 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Contrastive Learning Approach to Mitigate Bias in Speech Models
Paper and Code
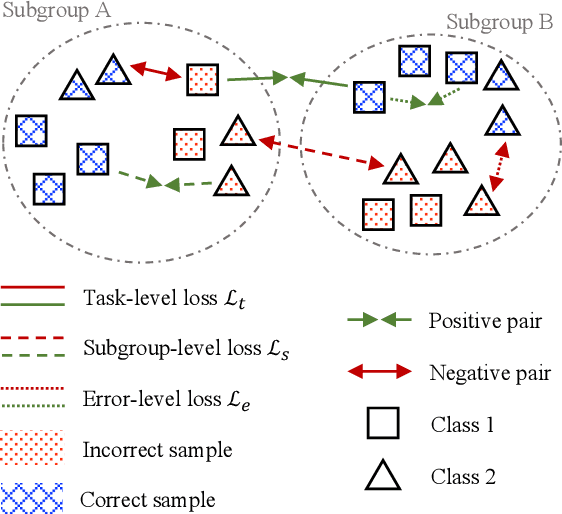


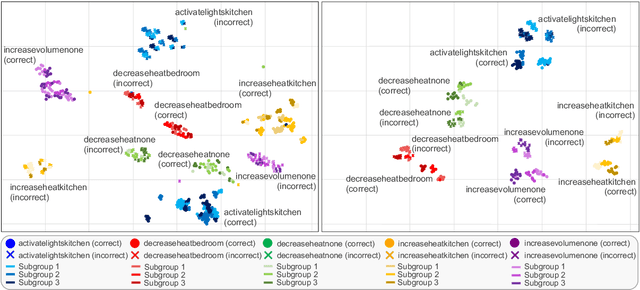
Speech models may be affected by performance imbalance in different population subgroups, raising concerns about fair treatment across these groups. Prior attempts to mitigate unfairness either focus on user-defined subgroups, potentially overlooking other affected subgroups, or do not explicitly improve the internal representation at the subgroup level. This paper proposes the first adoption of contrastive learning to mitigate speech model bias in underperforming subgroups. We employ a three-level learning technique that guides the model in focusing on different scopes for the contrastive loss, i.e., task, subgroup, and the errors within subgroups. The experiments on two spoken language understanding datasets and two languages demonstrate that our approach improves internal subgroup representations, thus reducing model bias and enhancing performance.