 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFor a semiotic AI: Bridging computer vision and visual semiotics for computational observation of large scale facial image archives
Jul 03, 2024Social networks are creating a digital world in which the cognitive, emotional, and pragmatic value of the imagery of human faces and bodies is arguably changing. However, researchers in the digital humanities are often ill-equipped to study these phenomena at scale. This work presents FRESCO (Face Representation in E-Societies through Computational Observation), a framework designed to explore the socio-cultural implications of images on social media platforms at scale. FRESCO deconstructs images into numerical and categorical variables using state-of-the-art computer vision techniques, aligning with the principles of visual semiotics. The framework analyzes images across three levels: the plastic level, encompassing fundamental visual features like lines and colors; the figurative level, representing specific entities or concepts; and the enunciation level, which focuses particularly on constructing the point of view of the spectator and observer. These levels are analyzed to discern deeper narrative layers within the imagery. Experimental validation confirms the reliability and utility of FRESCO, and we assess its consistency and precision across two public datasets. Subsequently, we introduce the FRESCO score, a metric derived from the framework's output that serves as a reliable measure of similarity in image content.
Toward a Realistic Benchmark for Out-of-Distribution Detection
Apr 16, 2024Deep neural networks are increasingly used in a wide range of technologies and services, but remain highly susceptible to out-of-distribution (OOD) samples, that is, drawn from a different distribution than the original training set. A common approach to address this issue is to endow deep neural networks with the ability to detect OOD samples. Several benchmarks have been proposed to design and validate OOD detection techniques. However, many of them are based on far-OOD samples drawn from very different distributions, and thus lack the complexity needed to capture the nuances of real-world scenarios. In this work, we introduce a comprehensive benchmark for OOD detection, based on ImageNet and Places365, that assigns individual classes as in-distribution or out-of-distribution depending on the semantic similarity with the training set. Several techniques can be used to determine which classes should be considered in-distribution, yielding benchmarks with varying properties. Experimental results on different OOD detection techniques show how their measured efficacy depends on the selected benchmark and how confidence-based techniques may outperform classifier-based ones on near-OOD samples.
Latent Diffusion Models for Attribute-Preserving Image Anonymization
Mar 21, 2024Generative techniques for image anonymization have great potential to generate datasets that protect the privacy of those depicted in the images, while achieving high data fidelity and utility. Existing methods have focused extensively on preserving facial attributes, but failed to embrace a more comprehensive perspective that considers the scene and background into the anonymization process. This paper presents, to the best of our knowledge, the first approach to image anonymization based on Latent Diffusion Models (LDMs). Every element of a scene is maintained to convey the same meaning, yet manipulated in a way that makes re-identification difficult. We propose two LDMs for this purpose: CAMOUFLaGE-Base exploits a combination of pre-trained ControlNets, and a new controlling mechanism designed to increase the distance between the real and anonymized images. CAMOFULaGE-Light is based on the Adapter technique, coupled with an encoding designed to efficiently represent the attributes of different persons in a scene. The former solution achieves superior performance on most metrics and benchmarks, while the latter cuts the inference time in half at the cost of fine-tuning a lightweight module. We show through extensive experimental comparison that the proposed method is competitive with the state-of-the-art concerning identity obfuscation whilst better preserving the original content of the image and tackling unresolved challenges that current solutions fail to address.
Fuzzy Logic Visual Network : A neuro-symbolic approach for visual features matching
Jul 29, 2023Neuro-symbolic integration aims at harnessing the power of symbolic knowledge representation combined with the learning capabilities of deep neural networks. In particular, Logic Tensor Networks (LTNs) allow to incorporate background knowledge in the form of logical axioms by grounding a first order logic language as differentiable operations between real tensors. Yet, few studies have investigated the potential benefits of this approach to improve zero-shot learning (ZSL) classification. In this study, we present the Fuzzy Logic Visual Network (FLVN) that formulates the task of learning a visual-semantic embedding space within a neuro-symbolic LTN framework. FLVN incorporates prior knowledge in the form of class hierarchies (classes and macro-classes) along with robust high-level inductive biases. The latter allow, for instance, to handle exceptions in class-level attributes, and to enforce similarity between images of the same class, preventing premature overfitting to seen classes and improving overall performance. FLVN reaches state of the art performance on the Generalized ZSL (GZSL) benchmarks AWA2 and CUB, improving by 1.3% and 3%, respectively. Overall, it achieves competitive performance to recent ZSL methods with less computational overhead. FLVN is available at https://gitlab.com/grains2/flvn.
