 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe MAMA-MIA Challenge: Advancing Generalizability and Fairness in Breast MRI Tumor Segmentation and Treatment Response Prediction
Mar 01, 2026Breast cancer is the most frequently diagnosed malignancy among women worldwide and a leading cause of cancer-related mortality. Dynamic contrast-enhanced magnetic resonance imaging plays a central role in tumor characterization and treatment monitoring, particularly in patients receiving neoadjuvant chemotherapy. However, existing artificial intelligence models for breast magnetic resonance imaging are often developed using single-center data and evaluated using aggregate performance metrics, limiting their generalizability and obscuring potential performance disparities across demographic subgroups. The MAMA-MIA Challenge was designed to address these limitations by introducing a large-scale benchmark that jointly evaluates primary tumor segmentation and prediction of pathologic complete response using pre-treatment magnetic resonance imaging only. The training cohort comprised 1,506 patients from multiple institutions in the United States, while evaluation was conducted on an external test set of 574 patients from three independent European centers to assess cross-continental and cross-institutional generalization. A unified scoring framework combined predictive performance with subgroup consistency across age, menopausal status, and breast density. Twenty-six international teams participated in the final evaluation phase. Results demonstrate substantial performance variability under external testing and reveal trade-offs between overall accuracy and subgroup fairness. The challenge provides standardized datasets, evaluation protocols, and public resources to promote the development of robust and equitable artificial intelligence systems for breast cancer imaging.
HydroChronos: Forecasting Decades of Surface Water Change
Jun 17, 2025Forecasting surface water dynamics is crucial for water resource management and climate change adaptation. However, the field lacks comprehensive datasets and standardized benchmarks. In this paper, we introduce HydroChronos, a large-scale, multi-modal spatiotemporal dataset for surface water dynamics forecasting designed to address this gap. We couple the dataset with three forecasting tasks. The dataset includes over three decades of aligned Landsat 5 and Sentinel-2 imagery, climate data, and Digital Elevation Models for diverse lakes and rivers across Europe, North America, and South America. We also propose AquaClimaTempo UNet, a novel spatiotemporal architecture with a dedicated climate data branch, as a strong benchmark baseline. Our model significantly outperforms a Persistence baseline for forecasting future water dynamics by +14% and +11% F1 across change detection and direction of change classification tasks, and by +0.1 MAE on the magnitude of change regression. Finally, we conduct an Explainable AI analysis to identify the key climate variables and input channels that influence surface water change, providing insights to inform and guide future modeling efforts.
"KAN you hear me?" Exploring Kolmogorov-Arnold Networks for Spoken Language Understanding
May 26, 2025



Kolmogorov-Arnold Networks (KANs) have recently emerged as a promising alternative to traditional neural architectures, yet their application to speech processing remains under explored. This work presents the first investigation of KANs for Spoken Language Understanding (SLU) tasks. We experiment with 2D-CNN models on two datasets, integrating KAN layers in five different configurations within the dense block. The best-performing setup, which places a KAN layer between two linear layers, is directly applied to transformer-based models and evaluated on five SLU datasets with increasing complexity. Our results show that KAN layers can effectively replace the linear layers, achieving comparable or superior performance in most cases. Finally, we provide insights into how KAN and linear layers on top of transformers differently attend to input regions of the raw waveforms.
