 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Class and Multi-Task Strategies for Neural Directed Link Prediction
Dec 14, 2024Link Prediction is a foundational task in Graph Representation Learning, supporting applications like link recommendation, knowledge graph completion and graph generation. Graph Neural Networks have shown the most promising results in this domain and are currently the de facto standard approach to learning from graph data. However, a key distinction exists between Undirected and Directed Link Prediction: the former just predicts the existence of an edge, while the latter must also account for edge directionality and bidirectionality. This translates to Directed Link Prediction (DLP) having three sub-tasks, each defined by how training, validation and test sets are structured. Most research on DLP overlooks this trichotomy, focusing solely on the "existence" sub-task, where training and test sets are random, uncorrelated samples of positive and negative directed edges. Even in the works that recognize the aforementioned trichotomy, models fail to perform well across all three sub-tasks. In this study, we experimentally demonstrate that training Neural DLP (NDLP) models only on the existence sub-task, using methods adapted from Neural Undirected Link Prediction, results in parameter configurations that fail to capture directionality and bidirectionality, even after rebalancing edge classes. To address this, we propose three strategies that handle the three tasks simultaneously. Our first strategy, the Multi-Class Framework for Neural Directed Link Prediction (MC-NDLP) maps NDLP to a Multi-Class training objective. The second and third approaches adopt a Multi-Task perspective, either with a Multi-Objective (MO-DLP) or a Scalarized (S-DLP) strategy. Our results show that these methods outperform traditional approaches across multiple datasets and models, achieving equivalent or superior performance in addressing the three DLP sub-tasks.
Link prediction in multiplex networks via triadic closure
Nov 16, 2020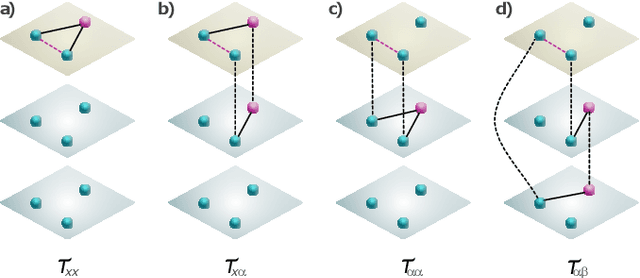
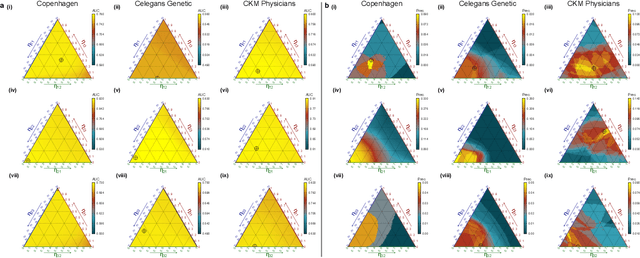
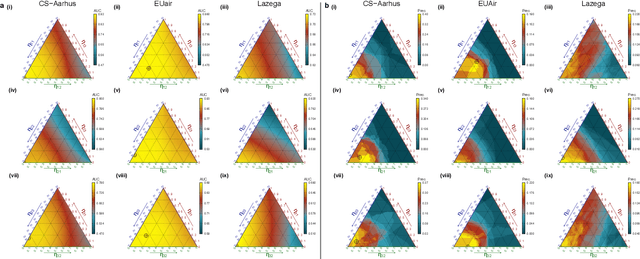
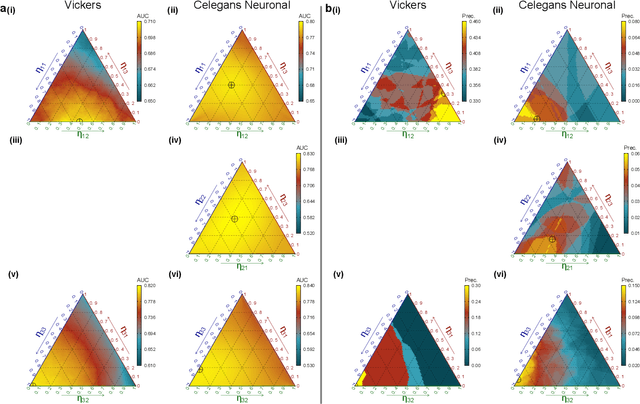
Link prediction algorithms can help to understand the structure and dynamics of complex systems, to reconstruct networks from incomplete data sets and to forecast future interactions in evolving networks. Available algorithms based on similarity between nodes are bounded by the limited amount of links present in these networks. In this work, we reduce this latter intrinsic limitation and show that different kind of relational data can be exploited to improve the prediction of new links. To this aim, we propose a novel link prediction algorithm by generalizing the Adamic-Adar method to multiplex networks composed by an arbitrary number of layers, that encode diverse forms of interactions. We show that the new metric outperforms the classical single-layered Adamic-Adar score and other state-of-the-art methods, across several social, biological and technological systems. As a byproduct, the coefficients that maximize the Multiplex Adamic-Adar metric indicate how the information structured in a multiplex network can be optimized for the link prediction task, revealing which layers are redundant. Interestingly, this effect can be asymmetric with respect to predictions in different layers. Our work paves the way for a deeper understanding of the role of different relational data in predicting new interactions and provides a new algorithm for link prediction in multiplex networks that can be applied to a plethora of systems.