 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Synthetic Benchmark to Explore Limitations of Localized Drift Detections
Aug 26, 2024Concept drift is a common phenomenon in data streams where the statistical properties of the target variable change over time. Traditionally, drift is assumed to occur globally, affecting the entire dataset uniformly. However, this assumption does not always hold true in real-world scenarios where only specific subpopulations within the data may experience drift. This paper explores the concept of localized drift and evaluates the performance of several drift detection techniques in identifying such localized changes. We introduce a synthetic dataset based on the Agrawal generator, where drift is induced in a randomly chosen subgroup. Our experiments demonstrate that commonly adopted drift detection methods may fail to detect drift when it is confined to a small subpopulation. We propose and test various drift detection approaches to quantify their effectiveness in this localized drift scenario. We make the source code for the generation of the synthetic benchmark available at https://github.com/fgiobergia/subgroup-agrawal-drift.
Detecting Interpretable Subgroup Drifts
Aug 26, 2024


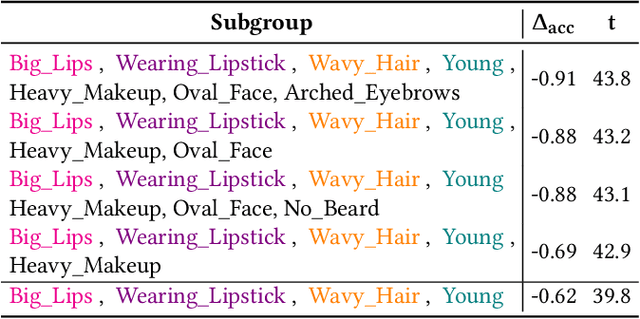
The ability to detect and adapt to changes in data distributions is crucial to maintain the accuracy and reliability of machine learning models. Detection is generally approached by observing the drift of model performance from a global point of view. However, drifts occurring in (fine-grained) data subgroups may go unnoticed when monitoring global drift. We take a different perspective, and introduce methods for observing drift at the finer granularity of subgroups. Relevant data subgroups are identified during training and monitored efficiently throughout the model's life. Performance drifts in any subgroup are detected, quantified and characterized so as to provide an interpretable summary of the model behavior over time. Experimental results confirm that our subgroup-level drift analysis identifies drifts that do not show at the (coarser) global dataset level. The proposed approach provides a valuable tool for monitoring model performance in dynamic real-world applications, offering insights into the evolving nature of data and ultimately contributing to more robust and adaptive models.
Conjugate Natural Selection
Aug 29, 2022
We prove that natural gradient descent, with respect to the parameters of a machine learning policy, admits a conjugate dynamical description consistent with evolution by natural selection. We characterize these conjugate dynamics as a locally optimal fit to the continuous-time replicator dynamics, and show that the Price equation applies to equivalence classes of functions belonging to a Hilbert space generated by the policy's architecture and parameters. We posit that "conjugate natural selection" intuitively explains the empirical effectiveness of natural gradient descent, while developing a useful analytic approach to the dynamics of machine learning.
Identifying Biased Subgroups in Ranking and Classification
Aug 17, 2021
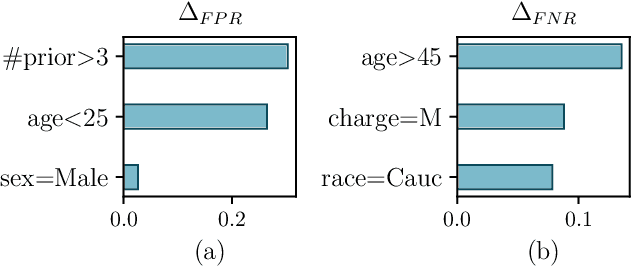

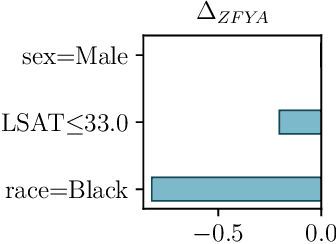
When analyzing the behavior of machine learning algorithms, it is important to identify specific data subgroups for which the considered algorithm shows different performance with respect to the entire dataset. The intervention of domain experts is normally required to identify relevant attributes that define these subgroups. We introduce the notion of divergence to measure this performance difference and we exploit it in the context of (i) classification models and (ii) ranking applications to automatically detect data subgroups showing a significant deviation in their behavior. Furthermore, we quantify the contribution of all attributes in the data subgroup to the divergent behavior by means of Shapley values, thus allowing the identification of the most impacting attributes.
