 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Geometry of Representational Failures in Vision Language Models
Feb 02, 2026Vision-Language Models (VLMs) exhibit puzzling failures in multi-object visual tasks, such as hallucinating non-existent elements or failing to identify the most similar objects among distractions. While these errors mirror human cognitive constraints, such as the "Binding Problem", the internal mechanisms driving them in artificial systems remain poorly understood. Here, we propose a mechanistic insight by analyzing the representational geometry of open-weight VLMs (Qwen, InternVL, Gemma), comparing methodologies to distill "concept vectors" - latent directions encoding visual concepts. We validate our concept vectors via steering interventions that reliably manipulate model behavior in both simplified and naturalistic vision tasks (e.g., forcing the model to perceive a red flower as blue). We observe that the geometric overlap between these vectors strongly correlates with specific error patterns, offering a grounded quantitative framework to understand how internal representations shape model behavior and drive visual failures.
Size-adaptive Hypothesis Testing for Fairness
Jun 12, 2025



Determining whether an algorithmic decision-making system discriminates against a specific demographic typically involves comparing a single point estimate of a fairness metric against a predefined threshold. This practice is statistically brittle: it ignores sampling error and treats small demographic subgroups the same as large ones. The problem intensifies in intersectional analyses, where multiple sensitive attributes are considered jointly, giving rise to a larger number of smaller groups. As these groups become more granular, the data representing them becomes too sparse for reliable estimation, and fairness metrics yield excessively wide confidence intervals, precluding meaningful conclusions about potential unfair treatments. In this paper, we introduce a unified, size-adaptive, hypothesis-testing framework that turns fairness assessment into an evidence-based statistical decision. Our contribution is twofold. (i) For sufficiently large subgroups, we prove a Central-Limit result for the statistical parity difference, leading to analytic confidence intervals and a Wald test whose type-I (false positive) error is guaranteed at level $\alpha$. (ii) For the long tail of small intersectional groups, we derive a fully Bayesian Dirichlet-multinomial estimator; Monte-Carlo credible intervals are calibrated for any sample size and naturally converge to Wald intervals as more data becomes available. We validate our approach empirically on benchmark datasets, demonstrating how our tests provide interpretable, statistically rigorous decisions under varying degrees of data availability and intersectionality.
Learning Individual Behavior in Agent-Based Models with Graph Diffusion Networks
May 27, 2025
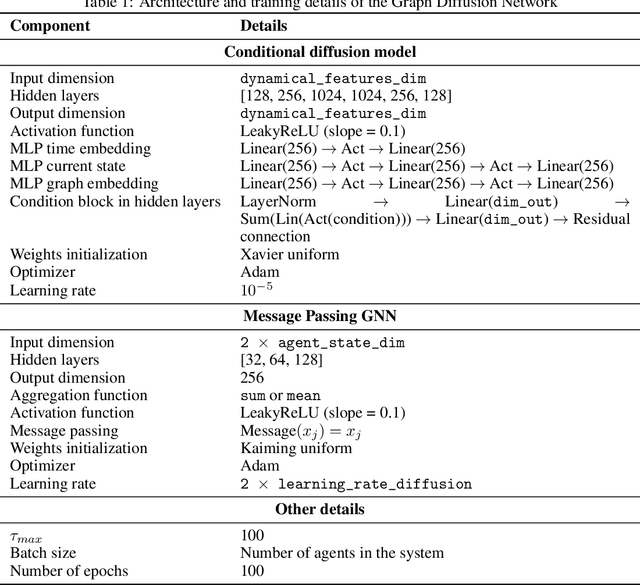

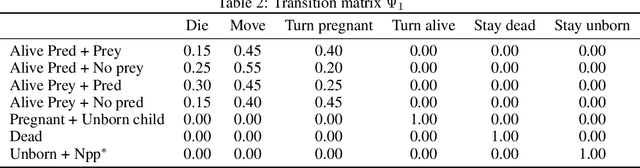
Agent-Based Models (ABMs) are powerful tools for studying emergent properties in complex systems. In ABMs, agent behaviors are governed by local interactions and stochastic rules. However, these rules are, in general, non-differentiable, limiting the use of gradient-based methods for optimization, and thus integration with real-world data. We propose a novel framework to learn a differentiable surrogate of any ABM by observing its generated data. Our method combines diffusion models to capture behavioral stochasticity and graph neural networks to model agent interactions. Distinct from prior surrogate approaches, our method introduces a fundamental shift: rather than approximating system-level outputs, it models individual agent behavior directly, preserving the decentralized, bottom-up dynamics that define ABMs. We validate our approach on two ABMs (Schelling's segregation model and a Predator-Prey ecosystem) showing that it replicates individual-level patterns and accurately forecasts emergent dynamics beyond training. Our results demonstrate the potential of combining diffusion models and graph learning for data-driven ABM simulation.
