 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAttribution Upsampling should Redistribute, Not Interpolate
Mar 17, 2026Attribution methods in explainable AI rely on upsampling techniques that were designed for natural images, not saliency maps. Standard bilinear and bicubic interpolation systematically corrupts attribution signals through aliasing, ringing, and boundary bleeding, producing spurious high-importance regions that misrepresent model reasoning. We identify that the core issue is treating attribution upsampling as an interpolation problem that operates in isolation from the model's reasoning, rather than a mass redistribution problem where model-derived semantic boundaries must govern how importance flows. We present Universal Semantic-Aware Upsampling (USU), a principled method that reformulates upsampling through ratio-form mass redistribution operators, provably preserving attribution mass and relative importance ordering. Extending the axiomatic tradition of feature attribution to upsampling, we formalize four desiderata for faithful upsampling and prove that interpolation structurally violates three of them. These same three force any redistribution operator into a ratio form; the fourth selects the unique potential within this family, yielding USU. Controlled experiments on models with known attribution priors verify USU's formal guarantees; evaluation across ImageNet, CIFAR-10, and CUB-200 confirms consistent faithfulness improvements and qualitatively superior, semantically coherent explanations.
Volvo Discovery Challenge at ECML-PKDD 2024
Sep 17, 2024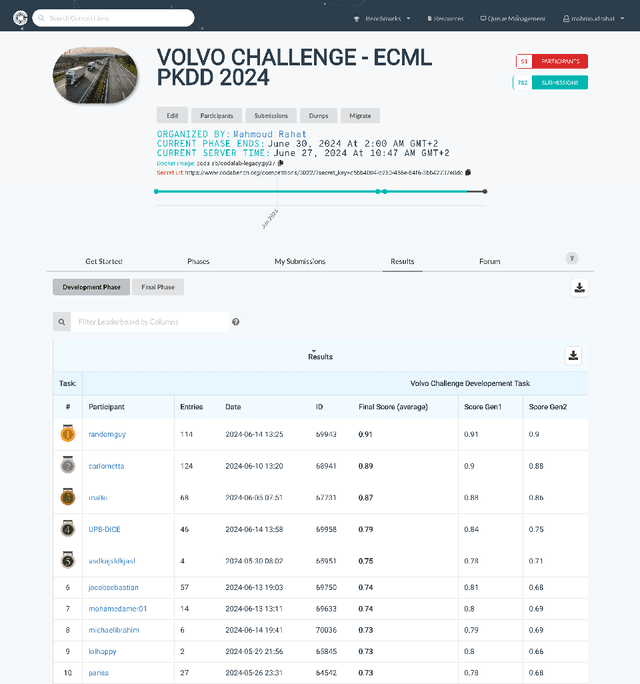


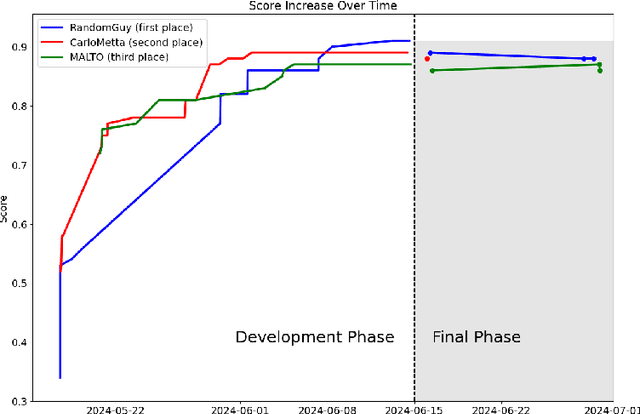
This paper presents an overview of the Volvo Discovery Challenge, held during the ECML-PKDD 2024 conference. The challenge's goal was to predict the failure risk of an anonymized component in Volvo trucks using a newly published dataset. The test data included observations from two generations (gen1 and gen2) of the component, while the training data was provided only for gen1. The challenge attracted 52 data scientists from around the world who submitted a total of 791 entries. We provide a brief description of the problem definition, challenge setup, and statistics about the submissions. In the section on winning methodologies, the first, second, and third-place winners of the competition briefly describe their proposed methods and provide GitHub links to their implemented code. The shared code can be interesting as an advanced methodology for researchers in the predictive maintenance domain. The competition was hosted on the Codabench platform.
Expected Grad-CAM: Towards gradient faithfulness
Jun 03, 2024Although input-gradients techniques have evolved to mitigate and tackle the challenges associated with gradients, modern gradient-weighted CAM approaches still rely on vanilla gradients, which are inherently susceptible to the saturation phenomena. Despite recent enhancements have incorporated counterfactual gradient strategies as a mitigating measure, these local explanation techniques still exhibit a lack of sensitivity to their baseline parameter. Our work proposes a gradient-weighted CAM augmentation that tackles both the saturation and sensitivity problem by reshaping the gradient computation, incorporating two well-established and provably approaches: Expected Gradients and kernel smoothing. By revisiting the original formulation as the smoothed expectation of the perturbed integrated gradients, one can concurrently construct more faithful, localized and robust explanations which minimize infidelity. Through fine modulation of the perturbation distribution it is possible to regulate the complexity characteristic of the explanation, selectively discriminating stable features. Our technique, Expected Grad-CAM, differently from recent works, exclusively optimizes the gradient computation, purposefully designed as an enhanced substitute of the foundational Grad-CAM algorithm and any method built therefrom. Quantitative and qualitative evaluations have been conducted to assess the effectiveness of our method.