Bent & Broken Bicycles: Leveraging synthetic data for damaged object re-identification
Apr 16, 2023Instance-level object re-identification is a fundamental computer vision task, with applications from image retrieval to intelligent monitoring and fraud detection. In this work, we propose the novel task of damaged object re-identification, which aims at distinguishing changes in visual appearance due to deformations or missing parts from subtle intra-class variations. To explore this task, we leverage the power of computer-generated imagery to create, in a semi-automatic fashion, high-quality synthetic images of the same bike before and after a damage occurs. The resulting dataset, Bent & Broken Bicycles (BBBicycles), contains 39,200 images and 2,800 unique bike instances spanning 20 different bike models. As a baseline for this task, we propose TransReI3D, a multi-task, transformer-based deep network unifying damage detection (framed as a multi-label classification task) with object re-identification. The BBBicycles dataset is available at https://huggingface.co/datasets/GrainsPolito/BBBicycles
Faster-LTN: a neuro-symbolic, end-to-end object detection architecture
Jul 05, 2021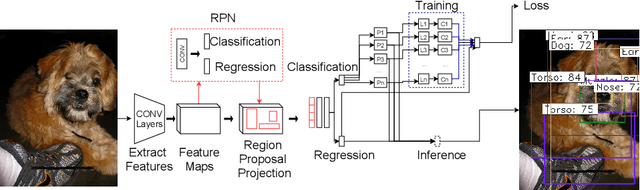
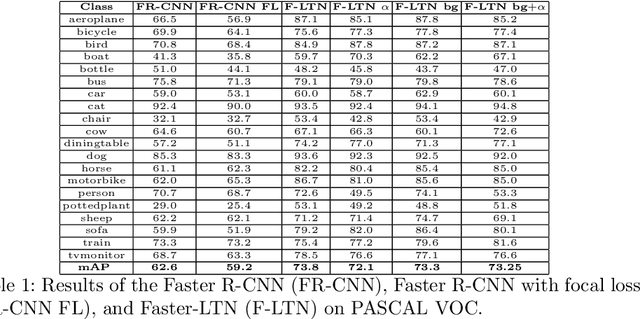
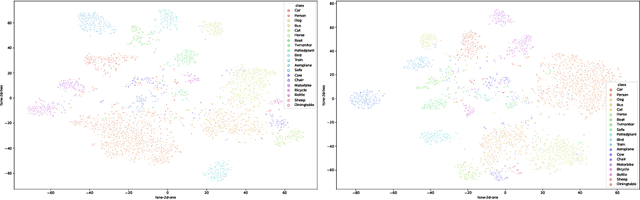
The detection of semantic relationships between objects represented in an image is one of the fundamental challenges in image interpretation. Neural-Symbolic techniques, such as Logic Tensor Networks (LTNs), allow the combination of semantic knowledge representation and reasoning with the ability to efficiently learn from examples typical of neural networks. We here propose Faster-LTN, an object detector composed of a convolutional backbone and an LTN. To the best of our knowledge, this is the first attempt to combine both frameworks in an end-to-end training setting. This architecture is trained by optimizing a grounded theory which combines labelled examples with prior knowledge, in the form of logical axioms. Experimental comparisons show competitive performance with respect to the traditional Faster R-CNN architecture.