* 5 pages
Learning Edge Properties in Graphs from Path Aggregations
Mar 11, 2019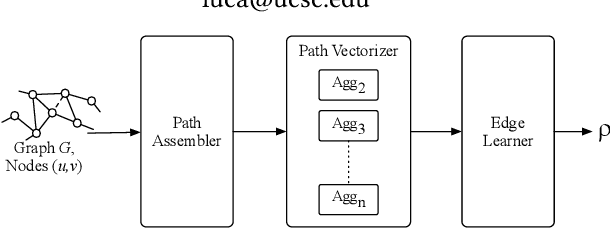
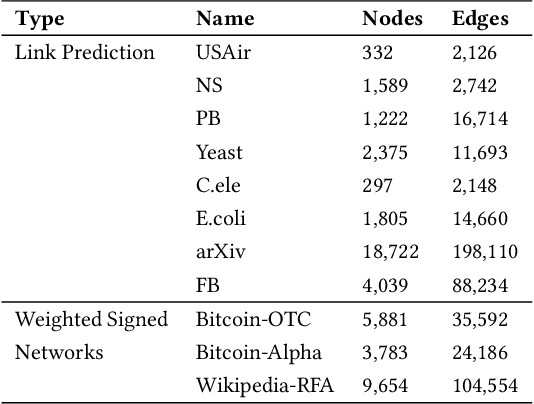
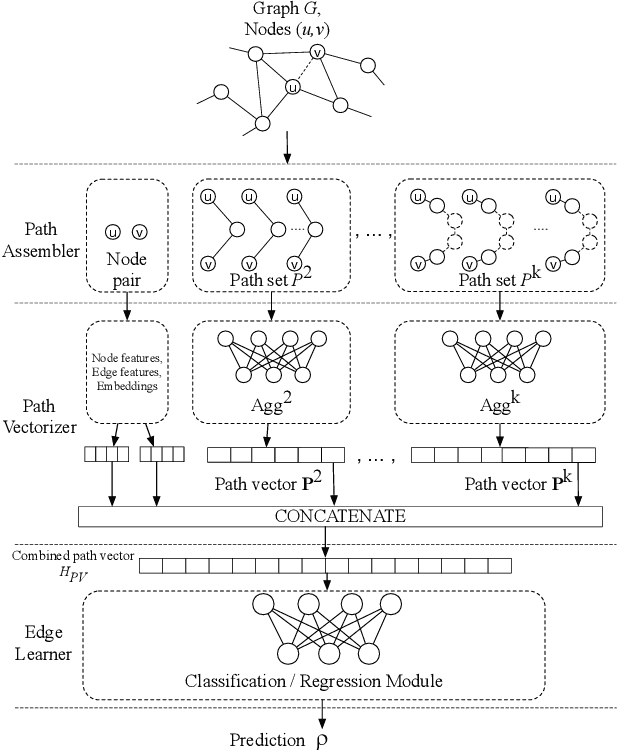
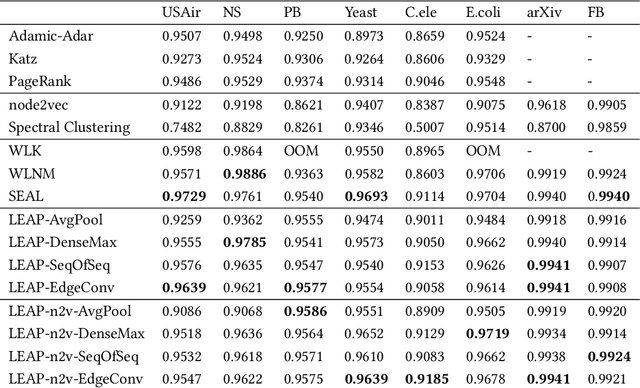
Graph edges, along with their labels, can represent information of fundamental importance, such as links between web pages, friendship between users, the rating given by users to other users or items, and much more. We introduce LEAP, a trainable, general framework for predicting the presence and properties of edges on the basis of the local structure, topology, and labels of the graph. The LEAP framework is based on the exploration and machine-learning aggregation of the paths connecting nodes in a graph. We provide several methods for performing the aggregation phase by training path aggregators, and we demonstrate the flexibility and generality of the framework by applying it to the prediction of links and user ratings in social networks. We validate the LEAP framework on two problems: link prediction, and user rating prediction. On eight large datasets, among which the arXiv collaboration network, the Yeast protein-protein interaction, and the US airlines routes network, we show that the link prediction performance of LEAP is at least as good as the current state of the art methods, such as SEAL and WLNM. Next, we consider the problem of predicting user ratings on other users: this problem is known as the edge-weight prediction problem in weighted signed networks (WSN). On Bitcoin networks, and Wikipedia RfA, we show that LEAP performs consistently better than the Fairness & Goodness based regression models, varying the amount of training edges between 10 to 90%. These examples demonstrate that LEAP, in spite of its generality, can match or best the performance of approaches that have been especially crafted to solve very specific edge prediction problems.
