 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMaking Large Language Models Better Data Creators
Oct 31, 2023



Although large language models (LLMs) have advanced the state-of-the-art in NLP significantly, deploying them for downstream applications is still challenging due to cost, responsiveness, control, or concerns around privacy and security. As such, trainable models are still the preferred option in some cases. However, these models still require human-labeled data for optimal performance, which is expensive and time-consuming to obtain. In order to address this issue, several techniques to reduce human effort involve labeling or generating data using LLMs. Although these methods are effective for certain applications, in practice they encounter difficulties in real-world scenarios. Labeling data requires careful data selection, while generating data necessitates task-specific prompt engineering. In this paper, we propose a unified data creation pipeline that requires only a single formatting example, and which is applicable to a broad range of tasks, including traditionally problematic ones with semantically devoid label spaces. In our experiments we demonstrate that instruction-following LLMs are highly cost-effective data creators, and that models trained with these data exhibit performance better than those trained with human-labeled data (by up to 17.5%) on out-of-distribution evaluation, while maintaining comparable performance on in-distribution tasks. These results have important implications for the robustness of NLP systems deployed in the real-world.
Deep Reinforcement Learning for Cybersecurity Threat Detection and Protection: A Review
Jun 06, 2022The cybersecurity threat landscape has lately become overly complex. Threat actors leverage weaknesses in the network and endpoint security in a very coordinated manner to perpetuate sophisticated attacks that could bring down the entire network and many critical hosts in the network. Increasingly advanced deep and machine learning-based solutions have been used in threat detection and protection. The application of these techniques has been reviewed well in the scientific literature. Deep Reinforcement Learning has shown great promise in developing AI-based solutions for areas that had earlier required advanced human cognizance. Different techniques and algorithms under deep reinforcement