Explainable Emotion Decoding for Human and Computer Vision
Aug 01, 2024



Modern Machine Learning (ML) has significantly advanced various research fields, but the opaque nature of ML models hinders their adoption in several domains. Explainable AI (XAI) addresses this challenge by providing additional information to help users understand the internal decision-making process of ML models. In the field of neuroscience, enriching a ML model for brain decoding with attribution-based XAI techniques means being able to highlight which brain areas correlate with the task at hand, thus offering valuable insights to domain experts. In this paper, we analyze human and Computer Vision (CV) systems in parallel, training and explaining two ML models based respectively on functional Magnetic Resonance Imaging (fMRI) and movie frames. We do so by leveraging the "StudyForrest" dataset, which includes functional Magnetic Resonance Imaging (fMRI) scans of subjects watching the "Forrest Gump" movie, emotion annotations, and eye-tracking data. For human vision the ML task is to link fMRI data with emotional annotations, and the explanations highlight the brain regions strongly correlated with the label. On the other hand, for computer vision, the input data is movie frames, and the explanations are pixel-level heatmaps. We cross-analyzed our results, linking human attention (obtained through eye-tracking) with XAI saliency on CV models and brain region activations. We show how a parallel analysis of human and computer vision can provide useful information for both the neuroscience community (allocation theory) and the ML community (biological plausibility of convolutional models).
HOLMES: HOLonym-MEronym based Semantic inspection for Convolutional Image Classifiers
Mar 13, 2024Convolutional Neural Networks (CNNs) are nowadays the model of choice in Computer Vision, thanks to their ability to automatize the feature extraction process in visual tasks. However, the knowledge acquired during training is fully subsymbolic, and hence difficult to understand and explain to end users. In this paper, we propose a new technique called HOLMES (HOLonym-MEronym based Semantic inspection) that decomposes a label into a set of related concepts, and provides component-level explanations for an image classification model. Specifically, HOLMES leverages ontologies, web scraping and transfer learning to automatically construct meronym (parts)-based detectors for a given holonym (class). Then, it produces heatmaps at the meronym level and finally, by probing the holonym CNN with occluded images, it highlights the importance of each part on the classification output. Compared to state-of-the-art saliency methods, HOLMES takes a step further and provides information about both where and what the holonym CNN is looking at, without relying on densely annotated datasets and without forcing concepts to be associated to single computational units. Extensive experimental evaluation on different categories of objects (animals, tools and vehicles) shows the feasibility of our approach. On average, HOLMES explanations include at least two meronyms, and the ablation of a single meronym roughly halves the holonym model confidence. The resulting heatmaps were quantitatively evaluated using the deletion/insertion/preservation curves. All metrics were comparable to those achieved by GradCAM, while offering the advantage of further decomposing the heatmap in human-understandable concepts, thus highlighting both the relevance of meronyms to object classification, as well as HOLMES ability to capture it. The code is available at https://github.com/FrancesC0de/HOLMES.
* This work has been accepted to be presented to The 1st World Conference on eXplainable Artificial Intelligence (xAI 2023), July 26-28, 2023 - Lisboa, Portugal
Evaluating Link Prediction Explanations for Graph Neural Networks
Aug 03, 2023Graph Machine Learning (GML) has numerous applications, such as node/graph classification and link prediction, in real-world domains. Providing human-understandable explanations for GML models is a challenging yet fundamental task to foster their adoption, but validating explanations for link prediction models has received little attention. In this paper, we provide quantitative metrics to assess the quality of link prediction explanations, with or without ground-truth. State-of-the-art explainability methods for Graph Neural Networks are evaluated using these metrics. We discuss how underlying assumptions and technical details specific to the link prediction task, such as the choice of distance between node embeddings, can influence the quality of the explanations.