Breast Mass Detection with Faster R-CNN: On the Feasibility of Learning from Noisy Annotations
Apr 25, 2021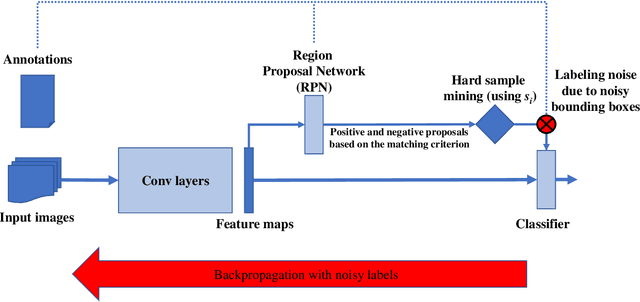

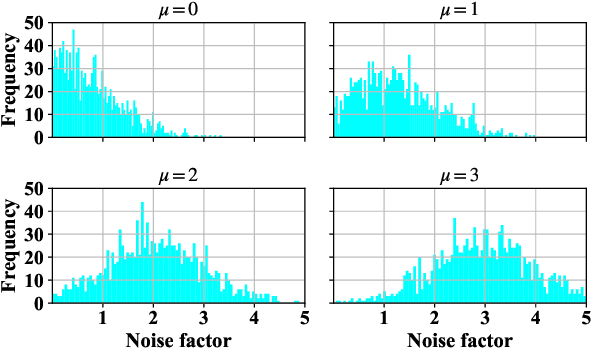
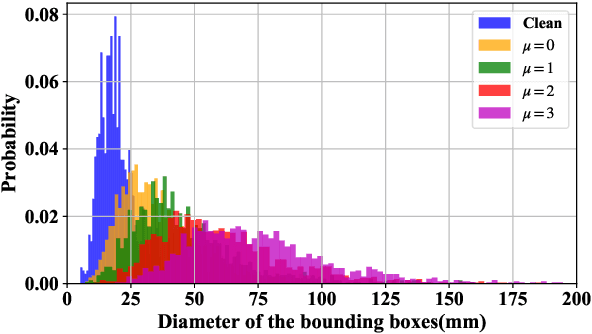
In this work we study the impact of noise on the training of object detection networks for the medical domain, and how it can be mitigated by improving the training procedure. Annotating large medical datasets for training data-hungry deep learning models is expensive and time consuming. Leveraging information that is already collected in clinical practice, in the form of text reports, bookmarks or lesion measurements would substantially reduce this cost. Obtaining precise lesion bounding boxes through automatic mining procedures, however, is difficult. We provide here a quantitative evaluation of the effect of bounding box coordinate noise on the performance of Faster R-CNN object detection networks for breast mass detection. Varying degrees of noise are simulated by randomly modifying the bounding boxes: in our experiments, bounding boxes could be enlarged up to six times the original size. The noise is injected in the CBIS-DDSM collection, a well curated public mammography dataset for which accurate lesion location is available. We show how, due to an imperfect matching between the ground truth and the network bounding box proposals, the noise is propagated during training and reduces the ability of the network to correctly classify lesions from background. When using the standard Intersection over Union criterion, the area under the FROC curve decreases by up to 9%. A novel matching criterion is proposed to improve tolerance to noise.
Comparing State-of-the-Art and Emerging Augmented Reality Interfaces for Autonomous Vehicle-to-Pedestrian Communication
Feb 04, 2021
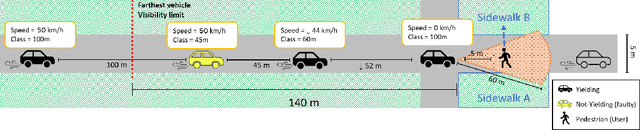
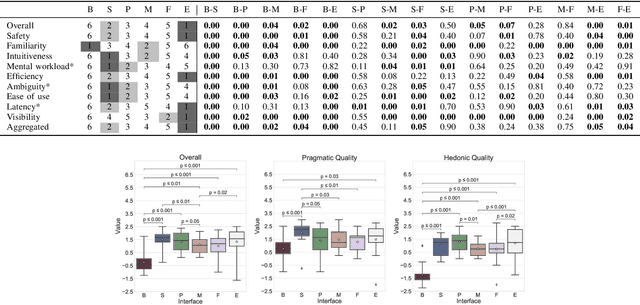
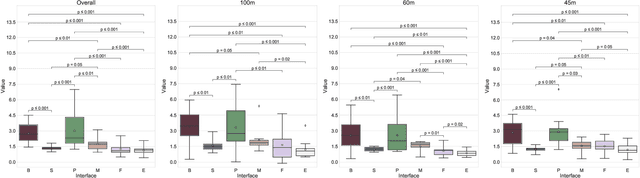
Providing pedestrians and other vulnerable road users with a clear indication about a fully autonomous vehicle status and intentions is crucial to make them coexist. In the last few years, a variety of external interfaces have been proposed, leveraging different paradigms and technologies including vehicle-mounted devices (like LED panels), short-range on-road projections, and road infrastructure interfaces (e.g., special asphalts with embedded displays). These designs were experimented in different settings, using mockups, specially prepared vehicles, or virtual environments, with heterogeneous evaluation metrics. Promising interfaces based on Augmented Reality (AR) have been proposed too, but their usability and effectiveness have not been tested yet. This paper aims to complement such body of literature by presenting a comparison of state-of-the-art interfaces and new designs under common conditions. To this aim, an immersive Virtual Reality-based simulation was developed, recreating a well-known scenario represented by pedestrians crossing in urban environments under non-regulated conditions. A user study was then performed to investigate the various dimensions of vehicle-to-pedestrian interaction leveraging objective and subjective metrics. Even though no interface clearly stood out over all the considered dimensions, one of the AR designs achieved state-of-the-art results in terms of safety and trust, at the cost of higher cognitive effort and lower intuitiveness compared to LED panels showing anthropomorphic features. Together with rankings on the various dimensions, indications about advantages and drawbacks of the various alternatives that emerged from this study could provide important information for next developments in the field.