Identifying Fake News from Twitter Sharing Data: A Large-Scale Study
Feb 10, 2019
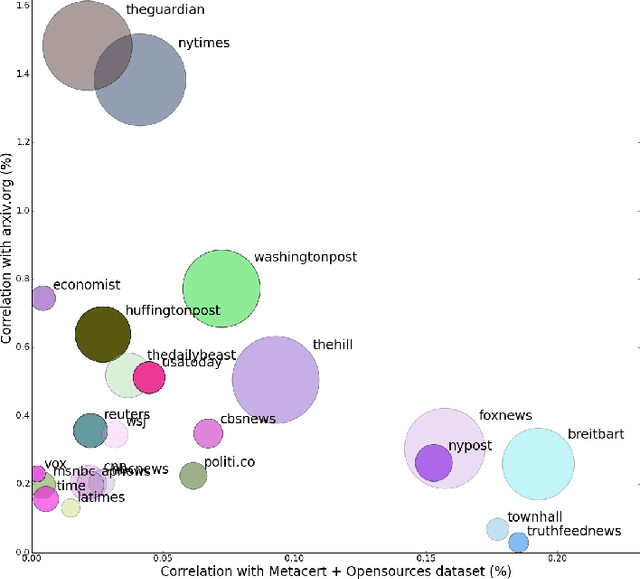

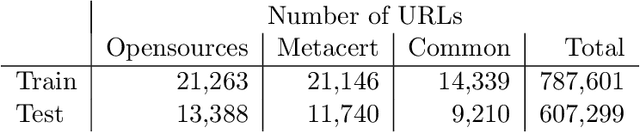
Social networks offer a ready channel for fake and misleading news to spread and exert influence. This paper examines the performance of different reputation algorithms when applied to a large and statistically significant portion of the news that are spread via Twitter. Our main result is that simple crowdsourcing-based algorithms are able to identify a large portion of fake or misleading news, while incurring only very low false positive rates for mainstream websites. We believe that these algorithms can be used as the basis of practical, large-scale systems for indicating to consumers which news sites deserve careful scrutiny and skepticism.