Beyond One-Hot-Encoding: Injecting Semantics to Drive Image Classifiers
Aug 01, 2023



Images are loaded with semantic information that pertains to real-world ontologies: dog breeds share mammalian similarities, food pictures are often depicted in domestic environments, and so on. However, when training machine learning models for image classification, the relative similarities amongst object classes are commonly paired with one-hot-encoded labels. According to this logic, if an image is labelled as 'spoon', then 'tea-spoon' and 'shark' are equally wrong in terms of training loss. To overcome this limitation, we explore the integration of additional goals that reflect ontological and semantic knowledge, improving model interpretability and trustworthiness. We suggest a generic approach that allows to derive an additional loss term starting from any kind of semantic information about the classification label. First, we show how to apply our approach to ontologies and word embeddings, and discuss how the resulting information can drive a supervised learning process. Second, we use our semantically enriched loss to train image classifiers, and analyse the trade-offs between accuracy, mistake severity, and learned internal representations. Finally, we discuss how this approach can be further exploited in terms of explainability and adversarial robustness. Code repository: https://github.com/S1M0N38/semantic-encodings
Streamlining models with explanations in the learning loop
Feb 15, 2023Several explainable AI methods allow a Machine Learning user to get insights on the classification process of a black-box model in the form of local linear explanations. With such information, the user can judge which features are locally relevant for the classification outcome, and get an understanding of how the model reasons. Standard supervised learning processes are purely driven by the original features and target labels, without any feedback loop informed by the local relevance of the features identified by the post-hoc explanations. In this paper, we exploit this newly obtained information to design a feature engineering phase, where we combine explanations with feature values. To do so, we develop two different strategies, named Iterative Dataset Weighting and Targeted Replacement Values, which generate streamlined models that better mimic the explanation process presented to the user. We show how these streamlined models compare to the original black-box classifiers, in terms of accuracy and compactness of the newly produced explanations.
* 16 pages, 10 figures, available repository
GRAPHSHAP: Motif-based Explanations for Black-box Graph Classifiers
Feb 17, 2022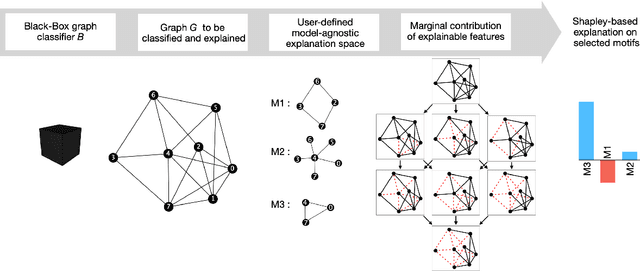
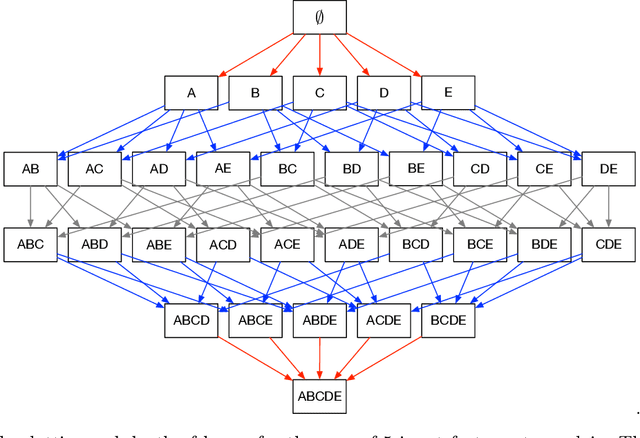
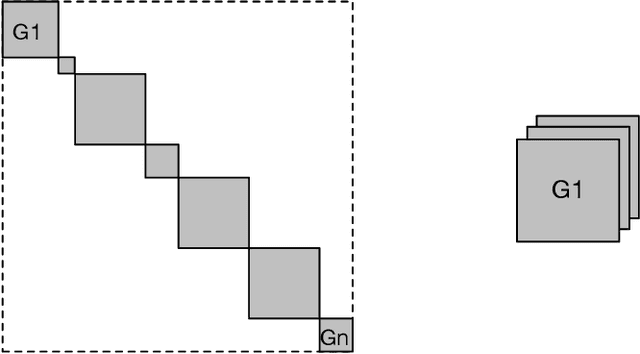
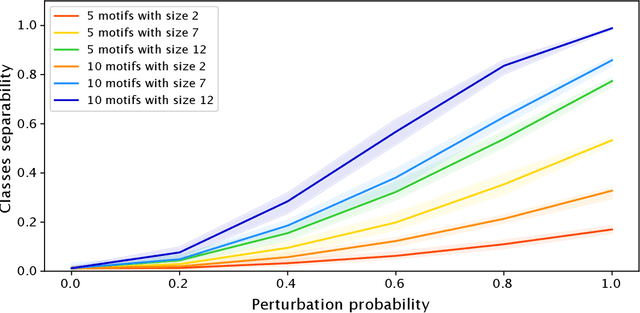
