 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFAME: Fictional Actors for Multilingual Erasure
Dec 17, 2025LLMs trained on web-scale data raise concerns about privacy and the right to be forgotten. To address these issues, Machine Unlearning provides techniques to remove specific information from trained models without retraining from scratch. However, existing benchmarks for evaluating unlearning in LLMs face two major limitations: they focus only on English and support only entity-level forgetting (removing all information about a person). We introduce FAME (Fictional Actors for Multilingual Erasure), a synthetic benchmark for evaluating Machine Unlearning across five languages: English, French, German, Italian, and Spanish. FAME contains 1,000 fictional actor biographies and 20,000 question-answer pairs. Each biography includes information on 20 topics organized into structured categories (biography, career, achievements, personal information). This design enables both entity-level unlearning (i.e., forgetting entire identities) and instance-level unlearning (i.e., forgetting specific facts while retaining others). We provide two dataset splits to support these two different unlearning scenarios and enable systematic comparison of unlearning techniques across languages. Since FAME uses entirely fictional data, it ensures that the information was never encountered during model pretraining, allowing for a controlled evaluation of unlearning methods.
Confabulations from ACL Publications (CAP): A Dataset for Scientific Hallucination Detection
Oct 25, 2025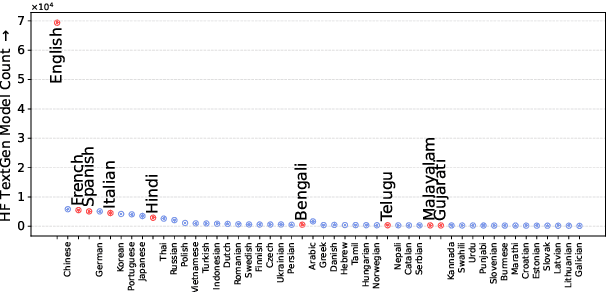
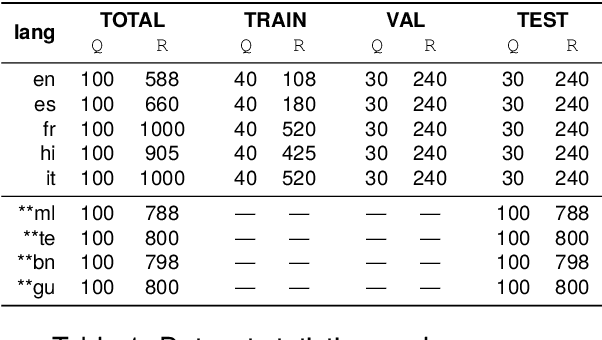

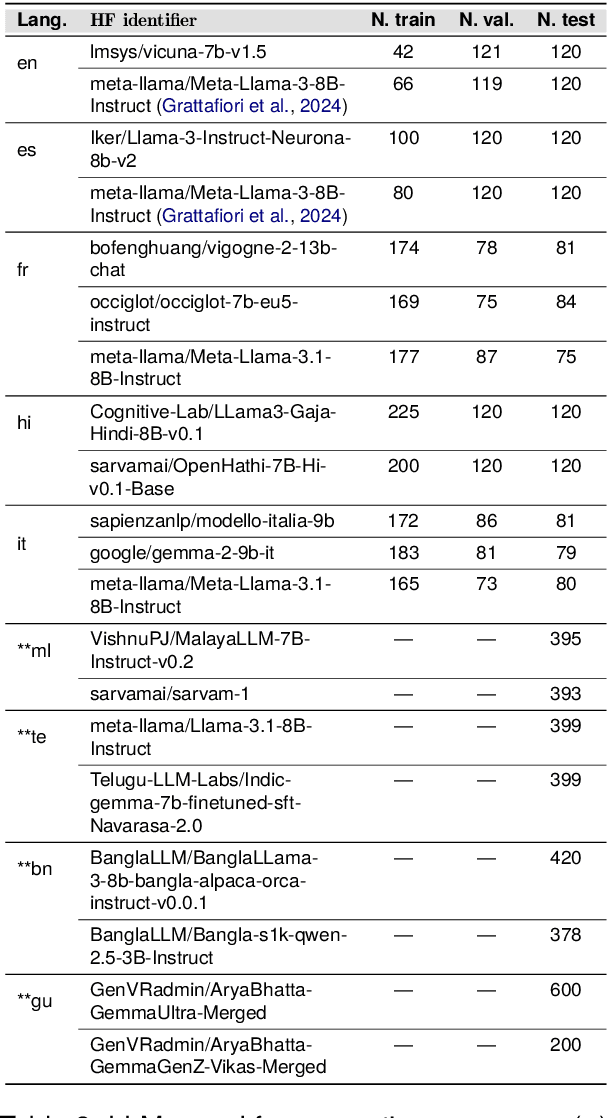
We introduce the CAP (Confabulations from ACL Publications) dataset, a multilingual resource for studying hallucinations in large language models (LLMs) within scientific text generation. CAP focuses on the scientific domain, where hallucinations can distort factual knowledge, as they frequently do. In this domain, however, the presence of specialized terminology, statistical reasoning, and context-dependent interpretations further exacerbates these distortions, particularly given LLMs' lack of true comprehension, limited contextual understanding, and bias toward surface-level generalization. CAP operates in a cross-lingual setting covering five high-resource languages (English, French, Hindi, Italian, and Spanish) and four low-resource languages (Bengali, Gujarati, Malayalam, and Telugu). The dataset comprises 900 curated scientific questions and over 7000 LLM-generated answers from 16 publicly available models, provided as question-answer pairs along with token sequences and corresponding logits. Each instance is annotated with a binary label indicating the presence of a scientific hallucination, denoted as a factuality error, and a fluency label, capturing issues in the linguistic quality or naturalness of the text. CAP is publicly released to facilitate advanced research on hallucination detection, multilingual evaluation of LLMs, and the development of more reliable scientific NLP systems.
"Alexa, can you forget me?" Machine Unlearning Benchmark in Spoken Language Understanding
May 21, 2025Machine unlearning, the process of efficiently removing specific information from machine learning models, is a growing area of interest for responsible AI. However, few studies have explored the effectiveness of unlearning methods on complex tasks, particularly speech-related ones. This paper introduces UnSLU-BENCH, the first benchmark for machine unlearning in spoken language understanding (SLU), focusing on four datasets spanning four languages. We address the unlearning of data from specific speakers as a way to evaluate the quality of potential "right to be forgotten" requests. We assess eight unlearning techniques and propose a novel metric to simultaneously better capture their efficacy, utility, and efficiency. UnSLU-BENCH sets a foundation for unlearning in SLU and reveals significant differences in the effectiveness and computational feasibility of various techniques.
Volvo Discovery Challenge at ECML-PKDD 2024
Sep 17, 2024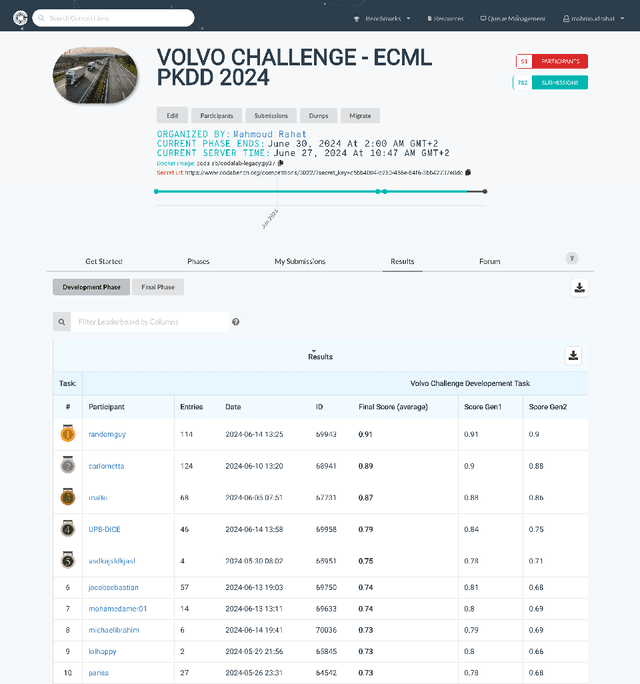


