 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluating LLM-Based Goal Extraction in Requirements Engineering: Prompting Strategies and Their Limitations
Apr 24, 2026Due to the textual and repetitive nature of many Requirements Engineering (RE) artefacts, Large Language Models (LLMs) have proven useful to automate their generation and processing. In this paper, we discuss a possible approach for automating the Goal-Oriented Requirements Engineering (GORE) process by extracting functional goals from software documentation through three phases: actor identification, high and low-level goal extraction. To implement these functionalities, we propose a chain of LLMs fed with engineered prompts. We experimented with different variants of in-context learning and measured the similarities between input data and in-context examples to better investigate their impact. Another key element is the generation-critic mechanism, implemented as a feedback loop involving two LLMs. Although the pipeline achieved 61% accuracy in low-level goal identification, the final stage, these results indicate the approach is best suited as a tool to accelerate manual extraction rather than as a full replacement. The feedback-loop mechanism with Zero-shot outperformed stand-alone Few-shot, with an ablation study suggesting that performance slightly degrades without the feedback cycle. However, we reported that the combination of the feedback mechanism with Few-shot does not deliver any advantage, possibly suggesting that the primary performance ceiling is the prompting strategy applied to the 'critic' LLM. Together with the refinement of both the quantity and quality of the Shot examples, future research will integrate Retrieval-Augmented Generation (RAG) and Chain-of-Thought (CoT) prompting to improve accuracy.
Analysis Of Linguistic Stereotypes in Single and Multi-Agent Generative AI Architectures
Mar 19, 2026Many works in the literature show that LLM outputs exhibit discriminatory behaviour, triggering stereotype-based inferences based on the dialect in which the inputs are written. This bias has been shown to be particularly pronounced when the same inputs are provided to LLMs in Standard American English (SAE) and African-American English (AAE). In this paper, we replicate existing analyses of dialect-sensitive stereotype generation in LLM outputs and investigate the effects of mitigation strategies, including prompt engineering (role-based and Chain-Of-Thought prompting) and multi-agent architectures composed of generate-critique-revise models. We define eight prompt templates to analyse different ways in which dialect bias can manifest, such as suggested names, jobs, and adjectives for SAE or AAE speakers. We use an LLM-as-judge approach to evaluate the bias in the results. Our results show that stereotype-bearing differences emerge between SAE- and AAE-related outputs across all template categories, with the strongest effects observed in adjective and job attribution. Baseline disparities vary substantially by model, with the largest SAE-AAE differential observed in Claude Haiku and the smallest in Phi-4 Mini. Chain-Of-Thought prompting proved to be an effective mitigation strategy for Claude Haiku, whereas the use of a multi-agent architecture ensured consistent mitigation across all the models. These findings suggest that for intersectionality-informed software engineering, fairness evaluation should include model-specific validation of mitigation strategies, and workflow-level controls (e.g., agentic architectures involving critique models) in high-impact LLM deployments. The current results are exploratory in nature and limited in scope, but can lead to extensions and replications by increasing the dataset size and applying the procedure to different languages or dialects.
FAME: Fictional Actors for Multilingual Erasure
Dec 17, 2025LLMs trained on web-scale data raise concerns about privacy and the right to be forgotten. To address these issues, Machine Unlearning provides techniques to remove specific information from trained models without retraining from scratch. However, existing benchmarks for evaluating unlearning in LLMs face two major limitations: they focus only on English and support only entity-level forgetting (removing all information about a person). We introduce FAME (Fictional Actors for Multilingual Erasure), a synthetic benchmark for evaluating Machine Unlearning across five languages: English, French, German, Italian, and Spanish. FAME contains 1,000 fictional actor biographies and 20,000 question-answer pairs. Each biography includes information on 20 topics organized into structured categories (biography, career, achievements, personal information). This design enables both entity-level unlearning (i.e., forgetting entire identities) and instance-level unlearning (i.e., forgetting specific facts while retaining others). We provide two dataset splits to support these two different unlearning scenarios and enable systematic comparison of unlearning techniques across languages. Since FAME uses entirely fictional data, it ensures that the information was never encountered during model pretraining, allowing for a controlled evaluation of unlearning methods.
