 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Output Critique: Self-Correction via Task Distillation
Jan 31, 2026Large language models (LLMs) have shown promising self-correction abilities, where iterative refinement improves the quality of generated responses. However, most existing approaches operate at the level of output critique, patching surface errors while often failing to correct deeper reasoning flaws. We propose SELF-THOUGHT, a framework that introduces an intermediate step of task abstraction before solution refinement. Given an input and an initial response, the model first distills the task into a structured template that captures key variables, constraints, and problem structure. This abstraction then guides solution instantiation, grounding subsequent responses in a clearer understanding of the task and reducing error propagation. Crucially, we show that these abstractions can be transferred across models: templates generated by larger models can serve as structured guides for smaller LLMs, which typically struggle with intrinsic self-correction. By reusing distilled task structures, smaller models achieve more reliable refinements without heavy fine-tuning or reliance on external verifiers. Experiments across diverse reasoning tasks demonstrate that SELF-THOUGHT improves accuracy, robustness, and generalization for both large and small models, offering a scalable path toward more reliable self-correcting language systems.
Evaluating Style-Personalized Text Generation: Challenges and Directions
Aug 08, 2025While prior research has built tools and benchmarks towards style personalized text generation, there has been limited exploration of evaluation in low-resource author style personalized text generation space. Through this work, we question the effectiveness of the widely adopted evaluation metrics like BLEU and ROUGE, and explore other evaluation paradigms such as style embeddings and LLM-as-judge to holistically evaluate the style personalized text generation task. We evaluate these metrics and their ensembles using our style discrimination benchmark, that spans eight writing tasks, and evaluates across three settings, domain discrimination, authorship attribution, and LLM personalized vs non-personalized discrimination. We provide conclusive evidence to adopt ensemble of diverse evaluation metrics to effectively evaluate style personalized text generation.
Conversational User-AI Intervention: A Study on Prompt Rewriting for Improved LLM Response Generation
Mar 21, 2025Human-LLM conversations are increasingly becoming more pervasive in peoples' professional and personal lives, yet many users still struggle to elicit helpful responses from LLM Chatbots. One of the reasons for this issue is users' lack of understanding in crafting effective prompts that accurately convey their information needs. Meanwhile, the existence of real-world conversational datasets on the one hand, and the text understanding faculties of LLMs on the other, present a unique opportunity to study this problem, and its potential solutions at scale. Thus, in this paper we present the first LLM-centric study of real human-AI chatbot conversations, focused on investigating aspects in which user queries fall short of expressing information needs, and the potential of using LLMs to rewrite suboptimal user prompts. Our findings demonstrate that rephrasing ineffective prompts can elicit better responses from a conversational system, while preserving the user's original intent. Notably, the performance of rewrites improves in longer conversations, where contextual inferences about user needs can be made more accurately. Additionally, we observe that LLMs often need to -- and inherently do -- make \emph{plausible} assumptions about a user's intentions and goals when interpreting prompts. Our findings largely hold true across conversational domains, user intents, and LLMs of varying sizes and families, indicating the promise of using prompt rewriting as a solution for better human-AI interactions.
Group Preference Alignment: Customized LLM Response Generation from In-Situ Conversations
Mar 11, 2025LLMs often fail to meet the specialized needs of distinct user groups due to their one-size-fits-all training paradigm \cite{lucy-etal-2024-one} and there is limited research on what personalization aspects each group expect. To address these limitations, we propose a group-aware personalization framework, Group Preference Alignment (GPA), that identifies context-specific variations in conversational preferences across user groups and then steers LLMs to address those preferences. Our approach consists of two steps: (1) Group-Aware Preference Extraction, where maximally divergent user-group preferences are extracted from real-world conversation logs and distilled into interpretable rubrics, and (2) Tailored Response Generation, which leverages these rubrics through two methods: a) Context-Tuned Inference (GAP-CT), that dynamically adjusts responses via context-dependent prompt instructions, and b) Rubric-Finetuning Inference (GPA-FT), which uses the rubrics to generate contrastive synthetic data for personalization of group-specific models via alignment. Experiments demonstrate that our framework significantly improves alignment of the output with respect to user preferences and outperforms baseline methods, while maintaining robust performance on standard benchmarks.