Most methods for explaining black-box classifiers (e.g., on tabular data, images, or time series) rely on measuring the impact that the removal/perturbation of features has on the model output. This forces the explanation language to match the classifier features space. However, when dealing with graph data, in which the basic features correspond essentially to the adjacency information describing the graph structure (i.e., the edges), this matching between features space and explanation language might not be appropriate. In this regard, we argue that (i) a good explanation method for graph classification should be fully agnostic with respect to the internal representation used by the black-box; and (ii) a good explanation language for graph classification tasks should be represented by higher-order structures, such as motifs. The need to decouple the feature space (edges) from the explanation space (motifs) is thus a major challenge towards developing actionable explanations for graph classification tasks. In this paper we introduce GRAPHSHAP, a Shapley-based approach able to provide motif-based explanations for black-box graph classifiers, assuming no knowledge whatsoever about the model or its training data: the only requirement is that the black-box can be queried at will. Furthermore, we introduce additional auxiliary components such as a synthetic graph dataset generator, algorithms for subgraph mining and ranking, a custom graph convolutional layer, and a kernel to approximate the explanation scores while maintaining linear time complexity. Finally, we test GRAPHSHAP on a real-world brain-network dataset consisting of patients affected by Autism Spectrum Disorder and a control group. Our experiments highlight how the classification provided by a black-box model can be effectively explained by few connectomics patterns.
To trust or not to trust an explanation: using LEAF to evaluate local linear XAI methods
Jun 01, 2021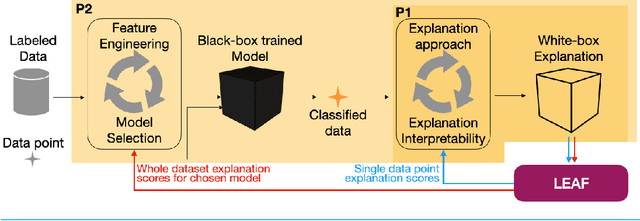
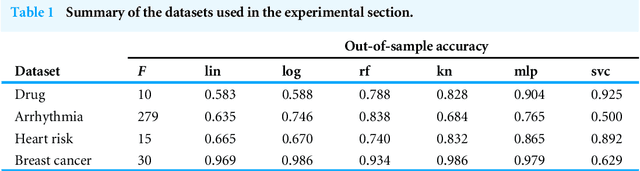


The main objective of eXplainable Artificial Intelligence (XAI) is to provide effective explanations for black-box classifiers. The existing literature lists many desirable properties for explanations to be useful, but there is no consensus on how to quantitatively evaluate explanations in practice. Moreover, explanations are typically used only to inspect black-box models, and the proactive use of explanations as a decision support is generally overlooked. Among the many approaches to XAI, a widely adopted paradigm is Local Linear Explanations - with LIME and SHAP emerging as state-of-the-art methods. We show that these methods are plagued by many defects including unstable explanations, divergence of actual implementations from the promised theoretical properties, and explanations for the wrong label. This highlights the need to have standard and unbiased evaluation procedures for Local Linear Explanations in the XAI field. In this paper we address the problem of identifying a clear and unambiguous set of metrics for the evaluation of Local Linear Explanations. This set includes both existing and novel metrics defined specifically for this class of explanations. All metrics have been included in an open Python framework, named LEAF. The purpose of LEAF is to provide a reference for end users to evaluate explanations in a standardised and unbiased way, and to guide researchers towards developing improved explainable techniques.
* 16 pages, 8 figures