 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFuzzy Logic Visual Network : A neuro-symbolic approach for visual features matching
Jul 29, 2023Neuro-symbolic integration aims at harnessing the power of symbolic knowledge representation combined with the learning capabilities of deep neural networks. In particular, Logic Tensor Networks (LTNs) allow to incorporate background knowledge in the form of logical axioms by grounding a first order logic language as differentiable operations between real tensors. Yet, few studies have investigated the potential benefits of this approach to improve zero-shot learning (ZSL) classification. In this study, we present the Fuzzy Logic Visual Network (FLVN) that formulates the task of learning a visual-semantic embedding space within a neuro-symbolic LTN framework. FLVN incorporates prior knowledge in the form of class hierarchies (classes and macro-classes) along with robust high-level inductive biases. The latter allow, for instance, to handle exceptions in class-level attributes, and to enforce similarity between images of the same class, preventing premature overfitting to seen classes and improving overall performance. FLVN reaches state of the art performance on the Generalized ZSL (GZSL) benchmarks AWA2 and CUB, improving by 1.3% and 3%, respectively. Overall, it achieves competitive performance to recent ZSL methods with less computational overhead. FLVN is available at https://gitlab.com/grains2/flvn.
PROTOtypical Logic Tensor Networks (PROTO-LTN) for Zero Shot Learning
Jun 26, 2022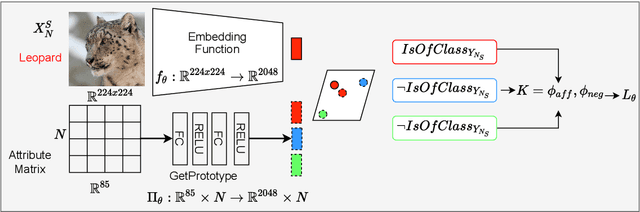


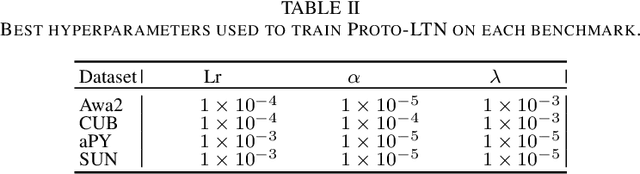
Semantic image interpretation can vastly benefit from approaches that combine sub-symbolic distributed representation learning with the capability to reason at a higher level of abstraction. Logic Tensor Networks (LTNs) are a class of neuro-symbolic systems based on a differentiable, first-order logic grounded into a deep neural network. LTNs replace the classical concept of training set with a knowledge base of fuzzy logical axioms. By defining a set of differentiable operators to approximate the role of connectives, predicates, functions and quantifiers, a loss function is automatically specified so that LTNs can learn to satisfy the knowledge base. We focus here on the subsumption or \texttt{isOfClass} predicate, which is fundamental to encode most semantic image interpretation tasks. Unlike conventional LTNs, which rely on a separate predicate for each class (e.g., dog, cat), each with its own set of learnable weights, we propose a common \texttt{isOfClass} predicate, whose level of truth is a function of the distance between an object embedding and the corresponding class prototype. The PROTOtypical Logic Tensor Networks (PROTO-LTN) extend the current formulation by grounding abstract concepts as parametrized class prototypes in a high-dimensional embedding space, while reducing the number of parameters required to ground the knowledge base. We show how this architecture can be effectively trained in the few and zero-shot learning scenarios. Experiments on Generalized Zero Shot Learning benchmarks validate the proposed implementation as a competitive alternative to traditional embedding-based approaches. The proposed formulation opens up new opportunities in zero shot learning settings, as the LTN formalism allows to integrate background knowledge in the form of logical axioms to compensate for the lack of labelled examples.