"Alexa, can you forget me?" Machine Unlearning Benchmark in Spoken Language Understanding
May 21, 2025Machine unlearning, the process of efficiently removing specific information from machine learning models, is a growing area of interest for responsible AI. However, few studies have explored the effectiveness of unlearning methods on complex tasks, particularly speech-related ones. This paper introduces UnSLU-BENCH, the first benchmark for machine unlearning in spoken language understanding (SLU), focusing on four datasets spanning four languages. We address the unlearning of data from specific speakers as a way to evaluate the quality of potential "right to be forgotten" requests. We assess eight unlearning techniques and propose a novel metric to simultaneously better capture their efficacy, utility, and efficiency. UnSLU-BENCH sets a foundation for unlearning in SLU and reveals significant differences in the effectiveness and computational feasibility of various techniques.
A Synthetic Benchmark to Explore Limitations of Localized Drift Detections
Aug 26, 2024Concept drift is a common phenomenon in data streams where the statistical properties of the target variable change over time. Traditionally, drift is assumed to occur globally, affecting the entire dataset uniformly. However, this assumption does not always hold true in real-world scenarios where only specific subpopulations within the data may experience drift. This paper explores the concept of localized drift and evaluates the performance of several drift detection techniques in identifying such localized changes. We introduce a synthetic dataset based on the Agrawal generator, where drift is induced in a randomly chosen subgroup. Our experiments demonstrate that commonly adopted drift detection methods may fail to detect drift when it is confined to a small subpopulation. We propose and test various drift detection approaches to quantify their effectiveness in this localized drift scenario. We make the source code for the generation of the synthetic benchmark available at https://github.com/fgiobergia/subgroup-agrawal-drift.
Detecting Interpretable Subgroup Drifts
Aug 26, 2024


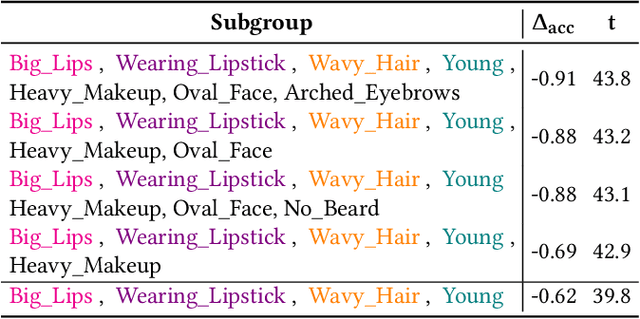
The ability to detect and adapt to changes in data distributions is crucial to maintain the accuracy and reliability of machine learning models. Detection is generally approached by observing the drift of model performance from a global point of view. However, drifts occurring in (fine-grained) data subgroups may go unnoticed when monitoring global drift. We take a different perspective, and introduce methods for observing drift at the finer granularity of subgroups. Relevant data subgroups are identified during training and monitored efficiently throughout the model's life. Performance drifts in any subgroup are detected, quantified and characterized so as to provide an interpretable summary of the model behavior over time. Experimental results confirm that our subgroup-level drift analysis identifies drifts that do not show at the (coarser) global dataset level. The proposed approach provides a valuable tool for monitoring model performance in dynamic real-world applications, offering insights into the evolving nature of data and ultimately contributing to more robust and adaptive models.
A Benchmarking Study of Kolmogorov-Arnold Networks on Tabular Data
Jun 20, 2024Kolmogorov-Arnold Networks (KANs) have very recently been introduced into the world of machine learning, quickly capturing the attention of the entire community. However, KANs have mostly been tested for approximating complex functions or processing synthetic data, while a test on real-world tabular datasets is currently lacking. In this paper, we present a benchmarking study comparing KANs and Multi-Layer Perceptrons (MLPs) on tabular datasets. The study evaluates task performance and training times. From the results obtained on the various datasets, KANs demonstrate superior or comparable accuracy and F1 scores, excelling particularly in datasets with numerous instances, suggesting robust handling of complex data. We also highlight that this performance improvement of KANs comes with a higher computational cost when compared to MLPs of comparable sizes.