Detecting Interpretable Subgroup Drifts
Aug 26, 2024


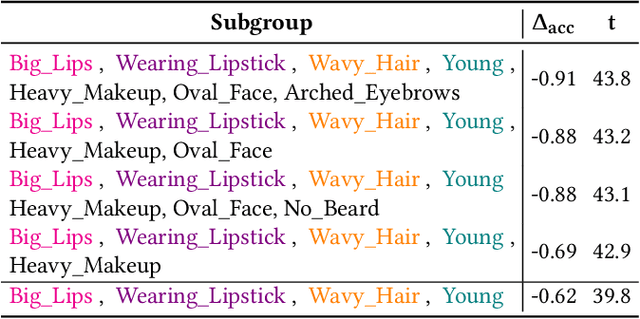
The ability to detect and adapt to changes in data distributions is crucial to maintain the accuracy and reliability of machine learning models. Detection is generally approached by observing the drift of model performance from a global point of view. However, drifts occurring in (fine-grained) data subgroups may go unnoticed when monitoring global drift. We take a different perspective, and introduce methods for observing drift at the finer granularity of subgroups. Relevant data subgroups are identified during training and monitored efficiently throughout the model's life. Performance drifts in any subgroup are detected, quantified and characterized so as to provide an interpretable summary of the model behavior over time. Experimental results confirm that our subgroup-level drift analysis identifies drifts that do not show at the (coarser) global dataset level. The proposed approach provides a valuable tool for monitoring model performance in dynamic real-world applications, offering insights into the evolving nature of data and ultimately contributing to more robust and adaptive models.
A Synthetic Benchmark to Explore Limitations of Localized Drift Detections
Aug 26, 2024Concept drift is a common phenomenon in data streams where the statistical properties of the target variable change over time. Traditionally, drift is assumed to occur globally, affecting the entire dataset uniformly. However, this assumption does not always hold true in real-world scenarios where only specific subpopulations within the data may experience drift. This paper explores the concept of localized drift and evaluates the performance of several drift detection techniques in identifying such localized changes. We introduce a synthetic dataset based on the Agrawal generator, where drift is induced in a randomly chosen subgroup. Our experiments demonstrate that commonly adopted drift detection methods may fail to detect drift when it is confined to a small subpopulation. We propose and test various drift detection approaches to quantify their effectiveness in this localized drift scenario. We make the source code for the generation of the synthetic benchmark available at https://github.com/fgiobergia/subgroup-agrawal-drift.
KAN You See It? KANs and Sentinel for Effective and Explainable Crop Field Segmentation
Aug 13, 2024Segmentation of crop fields is essential for enhancing agricultural productivity, monitoring crop health, and promoting sustainable practices. Deep learning models adopted for this task must ensure accurate and reliable predictions to avoid economic losses and environmental impact. The newly proposed Kolmogorov-Arnold networks (KANs) offer promising advancements in the performance of neural networks. This paper analyzes the integration of KAN layers into the U-Net architecture (U-KAN) to segment crop fields using Sentinel-2 and Sentinel-1 satellite images and provides an analysis of the performance and explainability of these networks. Our findings indicate a 2\% improvement in IoU compared to the traditional full-convolutional U-Net model in fewer GFLOPs. Furthermore, gradient-based explanation techniques show that U-KAN predictions are highly plausible and that the network has a very high ability to focus on the boundaries of cultivated areas rather than on the areas themselves. The per-channel relevance analysis also reveals that some channels are irrelevant to this task.
A Benchmarking Study of Kolmogorov-Arnold Networks on Tabular Data
Jun 20, 2024Kolmogorov-Arnold Networks (KANs) have very recently been introduced into the world of machine learning, quickly capturing the attention of the entire community. However, KANs have mostly been tested for approximating complex functions or processing synthetic data, while a test on real-world tabular datasets is currently lacking. In this paper, we present a benchmarking study comparing KANs and Multi-Layer Perceptrons (MLPs) on tabular datasets. The study evaluates task performance and training times. From the results obtained on the various datasets, KANs demonstrate superior or comparable accuracy and F1 scores, excelling particularly in datasets with numerous instances, suggesting robust handling of complex data. We also highlight that this performance improvement of KANs comes with a higher computational cost when compared to MLPs of comparable sizes.