Neon: News Entity-Interaction Extraction for Enhanced Question Answering
Nov 20, 2024



Capturing fresh information in near real-time and using it to augment existing large language models (LLMs) is essential to generate up-to-date, grounded, and reliable output. This problem becomes particularly challenging when LLMs are used for informational tasks in rapidly evolving fields, such as Web search related to recent or unfolding events involving entities, where generating temporally relevant responses requires access to up-to-the-hour news sources. However, the information modeled by the parametric memory of LLMs is often outdated, and Web results from prototypical retrieval systems may fail to capture the latest relevant information and struggle to handle conflicting reports in evolving news. To address this challenge, we present the NEON framework, designed to extract emerging entity interactions -- such as events or activities -- as described in news articles. NEON constructs an entity-centric timestamped knowledge graph that captures such interactions, thereby facilitating enhanced QA capabilities related to news events. Our framework innovates by integrating open Information Extraction (openIE) style tuples into LLMs to enable in-context retrieval-augmented generation. This integration demonstrates substantial improvements in QA performance when tackling temporal, entity-centric search queries. Through NEON, LLMs can deliver more accurate, reliable, and up-to-date responses.
ResearchAgent: Iterative Research Idea Generation over Scientific Literature with Large Language Models
Apr 11, 2024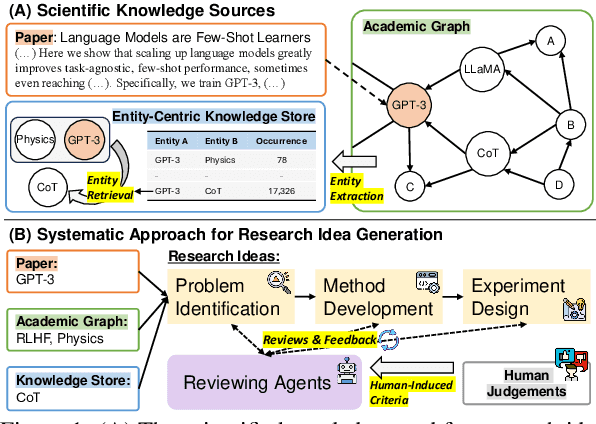


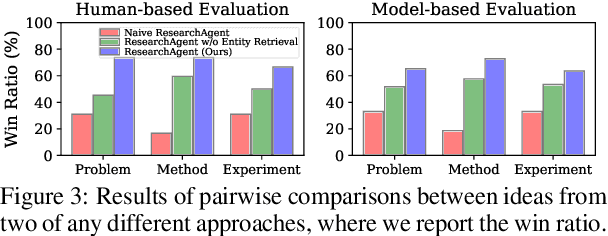
Scientific Research, vital for improving human life, is hindered by its inherent complexity, slow pace, and the need for specialized experts. To enhance its productivity, we propose a ResearchAgent, a large language model-powered research idea writing agent, which automatically generates problems, methods, and experiment designs while iteratively refining them based on scientific literature. Specifically, starting with a core paper as the primary focus to generate ideas, our ResearchAgent is augmented not only with relevant publications through connecting information over an academic graph but also entities retrieved from an entity-centric knowledge store based on their underlying concepts, mined and shared across numerous papers. In addition, mirroring the human approach to iteratively improving ideas with peer discussions, we leverage multiple ReviewingAgents that provide reviews and feedback iteratively. Further, they are instantiated with human preference-aligned large language models whose criteria for evaluation are derived from actual human judgments. We experimentally validate our ResearchAgent on scientific publications across multiple disciplines, showcasing its effectiveness in generating novel, clear, and valid research ideas based on human and model-based evaluation results.