learning have shown great promise in applications ranging from games to industrial processes, where it is claimed to augment systems with general AI capabilities. These algorithms have recently also been used in cybersecurity, especially in threat detection and endpoint protection, where these are showing state-of-the-art results. Unlike supervised machines and deep learning, deep reinforcement learning is used in more diverse ways and is empowering many innovative applications in the threat defense landscape. However, there does not exist any comprehensive review of these unique applications and accomplishments. Therefore, in this paper, we intend to fill this gap and provide a comprehensive review of the different applications of deep reinforcement learning in cybersecurity threat detection and protection.
LSTM Hyper-Parameter Selection for Malware Detection: Interaction Effects and Hierarchical Selection Approach
Sep 23, 2021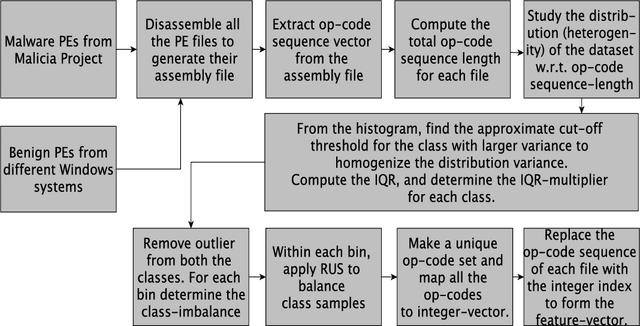
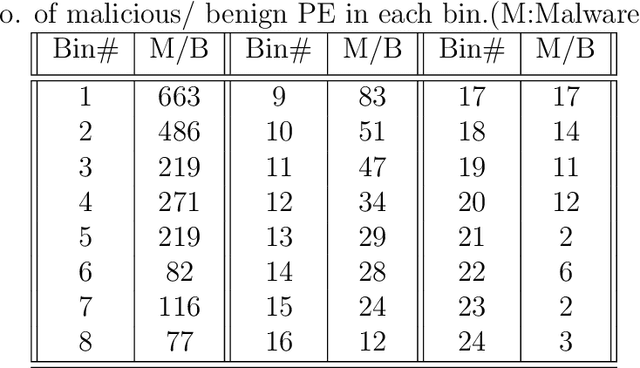

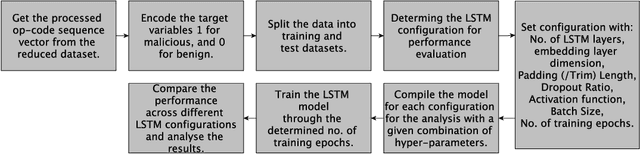
Long-Short-Term-Memory (LSTM) networks have shown great promise in artificial intelligence (AI) based language modeling. Recently, LSTM networks have also become popular for designing AI-based Intrusion Detection Systems (IDS). However, its applicability in IDS is studied largely in the default settings as used in language models. Whereas security applications offer distinct conditions and hence warrant careful consideration while applying such recurrent networks. Therefore, we conducted one of the most exhaustive works on LSTM hyper-parameters for IDS and experimented with approx. 150 LSTM configurations to determine its hyper-parameters relative importance, interaction effects, and optimal selection approach for designing an IDS. We conducted multiple analyses of the results of these experiments and empirically controlled for the interaction effects of different hyper-parameters covariate levels. We found that for security applications, especially for designing an IDS, neither similar relative importance as applicable to language models is valid, nor is the standard linear method for hyper-parameter selection ideal. We ascertained that the interaction effect plays a crucial role in determining the relative importance of hyper-parameters. We also discovered that after controlling for the interaction effect, the correct relative importance for LSTMs for an IDS is batch-size, followed by dropout ratio and padding. The findings are significant because when LSTM was first used for language models, the focus had mostly been on increasing the number of layers to enhance performance.
