Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIdentifying Fake News from Twitter Sharing Data: A Large-Scale Study
Paper and Code
Feb 10, 2019
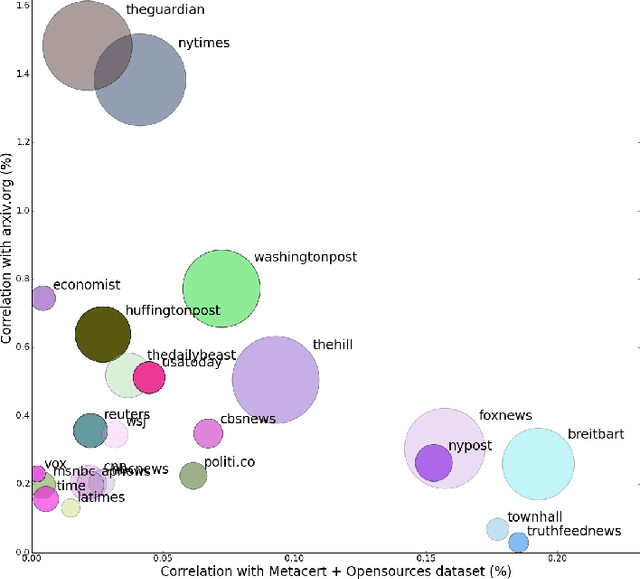

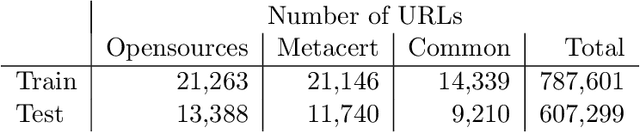
Social networks offer a ready channel for fake and misleading news to spread and exert influence. This paper examines the performance of different reputation algorithms when applied to a large and statistically significant portion of the news that are spread via Twitter. Our main result is that simple crowdsourcing-based algorithms are able to identify a large portion of fake or misleading news, while incurring only very low false positive rates for mainstream websites. We believe that these algorithms can be used as the basis of practical, large-scale systems for indicating to consumers which news sites deserve careful scrutiny and skepticism.
* arXiv admin note: substantial text overlap with arXiv:1802.08066
View paper on