 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBias and Identifiability in the Bounded Confidence Model
Jun 13, 2025



Opinion dynamics models such as the bounded confidence models (BCMs) describe how a population can reach consensus, fragmentation, or polarization, depending on a few parameters. Connecting such models to real-world data could help understanding such phenomena, testing model assumptions. To this end, estimation of model parameters is a key aspect, and maximum likelihood estimation provides a principled way to tackle it. Here, our goal is to outline the properties of statistical estimators of the two key BCM parameters: the confidence bound and the convergence rate. We find that their maximum likelihood estimators present different characteristics: the one for the confidence bound presents a small-sample bias but is consistent, while the estimator of the convergence rate shows a persistent bias. Moreover, the joint parameter estimation is affected by identifiability issues for specific regions of the parameter space, as several local maxima are present in the likelihood function. Our results show how the analysis of the likelihood function is a fruitful approach for better understanding the pitfalls and possibilities of estimating the parameters of opinion dynamics models, and more in general, agent-based models, and for offering formal guarantees for their calibration.
Multi-Class and Multi-Task Strategies for Neural Directed Link Prediction
Dec 14, 2024Link Prediction is a foundational task in Graph Representation Learning, supporting applications like link recommendation, knowledge graph completion and graph generation. Graph Neural Networks have shown the most promising results in this domain and are currently the de facto standard approach to learning from graph data. However, a key distinction exists between Undirected and Directed Link Prediction: the former just predicts the existence of an edge, while the latter must also account for edge directionality and bidirectionality. This translates to Directed Link Prediction (DLP) having three sub-tasks, each defined by how training, validation and test sets are structured. Most research on DLP overlooks this trichotomy, focusing solely on the "existence" sub-task, where training and test sets are random, uncorrelated samples of positive and negative directed edges. Even in the works that recognize the aforementioned trichotomy, models fail to perform well across all three sub-tasks. In this study, we experimentally demonstrate that training Neural DLP (NDLP) models only on the existence sub-task, using methods adapted from Neural Undirected Link Prediction, results in parameter configurations that fail to capture directionality and bidirectionality, even after rebalancing edge classes. To address this, we propose three strategies that handle the three tasks simultaneously. Our first strategy, the Multi-Class Framework for Neural Directed Link Prediction (MC-NDLP) maps NDLP to a Multi-Class training objective. The second and third approaches adopt a Multi-Task perspective, either with a Multi-Objective (MO-DLP) or a Scalarized (S-DLP) strategy. Our results show that these methods outperform traditional approaches across multiple datasets and models, achieving equivalent or superior performance in addressing the three DLP sub-tasks.
Evaluating Link Prediction Explanations for Graph Neural Networks
Aug 03, 2023Graph Machine Learning (GML) has numerous applications, such as node/graph classification and link prediction, in real-world domains. Providing human-understandable explanations for GML models is a challenging yet fundamental task to foster their adoption, but validating explanations for link prediction models has received little attention. In this paper, we provide quantitative metrics to assess the quality of link prediction explanations, with or without ground-truth. State-of-the-art explainability methods for Graph Neural Networks are evaluated using these metrics. We discuss how underlying assumptions and technical details specific to the link prediction task, such as the choice of distance between node embeddings, can influence the quality of the explanations.
Towards an Automated Pipeline for Detecting and Classifying Malware through Machine Learning
Jun 10, 2021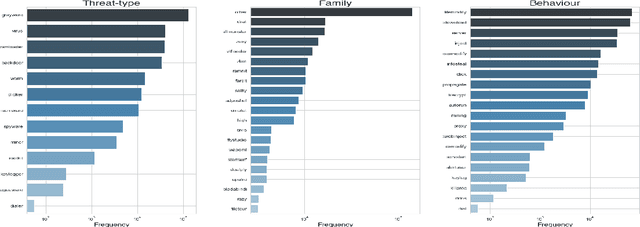

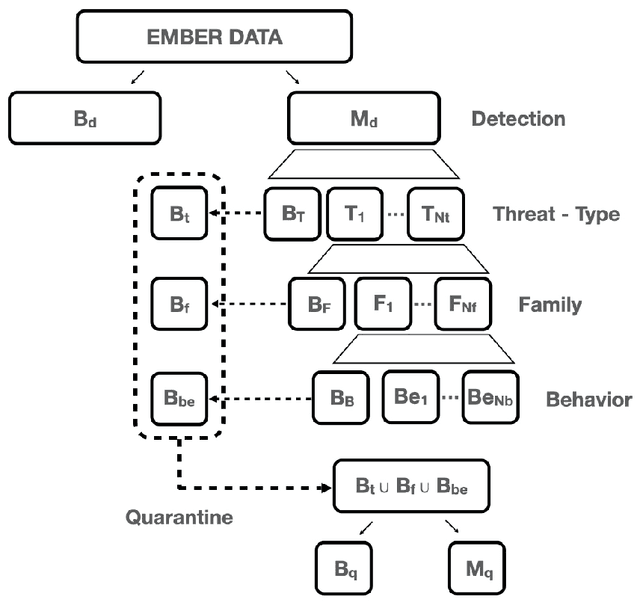
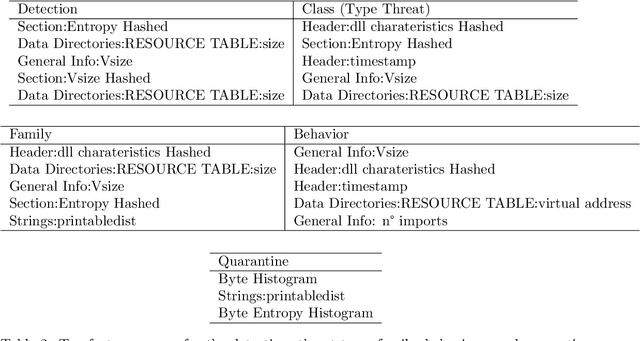
The constant growth in the number of malware - software or code fragment potentially harmful for computers and information networks - and the use of sophisticated evasion and obfuscation techniques have seriously hindered classic signature-based approaches. On the other hand, malware detection systems based on machine learning techniques started offering a promising alternative to standard approaches, drastically reducing analysis time and turning out to be more robust against evasion and obfuscation techniques. In this paper, we propose a malware taxonomic classification pipeline able to classify Windows Portable Executable files (PEs). Given an input PE sample, it is first classified as either malicious or benign. If malicious, the pipeline further analyzes it in order to establish its threat type, family, and behavior(s). We tested the proposed pipeline on the open source dataset EMBER, containing approximately 1 million PE samples, analyzed through static analysis. Obtained malware detection results are comparable to other academic works in the current state of art and, in addition, we provide an in-depth classification of malicious samples. Models used in the pipeline provides interpretable results which can help security analysts in better understanding decisions taken by the automated pipeline.