A Contrastive Learning Approach to Mitigate Bias in Speech Models
Jun 20, 2024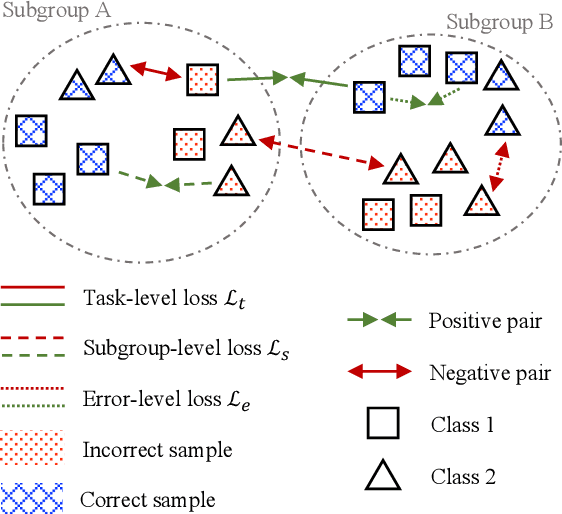


Speech models may be affected by performance imbalance in different population subgroups, raising concerns about fair treatment across these groups. Prior attempts to mitigate unfairness either focus on user-defined subgroups, potentially overlooking other affected subgroups, or do not explicitly improve the internal representation at the subgroup level. This paper proposes the first adoption of contrastive learning to mitigate speech model bias in underperforming subgroups. We employ a three-level learning technique that guides the model in focusing on different scopes for the contrastive loss, i.e., task, subgroup, and the errors within subgroups. The experiments on two spoken language understanding datasets and two languages demonstrate that our approach improves internal subgroup representations, thus reducing model bias and enhancing performance.
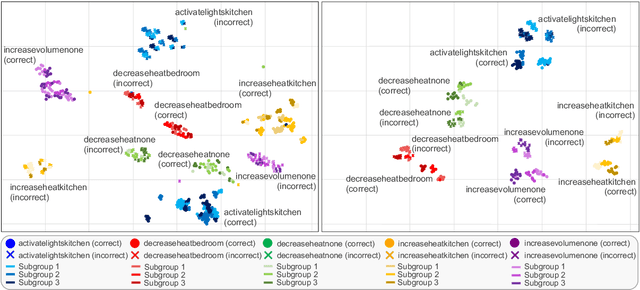
Houston we have a Divergence: A Subgroup Performance Analysis of ASR Models
Mar 31, 2024The Fearless Steps APOLLO Community Resource provides unparalleled opportunities to explore the potential of multi-speaker team communications from NASA Apollo missions. This study focuses on discovering the characteristics that make Apollo recordings more or less intelligible to Automatic Speech Recognition (ASR) methods. We extract, for each audio recording, interpretable metadata on recordings (signal-to-noise ratio, spectral flatness, presence of pauses, sentence duration), transcript (number of words spoken, speaking rate), or known a priori (speaker). We identify subgroups of audio recordings based on combinations of these metadata and compute each subgroup's performance (e.g., Word Error Rate) and the difference in performance (''divergence'') w.r.t the overall population. We then apply the Whisper model in different sizes, trained on English-only or multilingual datasets, in zero-shot or after fine-tuning. We conduct several analyses to (i) automatically identify and describe the most problematic subgroups for a given model, (ii) examine the impact of fine-tuning w.r.t. zero-shot at the subgroup level, (iii) understand the effect of model size on subgroup performance, and (iv) analyze if multilingual models are more sensitive than monolingual to subgroup performance disparities. The insights enhance our understanding of subgroup-specific performance variations, paving the way for advancements in optimizing ASR systems for Earth-to-space communications.
MALTO at SemEval-2024 Task 6: Leveraging Synthetic Data for LLM Hallucination Detection
Mar 01, 2024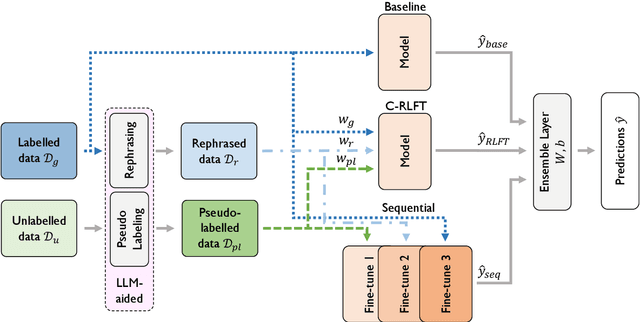



In Natural Language Generation (NLG), contemporary Large Language Models (LLMs) face several challenges, such as generating fluent yet inaccurate outputs and reliance on fluency-centric metrics. This often leads to neural networks exhibiting "hallucinations". The SHROOM challenge focuses on automatically identifying these hallucinations in the generated text. To tackle these issues, we introduce two key components, a data augmentation pipeline incorporating LLM-assisted pseudo-labelling and sentence rephrasing, and a voting ensemble from three models pre-trained on Natural Language Inference (NLI) tasks and fine-tuned on diverse datasets.