Mixed-Reality Robotic Games: Design Guidelines for Effective Entertainment with Consumer Robots
Jul 30, 2020



In recent years, there has been an increasing interest in the use of robotic technology at home. A number of service robots appeared on the market, supporting customers in the execution of everyday tasks. Roughly at the same time, consumer level robots started to be used also as toys or gaming companions. However, gaming possibilities provided by current off-the-shelf robotic products are generally quite limited, and this fact makes them quickly loose their attractiveness. A way that has been proven capable to boost robotic gaming and related devices consists in creating playful experiences in which physical and digital elements are combined together using Mixed Reality technologies. However, these games differ significantly from digital- or physical only experiences, and new design principles are required to support developers in their creative work. This papers addresses such need, by drafting a set of guidelines which summarize developments carried out by the research community and their findings.
Building Trust in Autonomous Vehicles: Role of Virtual Reality Driving Simulators in HMI Design
Jul 27, 2020

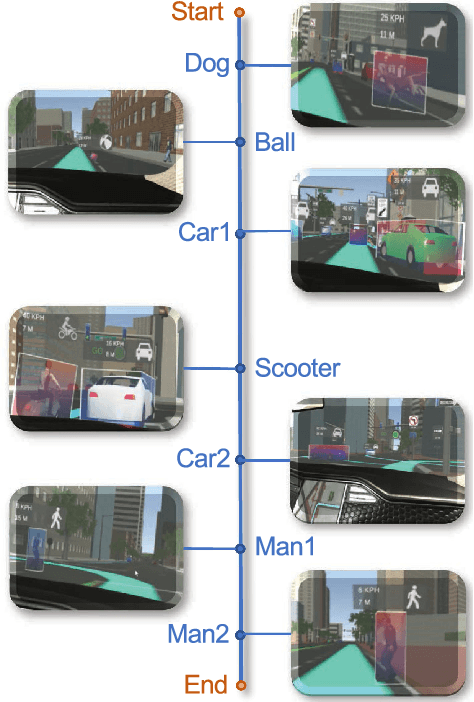
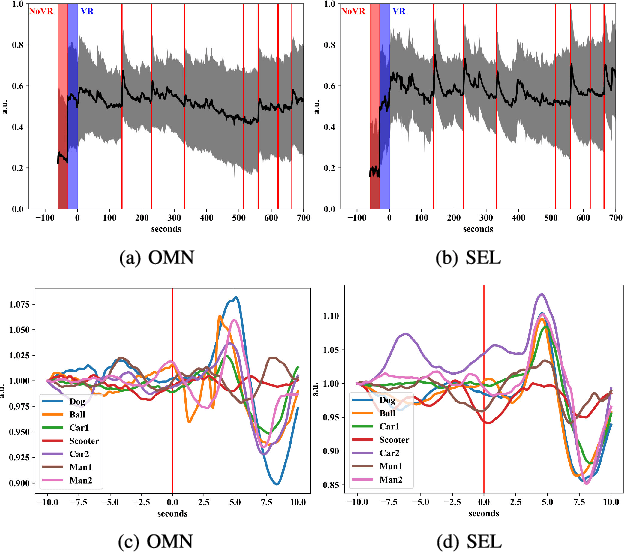
The investigation of factors contributing at making humans trust Autonomous Vehicles (AVs) will play a fundamental role in the adoption of such technology. The user's ability to form a mental model of the AV, which is crucial to establish trust, depends on effective user-vehicle communication; thus, the importance of Human-Machine Interaction (HMI) is poised to increase. In this work, we propose a methodology to validate the user experience in AVs based on continuous, objective information gathered from physiological signals, while the user is immersed in a Virtual Reality-based driving simulation. We applied this methodology to the design of a head-up display interface delivering visual cues about the vehicle' sensory and planning systems. Through this approach, we obtained qualitative and quantitative evidence that a complete picture of the vehicle's surrounding, despite the higher cognitive load, is conducive to a less stressful experience. Moreover, after having been exposed to a more informative interface, users involved in the study were also more willing to test a real AV. The proposed methodology could be extended by adjusting the simulation environment, the HMI and/or the vehicle's Artificial Intelligence modules to dig into other aspects of the user experience.