ADVERSARIALuscator: An Adversarial-DRL Based Obfuscator and Metamorphic Malware SwarmGenerator
Sep 23, 2021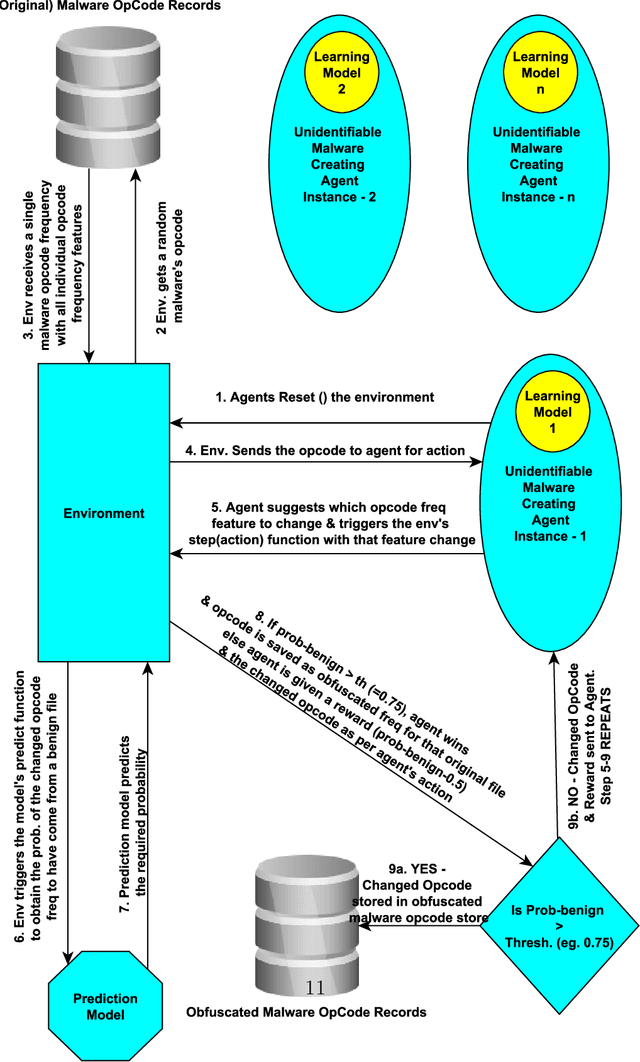

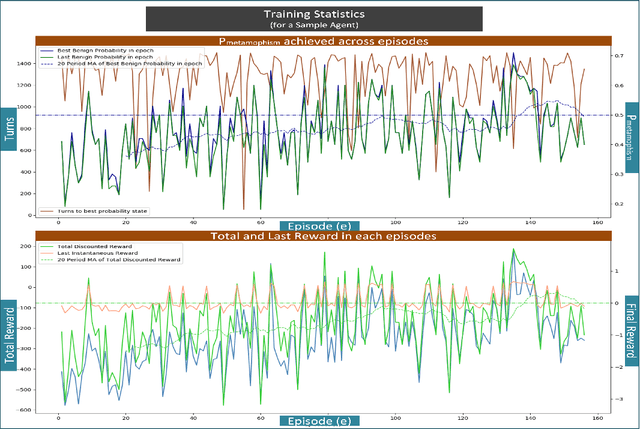
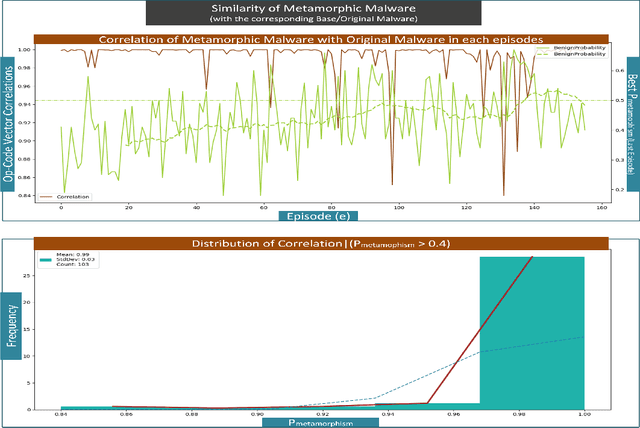
Advanced metamorphic malware and ransomware, by using obfuscation, could alter their internal structure with every attack. If such malware could intrude even into any of the IoT networks, then even if the original malware instance gets detected, by that time it can still infect the entire network. It is challenging to obtain training data for such evasive malware. Therefore, in this paper, we present ADVERSARIALuscator, a novel system that uses specialized Adversarial-DRL to obfuscate malware at the opcode level and create multiple metamorphic instances of the same. To the best of our knowledge, ADVERSARIALuscator is the first-ever system that adopts the Markov Decision Process-based approach to convert and find a solution to the problem of creating individual obfuscations at the opcode level. This is important as the machine language level is the least at which functionality could be preserved so as to mimic an actual attack effectively. ADVERSARIALuscator is also the first-ever system to use efficient continuous action control capable of deep reinforcement learning agents like the Proximal Policy Optimization in the area of cyber security. Experimental results indicate that ADVERSARIALuscator could raise the metamorphic probability of a corpus of malware by >0.45. Additionally, more than 33% of metamorphic instances generated by ADVERSARIALuscator were able to evade the most potent IDS. If such malware could intrude even into any of the IoT networks, then even if the original malware instance gets detected, by that time it can still infect the entire network. Hence ADVERSARIALuscator could be used to generate data representative of a swarm of very potent and coordinated AI-based metamorphic malware attacks. The so generated data and simulations could be used to bolster the defenses of an IDS against an actual AI-based metamorphic attack from advanced malware and ransomware.