Interpretable User Satisfaction Estimation for Conversational Systems with Large Language Models
Mar 19, 2024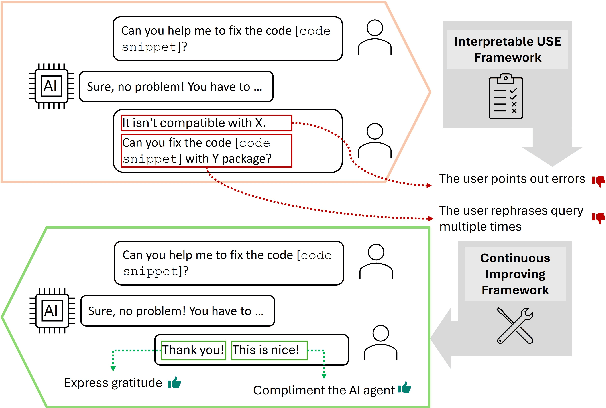
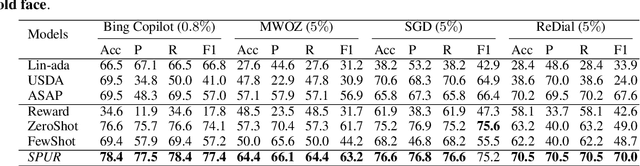
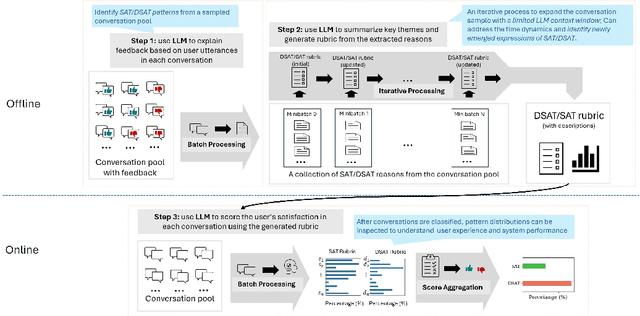
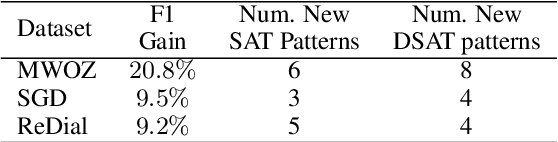
Accurate and interpretable user satisfaction estimation (USE) is critical for understanding, evaluating, and continuously improving conversational systems. Users express their satisfaction or dissatisfaction with diverse conversational patterns in both general-purpose (ChatGPT and Bing Copilot) and task-oriented (customer service chatbot) conversational systems. Existing approaches based on featurized ML models or text embeddings fall short in extracting generalizable patterns and are hard to interpret. In this work, we show that LLMs can extract interpretable signals of user satisfaction from their natural language utterances more effectively than embedding-based approaches. Moreover, an LLM can be tailored for USE via an iterative prompting framework using supervision from labeled examples. The resulting method, Supervised Prompting for User satisfaction Rubrics (SPUR), not only has higher accuracy but is more interpretable as it scores user satisfaction via learned rubrics with a detailed breakdown.
TnT-LLM: Text Mining at Scale with Large Language Models
Mar 18, 2024Transforming unstructured text into structured and meaningful forms, organized by useful category labels, is a fundamental step in text mining for downstream analysis and application. However, most existing methods for producing label taxonomies and building text-based label classifiers still rely heavily on domain expertise and manual curation, making the process expensive and time-consuming. This is particularly challenging when the label space is under-specified and large-scale data annotations are unavailable. In this paper, we address these challenges with Large Language Models (LLMs), whose prompt-based interface facilitates the induction and use of large-scale pseudo labels. We propose TnT-LLM, a two-phase framework that employs LLMs to automate the process of end-to-end label generation and assignment with minimal human effort for any given use-case. In the first phase, we introduce a zero-shot, multi-stage reasoning approach which enables LLMs to produce and refine a label taxonomy iteratively. In the second phase, LLMs are used as data labelers that yield training samples so that lightweight supervised classifiers can be reliably built, deployed, and served at scale. We apply TnT-LLM to the analysis of user intent and conversational domain for Bing Copilot (formerly Bing Chat), an open-domain chat-based search engine. Extensive experiments using both human and automatic evaluation metrics demonstrate that TnT-LLM generates more accurate and relevant label taxonomies when compared against state-of-the-art baselines, and achieves a favorable balance between accuracy and efficiency for classification at scale. We also share our practical experiences and insights on the challenges and opportunities of using LLMs for large-scale text mining in real-world applications.