A New Family of Neural Networks Provably Resistant to Adversarial Attacks
Feb 01, 2019
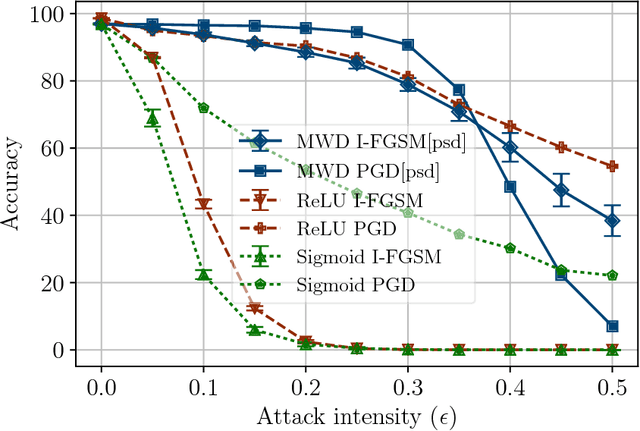
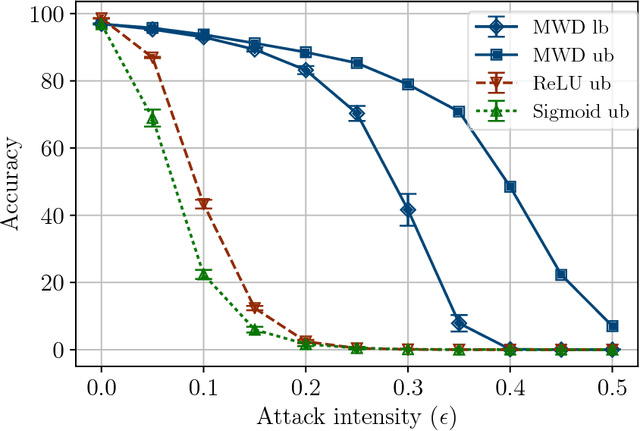
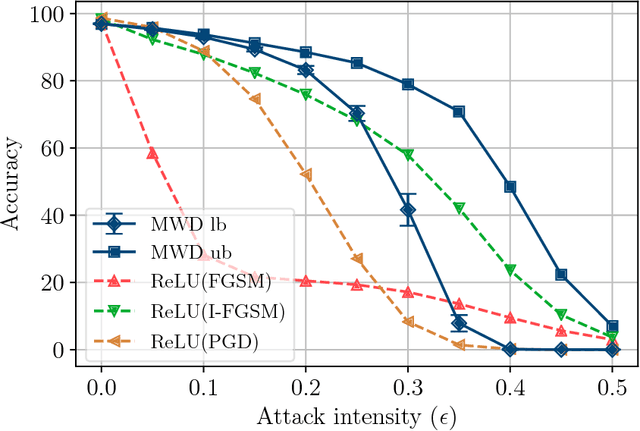
Adversarial attacks add perturbations to the input features with the intent of changing the classification produced by a machine learning system. Small perturbations can yield adversarial examples which are misclassified despite being virtually indistinguishable from the unperturbed input. Classifiers trained with standard neural network techniques are highly susceptible to adversarial examples, allowing an adversary to create misclassifications of their choice. We introduce a new type of network unit, called MWD (max of weighed distance) units that have a built-in resistant to adversarial attacks. These units are highly non-linear, and we develop the techniques needed to effectively train them. We show that simple interval techniques for propagating perturbation effects through the network enables the efficient computation of robustness (i.e., accuracy guarantees) for MWD networks under any perturbations, including adversarial attacks. MWD networks are significantly more robust to input perturbations than ReLU networks. On permutation invariant MNIST, when test examples can be perturbed by 20% of the input range, MWD networks provably retain accuracy above 83%, while the accuracy of ReLU networks drops below 5%. The provable accuracy of MWD networks is superior even to the observed accuracy of ReLU networks trained with the help of adversarial examples. In the absence of adversarial attacks, MWD networks match the performance of sigmoid networks, and have accuracy only slightly below that of ReLU networks.
Neural Networks with Structural Resistance to Adversarial Attacks
Sep 25, 2018



In adversarial attacks to machine-learning classifiers, small perturbations are added to input that is correctly classified. The perturbations yield adversarial examples, which are virtually indistinguishable from the unperturbed input, and yet are misclassified. In standard neural networks used for deep learning, attackers can craft adversarial examples from most input to cause a misclassification of their choice. We introduce a new type of network units, called RBFI units, whose non-linear structure makes them inherently resistant to adversarial attacks. On permutation-invariant MNIST, in absence of adversarial attacks, networks using RBFI units match the performance of networks using sigmoid units, and are slightly below the accuracy of networks with ReLU units. When subjected to adversarial attacks, networks with RBFI units retain accuracies above 90% for attacks that degrade the accuracy of networks with ReLU or sigmoid units to below 2%. RBFI networks trained with regular input are superior in their resistance to adversarial attacks even to ReLU and sigmoid networks trained with the help of adversarial examples. The non-linear structure of RBFI units makes them difficult to train using standard gradient descent. We show that networks of RBFI units can be efficiently trained to high accuracies using pseudogradients, computed using functions especially crafted to facilitate learning instead of their true derivatives. We show that the use of pseudogradients makes training deep RBFI networks practical, and we compare several structural alternatives of RBFI networks for their accuracy.