DRo: A data-scarce mechanism to revolutionize the performance of Deep Learning based Security Systems
Sep 12, 2021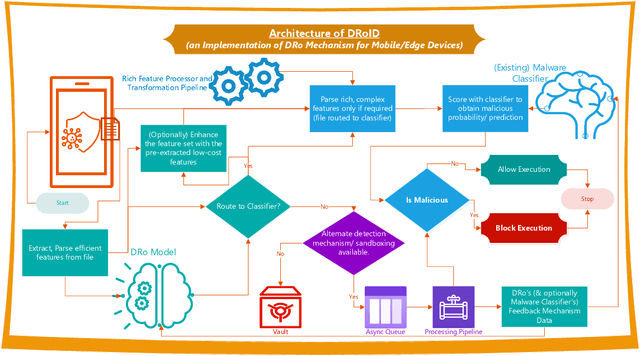
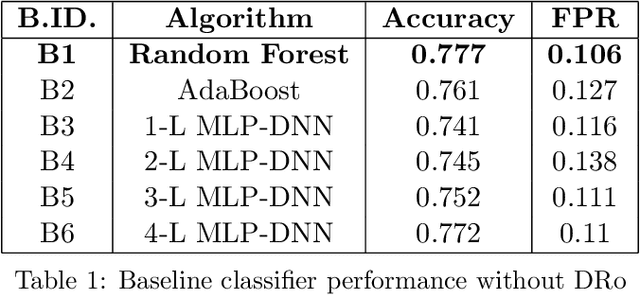
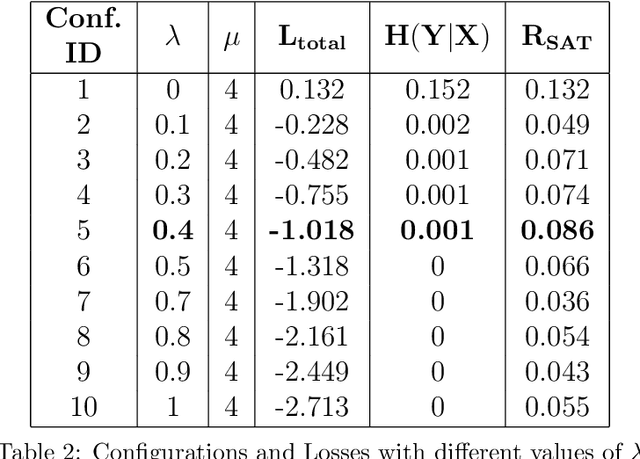
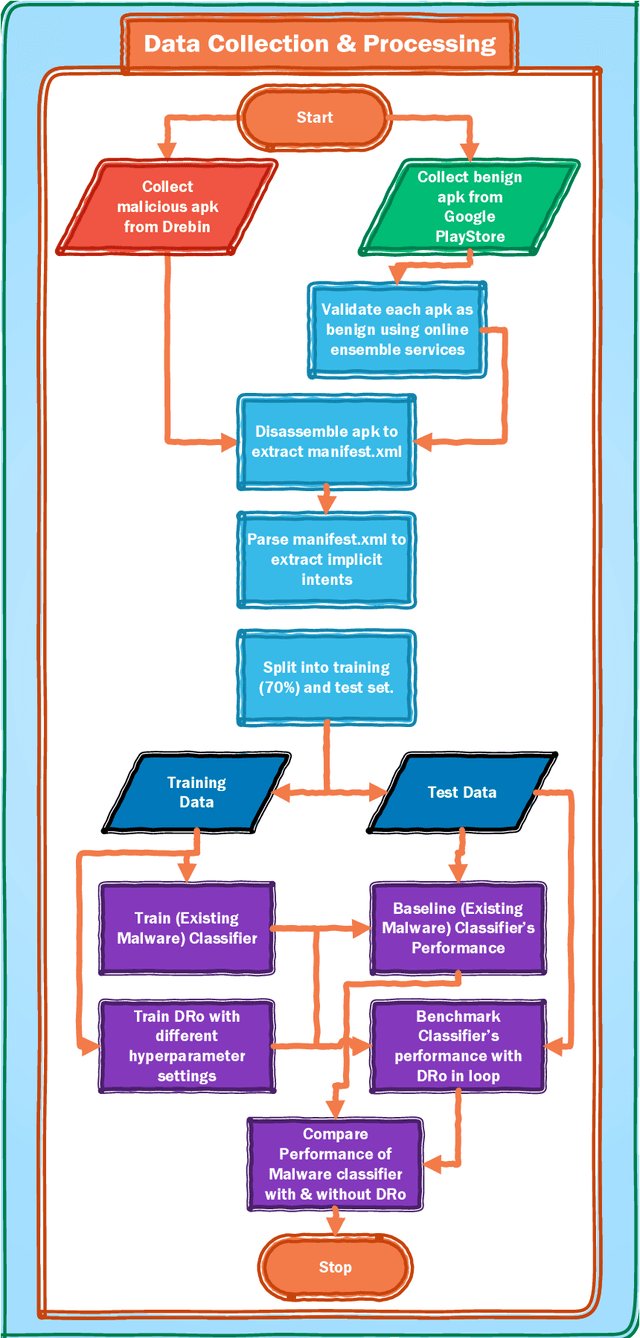
Supervised Deep Learning requires plenty of labeled data to converge, and hence perform optimally for task-specific learning. Therefore, we propose a novel mechanism named DRo (for Deep Routing) for data-scarce domains like security. The DRo approach builds upon some of the recent developments in Deep-Clustering. In particular, it exploits the self-augmented training mechanism using synthetically generated local perturbations. DRo not only allays the challenges with sparse-labeled data but also offers many unique advantages. We also developed a system named DRoID that uses the DRo mechanism for enhancing the performance of an existing Malware Detection System that uses (low information features like the) Android implicit Intent(s) as the only features. We conduct experiments on DRoID using a popular and standardized Android malware dataset and found that the DRo mechanism could successfully reduce the false-alarms generated by the downstream classifier by 67.9%, and also simultaneously boosts its accuracy by 11.3%. This is significant not only because the gains achieved are unparalleled but also because the features used were never considered rich enough to train a classifier on; and hence no decent performance could ever be reported by any malware classification system till-date using these features in isolation. Owing to the results achieved, the DRo mechanism claims a dominant position amongst all known systems that aims to enhance the classification performance of deep learning models with sparse-labeled data.