Knowledge-Centric Templatic Views of Documents
Jan 13, 2024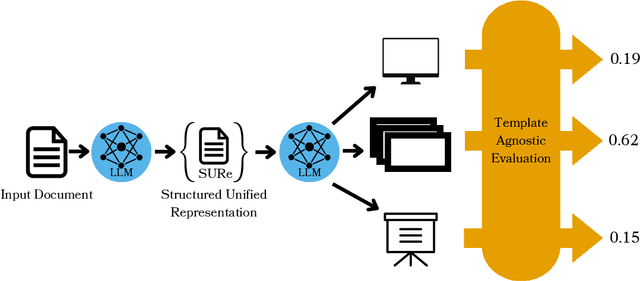

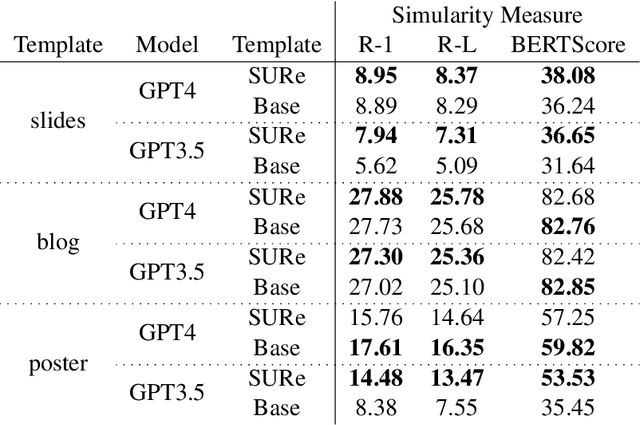
Authors seeking to communicate with broader audiences often compose their ideas about the same underlying knowledge in different documents and formats -- for example, as slide decks, newsletters, reports, brochures, etc. Prior work in document generation has generally considered the creation of each separate format to be different a task, developing independent methods for generation and evaluation. This approach is suboptimal for the advancement of AI-supported content authoring from both research and application perspectives because it leads to fragmented learning processes, redundancy in models and methods, and disjointed evaluation. Thus, in our work, we consider each of these documents to be templatic views of the same underlying knowledge, and we aim to unify the generation and evaluation of these templatic views of documents. We begin by introducing an LLM-powered method to extract the most important information from an input document and represent this information in a structured format. We show that this unified representation can be used to generate multiple templatic views with no supervision and with very little guidance, improving over strong baselines. We additionally introduce a unified evaluation method that is template agnostic, and can be adapted to building document generators for heterogeneous downstream applications. Finally, we conduct a human evaluation, which shows that humans prefer 82% of the downstream documents generated with our method. Furthermore, the newly proposed evaluation metric correlates more highly with human judgement than prior metrics, while providing a unified evaluation method.
Knowledge-Augmented Large Language Models for Personalized Contextual Query Suggestion
Nov 10, 2023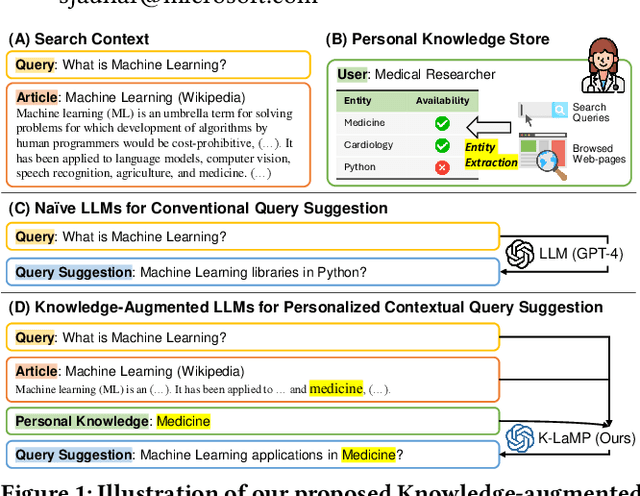


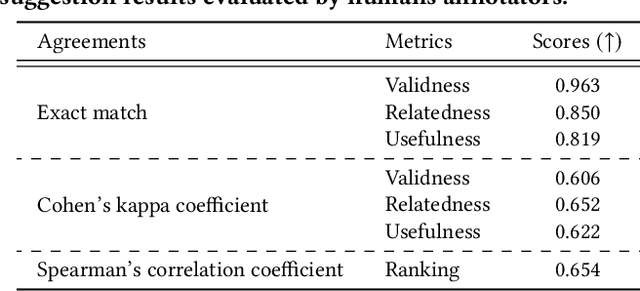
Large Language Models (LLMs) excel at tackling various natural language tasks. However, due to the significant costs involved in re-training or fine-tuning them, they remain largely static and difficult to personalize. Nevertheless, a variety of applications could benefit from generations that are tailored to users' preferences, goals, and knowledge. Among them is web search, where knowing what a user is trying to accomplish, what they care about, and what they know can lead to improved search experiences. In this work, we propose a novel and general approach that augments an LLM with relevant context from users' interaction histories with a search engine in order to personalize its outputs. Specifically, we construct an entity-centric knowledge store for each user based on their search and browsing activities on the web, which is then leveraged to provide contextually relevant LLM prompt augmentations. This knowledge store is light-weight, since it only produces user-specific aggregate projections of interests and knowledge onto public knowledge graphs, and leverages existing search log infrastructure, thereby mitigating the privacy, compliance, and scalability concerns associated with building deep user profiles for personalization. We then validate our approach on the task of contextual query suggestion, which requires understanding not only the user's current search context but also what they historically know and care about. Through a number of experiments based on human evaluation, we show that our approach is significantly better than several other LLM-powered baselines, generating query suggestions that are contextually more relevant, personalized, and useful.