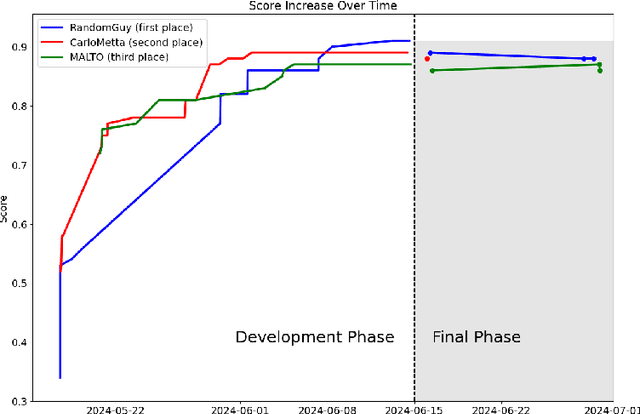
This paper presents an overview of the Volvo Discovery Challenge, held during the ECML-PKDD 2024 conference. The challenge's goal was to predict the failure risk of an anonymized component in Volvo trucks using a newly published dataset. The test data included observations from two generations (gen1 and gen2) of the component, while the training data was provided only for gen1. The challenge attracted 52 data scientists from around the world who submitted a total of 791 entries. We provide a brief description of the problem definition, challenge setup, and statistics about the submissions. In the section on winning methodologies, the first, second, and third-place winners of the competition briefly describe their proposed methods and provide GitHub links to their implemented code. The shared code can be interesting as an advanced methodology for researchers in the predictive maintenance domain. The competition was hosted on the Codabench platform.
MALTO at SemEval-2024 Task 6: Leveraging Synthetic Data for LLM Hallucination Detection
Mar 01, 2024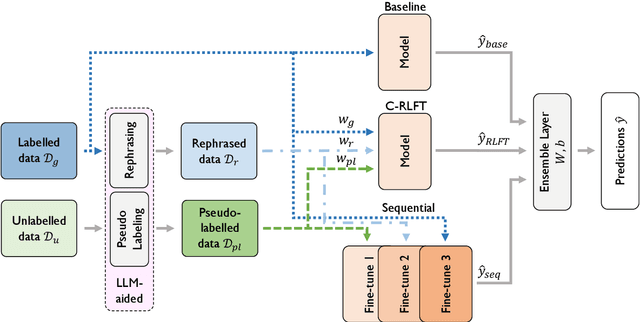



In Natural Language Generation (NLG), contemporary Large Language Models (LLMs) face several challenges, such as generating fluent yet inaccurate outputs and reliance on fluency-centric metrics. This often leads to neural networks exhibiting "hallucinations". The SHROOM challenge focuses on automatically identifying these hallucinations in the generated text. To tackle these issues, we introduce two key components, a data augmentation pipeline incorporating LLM-assisted pseudo-labelling and sentence rephrasing, and a voting ensemble from three models pre-trained on Natural Language Inference (NLI) tasks and fine-tuned on diverse datasets.