Identification of Significant Permissions for Efficient Android Malware Detection
Feb 28, 2021

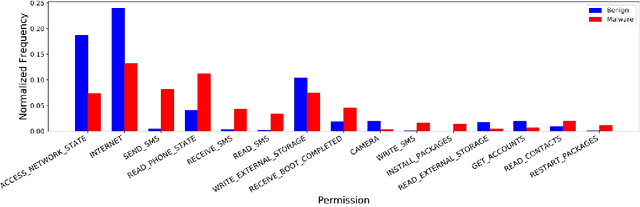

Since Google unveiled Android OS for smartphones, malware are thriving with 3Vs, i.e. volume, velocity, and variety. A recent report indicates that one out of every five business/industry mobile application leaks sensitive personal data. Traditional signature/heuristic-based malware detection systems are unable to cope up with current malware challenges and thus threaten the Android ecosystem. Therefore recently researchers have started exploring machine learning and deep learning based malware detection systems. In this paper, we performed a comprehensive feature analysis to identify the significant Android permissions and propose an efficient Android malware detection system using machine learning and deep neural network. We constructed a set of $16$ permissions ($8\%$ of the total set) derived from variance threshold, auto-encoders, and principal component analysis to build a malware detection engine that consumes less train and test time without significant compromise on the model accuracy. Our experimental results show that the Android malware detection model based on the random forest classifier is most balanced and achieves the highest area under curve score of $97.7\%$, which is better than the current state-of-art systems. We also observed that deep neural networks attain comparable accuracy to the baseline results but with a massive computational penalty.
