 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFor a semiotic AI: Bridging computer vision and visual semiotics for computational observation of large scale facial image archives
Jul 03, 2024Social networks are creating a digital world in which the cognitive, emotional, and pragmatic value of the imagery of human faces and bodies is arguably changing. However, researchers in the digital humanities are often ill-equipped to study these phenomena at scale. This work presents FRESCO (Face Representation in E-Societies through Computational Observation), a framework designed to explore the socio-cultural implications of images on social media platforms at scale. FRESCO deconstructs images into numerical and categorical variables using state-of-the-art computer vision techniques, aligning with the principles of visual semiotics. The framework analyzes images across three levels: the plastic level, encompassing fundamental visual features like lines and colors; the figurative level, representing specific entities or concepts; and the enunciation level, which focuses particularly on constructing the point of view of the spectator and observer. These levels are analyzed to discern deeper narrative layers within the imagery. Experimental validation confirms the reliability and utility of FRESCO, and we assess its consistency and precision across two public datasets. Subsequently, we introduce the FRESCO score, a metric derived from the framework's output that serves as a reliable measure of similarity in image content.
Toward a Realistic Benchmark for Out-of-Distribution Detection
Apr 16, 2024Deep neural networks are increasingly used in a wide range of technologies and services, but remain highly susceptible to out-of-distribution (OOD) samples, that is, drawn from a different distribution than the original training set. A common approach to address this issue is to endow deep neural networks with the ability to detect OOD samples. Several benchmarks have been proposed to design and validate OOD detection techniques. However, many of them are based on far-OOD samples drawn from very different distributions, and thus lack the complexity needed to capture the nuances of real-world scenarios. In this work, we introduce a comprehensive benchmark for OOD detection, based on ImageNet and Places365, that assigns individual classes as in-distribution or out-of-distribution depending on the semantic similarity with the training set. Several techniques can be used to determine which classes should be considered in-distribution, yielding benchmarks with varying properties. Experimental results on different OOD detection techniques show how their measured efficacy depends on the selected benchmark and how confidence-based techniques may outperform classifier-based ones on near-OOD samples.
HOLMES: HOLonym-MEronym based Semantic inspection for Convolutional Image Classifiers
Mar 13, 2024Convolutional Neural Networks (CNNs) are nowadays the model of choice in Computer Vision, thanks to their ability to automatize the feature extraction process in visual tasks. However, the knowledge acquired during training is fully subsymbolic, and hence difficult to understand and explain to end users. In this paper, we propose a new technique called HOLMES (HOLonym-MEronym based Semantic inspection) that decomposes a label into a set of related concepts, and provides component-level explanations for an image classification model. Specifically, HOLMES leverages ontologies, web scraping and transfer learning to automatically construct meronym (parts)-based detectors for a given holonym (class). Then, it produces heatmaps at the meronym level and finally, by probing the holonym CNN with occluded images, it highlights the importance of each part on the classification output. Compared to state-of-the-art saliency methods, HOLMES takes a step further and provides information about both where and what the holonym CNN is looking at, without relying on densely annotated datasets and without forcing concepts to be associated to single computational units. Extensive experimental evaluation on different categories of objects (animals, tools and vehicles) shows the feasibility of our approach. On average, HOLMES explanations include at least two meronyms, and the ablation of a single meronym roughly halves the holonym model confidence. The resulting heatmaps were quantitatively evaluated using the deletion/insertion/preservation curves. All metrics were comparable to those achieved by GradCAM, while offering the advantage of further decomposing the heatmap in human-understandable concepts, thus highlighting both the relevance of meronyms to object classification, as well as HOLMES ability to capture it. The code is available at https://github.com/FrancesC0de/HOLMES.
* This work has been accepted to be presented to The 1st World Conference on eXplainable Artificial Intelligence (xAI 2023), July 26-28, 2023 - Lisboa, Portugal
Object Tracking through Residual and Dense LSTMs
Jun 22, 2020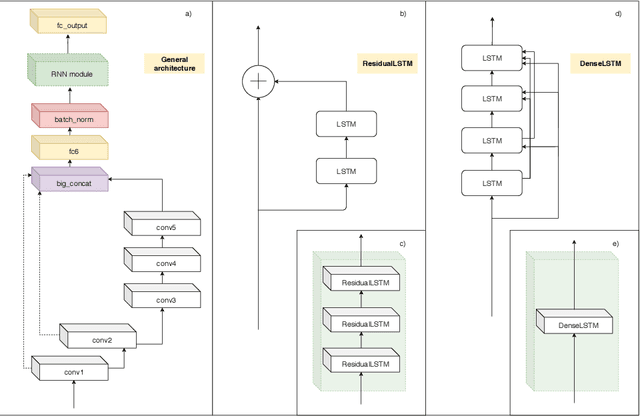

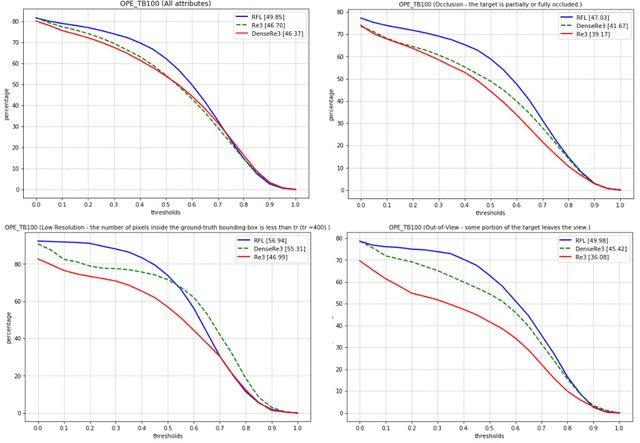
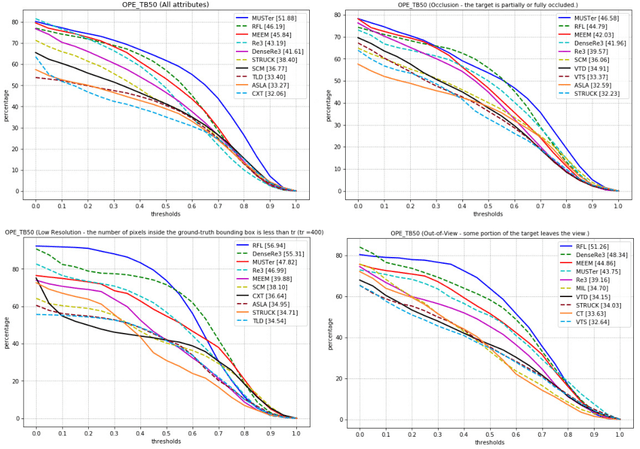
Visual object tracking task is constantly gaining importance in several fields of application as traffic monitoring, robotics, and surveillance, to name a few. Dealing with changes in the appearance of the tracked object is paramount to achieve high tracking accuracy, and is usually achieved by continually learning features. Recently, deep learning-based trackers based on LSTMs (Long Short-Term Memory) recurrent neural networks have emerged as a powerful alternative, bypassing the need to retrain the feature extraction in an online fashion. Inspired by the success of residual and dense networks in image recognition, we propose here to enhance the capabilities of hybrid trackers using residual and/or dense LSTMs. By introducing skip connections, it is possible to increase the depth of the architecture while ensuring a fast convergence. Experimental results on the Re3 tracker show that DenseLSTMs outperform Residual and regular LSTM, and offer a higher resilience to nuisances such as occlusions and out-of-view objects. Our case study supports the adoption of residual-based RNNs for enhancing the robustness of other trackers.