 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIdentifying Fake News from Twitter Sharing Data: A Large-Scale Study
Feb 10, 2019
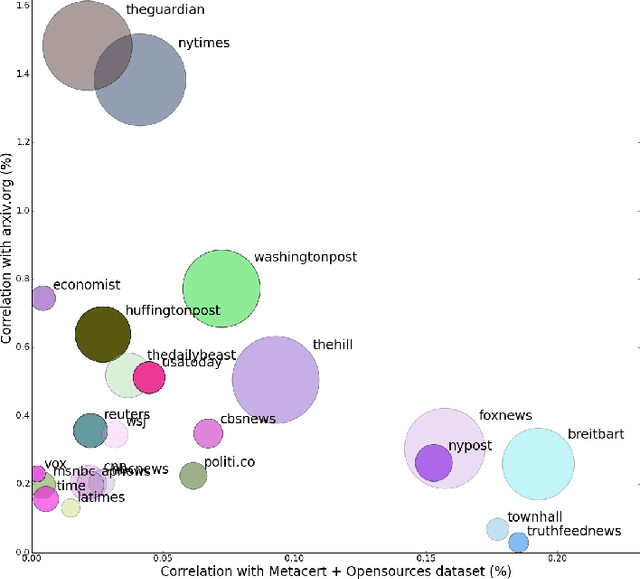

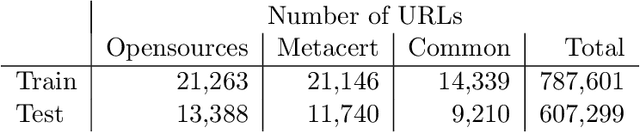
Social networks offer a ready channel for fake and misleading news to spread and exert influence. This paper examines the performance of different reputation algorithms when applied to a large and statistically significant portion of the news that are spread via Twitter. Our main result is that simple crowdsourcing-based algorithms are able to identify a large portion of fake or misleading news, while incurring only very low false positive rates for mainstream websites. We believe that these algorithms can be used as the basis of practical, large-scale systems for indicating to consumers which news sites deserve careful scrutiny and skepticism.
Some Like it Hoax: Automated Fake News Detection in Social Networks
Apr 25, 2017



In recent years, the reliability of information on the Internet has emerged as a crucial issue of modern society. Social network sites (SNSs) have revolutionized the way in which information is spread by allowing users to freely share content. As a consequence, SNSs are also increasingly used as vectors for the diffusion of misinformation and hoaxes. The amount of disseminated information and the rapidity of its diffusion make it practically impossible to assess reliability in a timely manner, highlighting the need for automatic hoax detection systems. As a contribution towards this objective, we show that Facebook posts can be classified with high accuracy as hoaxes or non-hoaxes on the basis of the users who "liked" them. We present two classification techniques, one based on logistic regression, the other on a novel adaptation of boolean crowdsourcing algorithms. On a dataset consisting of 15,500 Facebook posts and 909,236 users, we obtain classification accuracies exceeding 99% even when the training set contains less than 1% of the posts. We further show that our techniques are robust: they work even when we restrict our attention to the users who like both hoax and non-hoax posts. These results suggest that mapping the diffusion pattern of information can be a useful component of automatic hoax detection systems.