Faster-LTN: a neuro-symbolic, end-to-end object detection architecture
Jul 05, 2021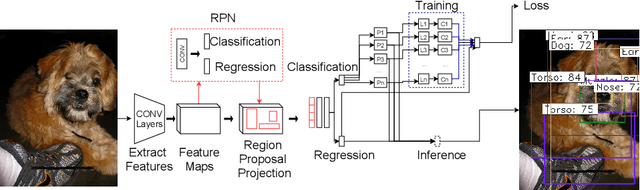
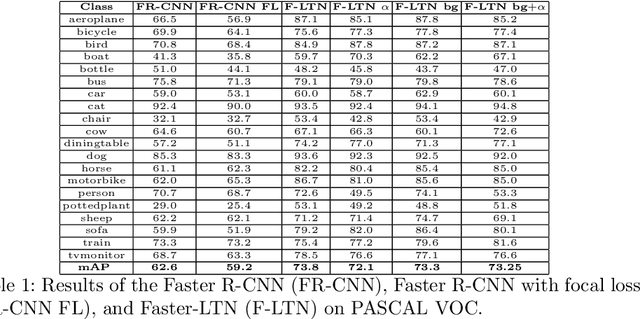
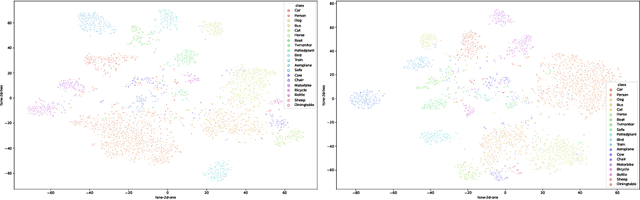
The detection of semantic relationships between objects represented in an image is one of the fundamental challenges in image interpretation. Neural-Symbolic techniques, such as Logic Tensor Networks (LTNs), allow the combination of semantic knowledge representation and reasoning with the ability to efficiently learn from examples typical of neural networks. We here propose Faster-LTN, an object detector composed of a convolutional backbone and an LTN. To the best of our knowledge, this is the first attempt to combine both frameworks in an end-to-end training setting. This architecture is trained by optimizing a grounded theory which combines labelled examples with prior knowledge, in the form of logical axioms. Experimental comparisons show competitive performance with respect to the traditional Faster R-CNN architecture.
Slicing and dicing soccer: automatic detection of complex events from spatio-temporal data
Apr 10, 2020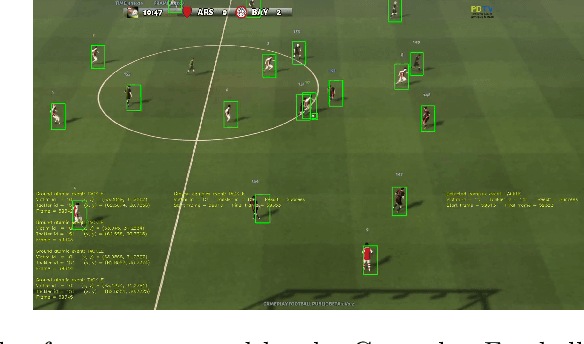
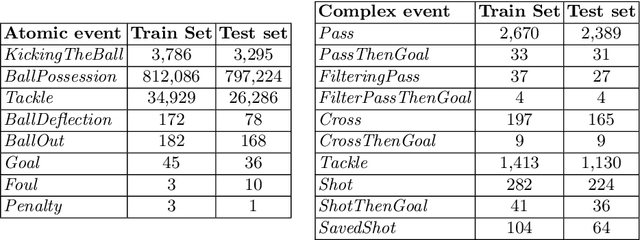
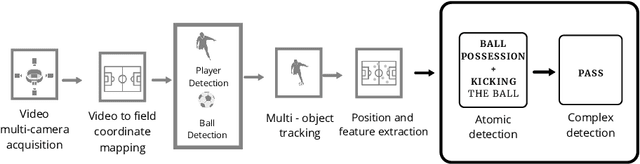
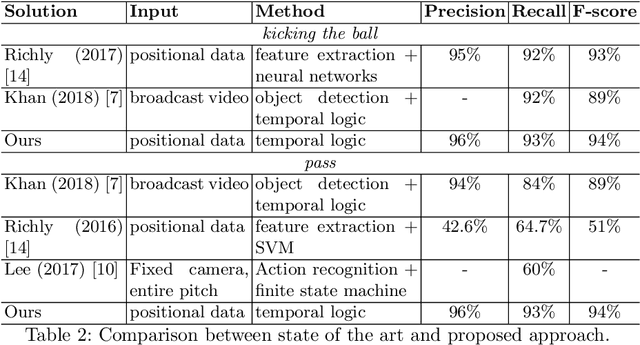
The automatic detection of events in sport videos has im-portant applications for data analytics, as well as for broadcasting andmedia companies. This paper presents a comprehensive approach for de-tecting a wide range of complex events in soccer videos starting frompositional data. The event detector is designed as a two-tier system thatdetectsatomicandcomplex events. Atomic events are detected basedon temporal and logical combinations of the detected objects, their rel-ative distances, as well as spatio-temporal features such as velocity andacceleration. Complex events are defined as temporal and logical com-binations of atomic and complex events, and are expressed by meansof a declarative Interval Temporal Logic (ITL). The effectiveness of theproposed approach is demonstrated over 16 different events, includingcomplex situations such as tackles and filtering passes. By formalizingevents based on principled ITL, it is possible to easily perform reason-ing tasks, such as understanding which passes or crosses result in a goalbeing scored. To counterbalance the lack of suitable, annotated publicdatasets, we built on an open source soccer simulation engine to re-lease the synthetic SoccER (Soccer Event Recognition) dataset, whichincludes complete positional data and annotations for more than 1.6 mil-lion atomic events and 9,000 complex events. The dataset and code areavailable at https://gitlab.com/grains2/slicing-and-dicing-soccer