Detection of Malicious Android Applications: Classical Machine Learning vs. Deep Neural Network Integrated with Clustering
Feb 28, 2021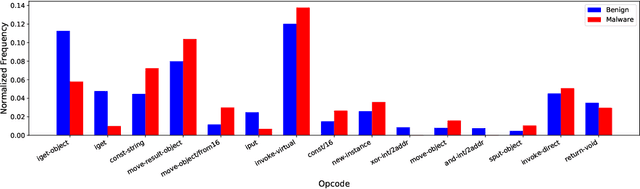
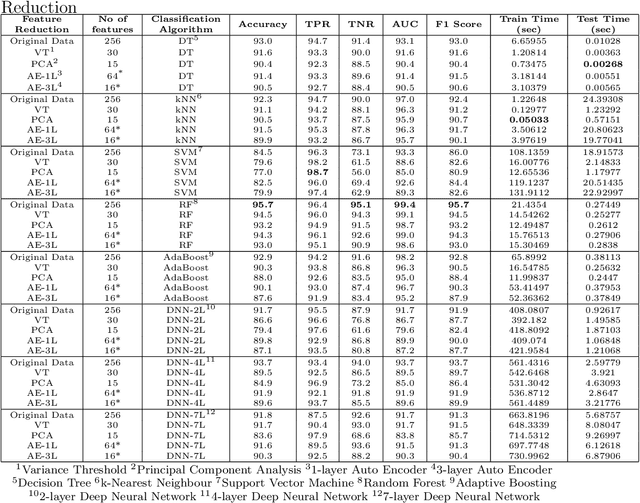
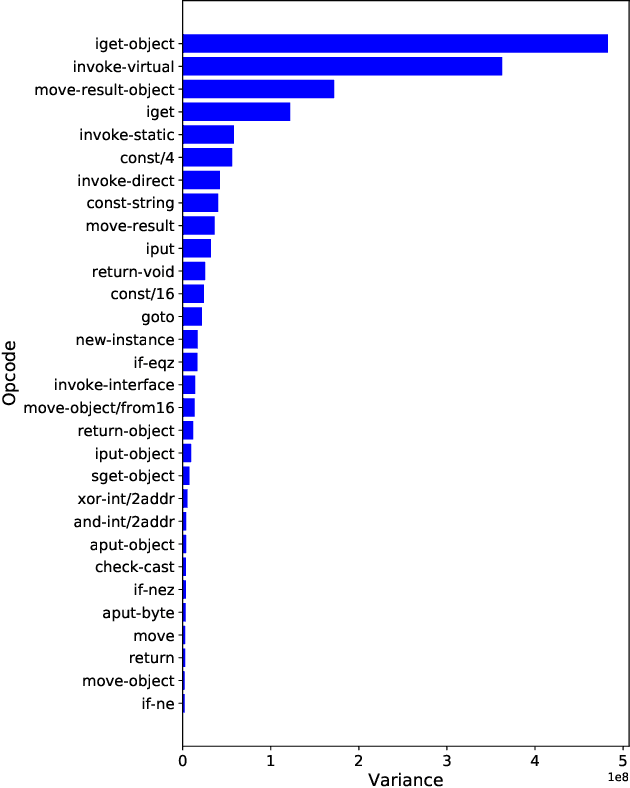
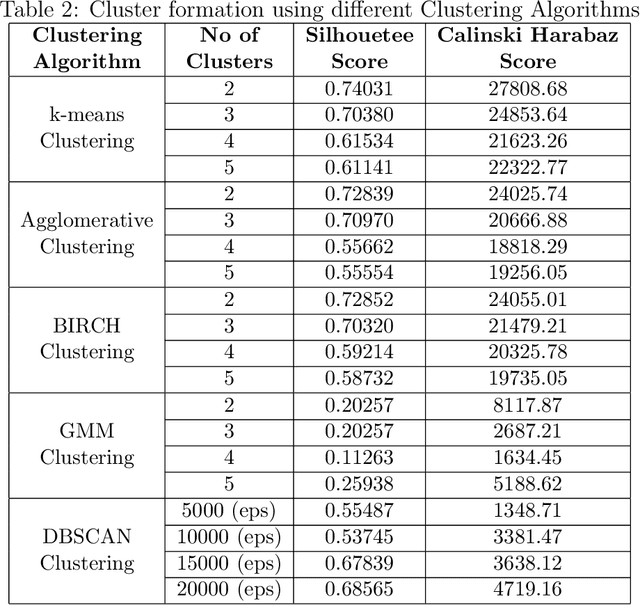
Today anti-malware community is facing challenges due to the ever-increasing sophistication and volume of malware attacks developed by adversaries. Traditional malware detection mechanisms are not able to cope-up with next-generation malware attacks. Therefore in this paper, we propose effective and efficient Android malware detection models based on machine learning and deep learning integrated with clustering. We performed a comprehensive study of different feature reduction, classification and clustering algorithms over various performance metrics to construct the Android malware detection models. Our experimental results show that malware detection models developed using Random Forest eclipsed deep neural network and other classifiers on the majority of performance metrics. The baseline Random Forest model without any feature reduction achieved the highest AUC of 99.4%. Also, the segregating of vector space using clustering integrated with Random Forest further boosted the AUC to 99.6% in one cluster and direct detection of Android malware in another cluster, thus reducing the curse of dimensionality. Additionally, we found that feature reduction in detection models does improve the model efficiency (training and testing time) many folds without much penalty on the effectiveness of the detection model.
