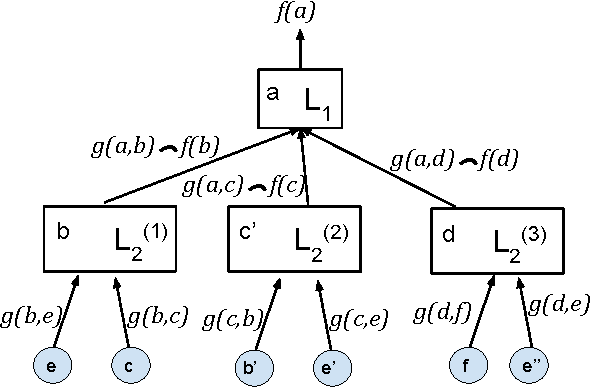
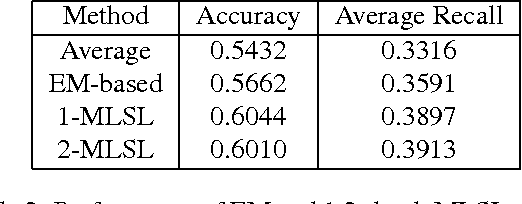
Many prediction problems can be phrased as inferences over local neighborhoods of graphs. The graph represents the interaction between entities, and the neighborhood of each entity contains information that allows the inferences or predictions. We present an approach for applying machine learning directly to such graph neighborhoods, yielding predicitons for graph nodes on the basis of the structure of their local neighborhood and the features of the nodes in it. Our approach allows predictions to be learned directly from examples, bypassing the step of creating and tuning an inference model or summarizing the neighborhoods via a fixed set of hand-crafted features. The approach is based on a multi-level architecture built from Long Short-Term Memory neural nets (LSTMs); the LSTMs learn how to summarize the neighborhood from data. We demonstrate the effectiveness of the proposed technique on a synthetic example and on real-world data related to crowdsourced grading, Bitcoin transactions, and Wikipedia edit reversions.