Some Like it Hoax: Automated Fake News Detection in Social Networks
Apr 25, 2017



In recent years, the reliability of information on the Internet has emerged as a crucial issue of modern society. Social network sites (SNSs) have revolutionized the way in which information is spread by allowing users to freely share content. As a consequence, SNSs are also increasingly used as vectors for the diffusion of misinformation and hoaxes. The amount of disseminated information and the rapidity of its diffusion make it practically impossible to assess reliability in a timely manner, highlighting the need for automatic hoax detection systems. As a contribution towards this objective, we show that Facebook posts can be classified with high accuracy as hoaxes or non-hoaxes on the basis of the users who "liked" them. We present two classification techniques, one based on logistic regression, the other on a novel adaptation of boolean crowdsourcing algorithms. On a dataset consisting of 15,500 Facebook posts and 909,236 users, we obtain classification accuracies exceeding 99% even when the training set contains less than 1% of the posts. We further show that our techniques are robust: they work even when we restrict our attention to the users who like both hoax and non-hoax posts. These results suggest that mapping the diffusion pattern of information can be a useful component of automatic hoax detection systems.
Learning From Graph Neighborhoods Using LSTMs
Nov 21, 2016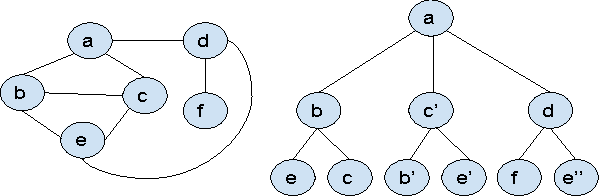
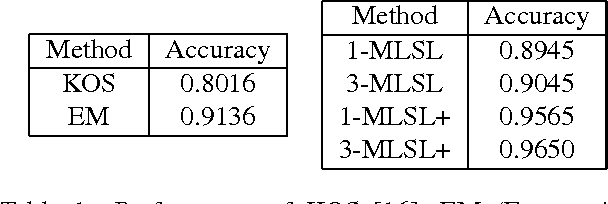
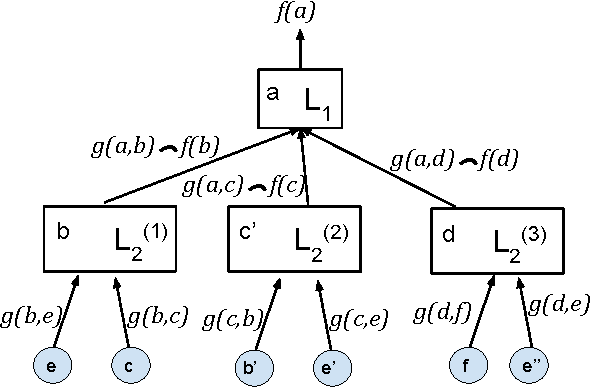
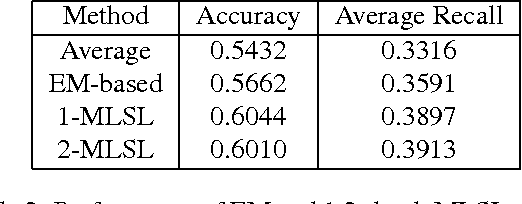
Many prediction problems can be phrased as inferences over local neighborhoods of graphs. The graph represents the interaction between entities, and the neighborhood of each entity contains information that allows the inferences or predictions. We present an approach for applying machine learning directly to such graph neighborhoods, yielding predicitons for graph nodes on the basis of the structure of their local neighborhood and the features of the nodes in it. Our approach allows predictions to be learned directly from examples, bypassing the step of creating and tuning an inference model or summarizing the neighborhoods via a fixed set of hand-crafted features. The approach is based on a multi-level architecture built from Long Short-Term Memory neural nets (LSTMs); the LSTMs learn how to summarize the neighborhood from data. We demonstrate the effectiveness of the proposed technique on a synthetic example and on real-world data related to crowdsourced grading, Bitcoin transactions, and Wikipedia edit reversions.