A Contrastive Learning Approach to Mitigate Bias in Speech Models
Jun 20, 2024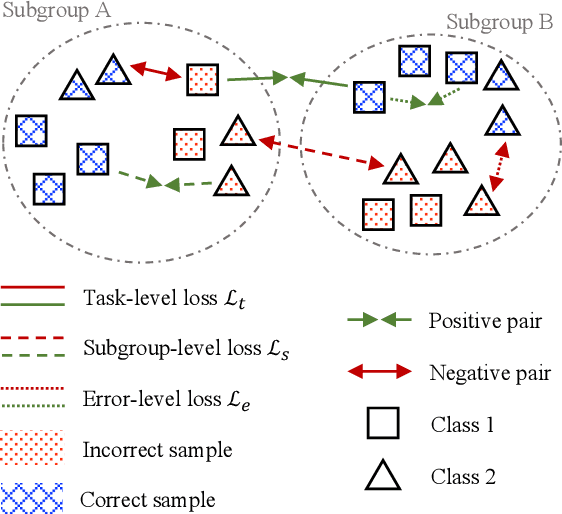


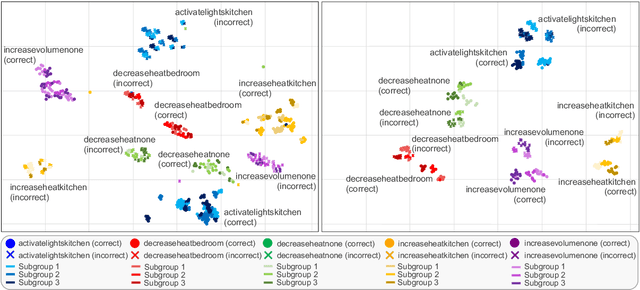
Speech models may be affected by performance imbalance in different population subgroups, raising concerns about fair treatment across these groups. Prior attempts to mitigate unfairness either focus on user-defined subgroups, potentially overlooking other affected subgroups, or do not explicitly improve the internal representation at the subgroup level. This paper proposes the first adoption of contrastive learning to mitigate speech model bias in underperforming subgroups. We employ a three-level learning technique that guides the model in focusing on different scopes for the contrastive loss, i.e., task, subgroup, and the errors within subgroups. The experiments on two spoken language understanding datasets and two languages demonstrate that our approach improves internal subgroup representations, thus reducing model bias and enhancing performance.
Concept-based Explainable Artificial Intelligence: A Survey
Dec 20, 2023The field of explainable artificial intelligence emerged in response to the growing need for more transparent and reliable models. However, using raw features to provide explanations has been disputed in several works lately, advocating for more user-understandable explanations. To address this issue, a wide range of papers proposing Concept-based eXplainable Artificial Intelligence (C-XAI) methods have arisen in recent years. Nevertheless, a unified categorization and precise field definition are still missing. This paper fills the gap by offering a thorough review of C-XAI approaches. We define and identify different concepts and explanation types. We provide a taxonomy identifying nine categories and propose guidelines for selecting a suitable category based on the development context. Additionally, we report common evaluation strategies including metrics, human evaluations and dataset employed, aiming to assist the development of future methods. We believe this survey will serve researchers, practitioners, and domain experts in comprehending and advancing this innovative field.
Explaining Speech Classification Models via Word-Level Audio Segments and Paralinguistic Features
Sep 14, 2023



Recent advances in eXplainable AI (XAI) have provided new insights into how models for vision, language, and tabular data operate. However, few approaches exist for understanding speech models. Existing work focuses on a few spoken language understanding (SLU) tasks, and explanations are difficult to interpret for most users. We introduce a new approach to explain speech classification models. We generate easy-to-interpret explanations via input perturbation on two information levels. 1) Word-level explanations reveal how each word-related audio segment impacts the outcome. 2) Paralinguistic features (e.g., prosody and background noise) answer the counterfactual: ``What would the model prediction be if we edited the audio signal in this way?'' We validate our approach by explaining two state-of-the-art SLU models on two speech classification tasks in English and Italian. Our findings demonstrate that the explanations are faithful to the model's inner workings and plausible to humans. Our method and findings pave the way for future research on interpreting speech models.