 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFor a semiotic AI: Bridging computer vision and visual semiotics for computational observation of large scale facial image archives
Jul 03, 2024Social networks are creating a digital world in which the cognitive, emotional, and pragmatic value of the imagery of human faces and bodies is arguably changing. However, researchers in the digital humanities are often ill-equipped to study these phenomena at scale. This work presents FRESCO (Face Representation in E-Societies through Computational Observation), a framework designed to explore the socio-cultural implications of images on social media platforms at scale. FRESCO deconstructs images into numerical and categorical variables using state-of-the-art computer vision techniques, aligning with the principles of visual semiotics. The framework analyzes images across three levels: the plastic level, encompassing fundamental visual features like lines and colors; the figurative level, representing specific entities or concepts; and the enunciation level, which focuses particularly on constructing the point of view of the spectator and observer. These levels are analyzed to discern deeper narrative layers within the imagery. Experimental validation confirms the reliability and utility of FRESCO, and we assess its consistency and precision across two public datasets. Subsequently, we introduce the FRESCO score, a metric derived from the framework's output that serves as a reliable measure of similarity in image content.
Toward a Realistic Benchmark for Out-of-Distribution Detection
Apr 16, 2024Deep neural networks are increasingly used in a wide range of technologies and services, but remain highly susceptible to out-of-distribution (OOD) samples, that is, drawn from a different distribution than the original training set. A common approach to address this issue is to endow deep neural networks with the ability to detect OOD samples. Several benchmarks have been proposed to design and validate OOD detection techniques. However, many of them are based on far-OOD samples drawn from very different distributions, and thus lack the complexity needed to capture the nuances of real-world scenarios. In this work, we introduce a comprehensive benchmark for OOD detection, based on ImageNet and Places365, that assigns individual classes as in-distribution or out-of-distribution depending on the semantic similarity with the training set. Several techniques can be used to determine which classes should be considered in-distribution, yielding benchmarks with varying properties. Experimental results on different OOD detection techniques show how their measured efficacy depends on the selected benchmark and how confidence-based techniques may outperform classifier-based ones on near-OOD samples.
Latent Diffusion Models for Attribute-Preserving Image Anonymization
Mar 21, 2024Generative techniques for image anonymization have great potential to generate datasets that protect the privacy of those depicted in the images, while achieving high data fidelity and utility. Existing methods have focused extensively on preserving facial attributes, but failed to embrace a more comprehensive perspective that considers the scene and background into the anonymization process. This paper presents, to the best of our knowledge, the first approach to image anonymization based on Latent Diffusion Models (LDMs). Every element of a scene is maintained to convey the same meaning, yet manipulated in a way that makes re-identification difficult. We propose two LDMs for this purpose: CAMOUFLaGE-Base exploits a combination of pre-trained ControlNets, and a new controlling mechanism designed to increase the distance between the real and anonymized images. CAMOFULaGE-Light is based on the Adapter technique, coupled with an encoding designed to efficiently represent the attributes of different persons in a scene. The former solution achieves superior performance on most metrics and benchmarks, while the latter cuts the inference time in half at the cost of fine-tuning a lightweight module. We show through extensive experimental comparison that the proposed method is competitive with the state-of-the-art concerning identity obfuscation whilst better preserving the original content of the image and tackling unresolved challenges that current solutions fail to address.
Bent & Broken Bicycles: Leveraging synthetic data for damaged object re-identification
Apr 16, 2023Instance-level object re-identification is a fundamental computer vision task, with applications from image retrieval to intelligent monitoring and fraud detection. In this work, we propose the novel task of damaged object re-identification, which aims at distinguishing changes in visual appearance due to deformations or missing parts from subtle intra-class variations. To explore this task, we leverage the power of computer-generated imagery to create, in a semi-automatic fashion, high-quality synthetic images of the same bike before and after a damage occurs. The resulting dataset, Bent & Broken Bicycles (BBBicycles), contains 39,200 images and 2,800 unique bike instances spanning 20 different bike models. As a baseline for this task, we propose TransReI3D, a multi-task, transformer-based deep network unifying damage detection (framed as a multi-label classification task) with object re-identification. The BBBicycles dataset is available at https://huggingface.co/datasets/GrainsPolito/BBBicycles
Bridging the gap between Natural and Medical Images through Deep Colorization
May 21, 2020


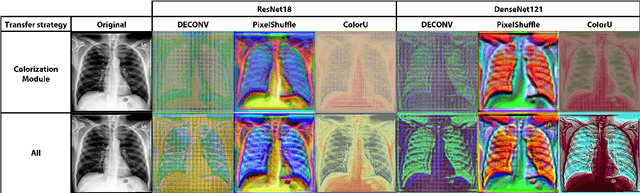
Deep learning has thrived by training on large-scale datasets. However, in many applications, as for medical image diagnosis, getting massive amount of data is still prohibitive due to privacy, lack of acquisition homogeneity and annotation cost. In this scenario, transfer learning from natural image collections is a standard practice that attempts to tackle shape, texture and color discrepancies all at once through pretrained model fine-tuning. In this work, we propose to disentangle those challenges and design a dedicated network module that focuses on color adaptation. We combine learning from scratch of the color module with transfer learning of different classification backbones, obtaining an end-to-end, easy-to-train architecture for diagnostic image recognition on X-ray images. Extensive experiments showed how our approach is particularly efficient in case of data scarcity and provides a new path for further transferring the learned color information across multiple medical datasets.