DRLDO: A novel DRL based De-ObfuscationSystem for Defense against Metamorphic Malware
Feb 01, 2021

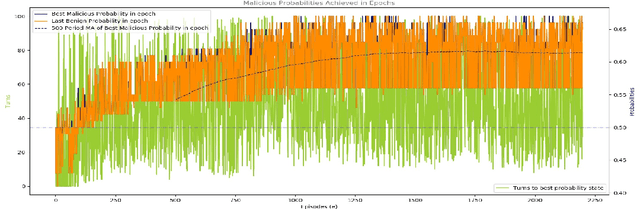
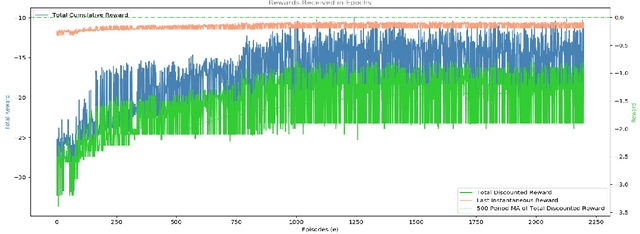
In this paper, we propose a novel mechanism to normalize metamorphic and obfuscated malware down at the opcode level and hence create an advanced metamorphic malware de-obfuscation and defense system. We name this system DRLDO, for Deep Reinforcement Learning based De-Obfuscator. With the inclusion of the DRLDO as a sub-component, an existing Intrusion Detection System could be augmented with defensive capabilities against 'zero-day' attacks from obfuscated and metamorphic variants of existing malware. This gains importance, not only because there exists no system to date that uses advanced DRL to intelligently and automatically normalize obfuscation down even to the opcode level, but also because the DRLDO system does not mandate any changes to the existing IDS. The DRLDO system does not even mandate the IDS' classifier to be retrained with any new dataset containing obfuscated samples. Hence DRLDO could be easily retrofitted into any existing IDS deployment. We designed, developed, and conducted experiments on the system to evaluate the same against multiple-simultaneous attacks from obfuscations generated from malware samples from a standardized dataset that contains multiple generations of malware. Experimental results prove that DRLDO was able to successfully make the otherwise un-detectable obfuscated variants of the malware detectable by an existing pre-trained malware classifier. The detection probability was raised well above the cut-off mark to 0.6 for the classifier to detect the obfuscated malware unambiguously. Further, the de-obfuscated variants generated by DRLDO achieved a very high correlation (of 0.99) with the base malware. This observation validates that the DRLDO system is actually learning to de-obfuscate and not exploiting a trivial trick.
Robust Android Malware Detection System against Adversarial Attacks using Q-Learning
Jan 27, 2021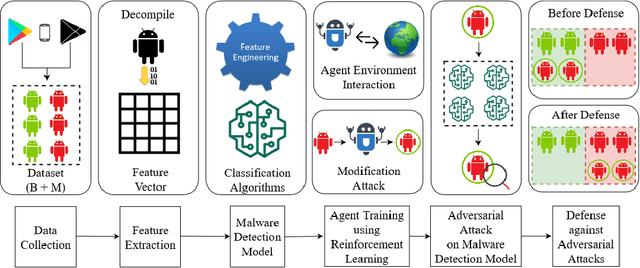


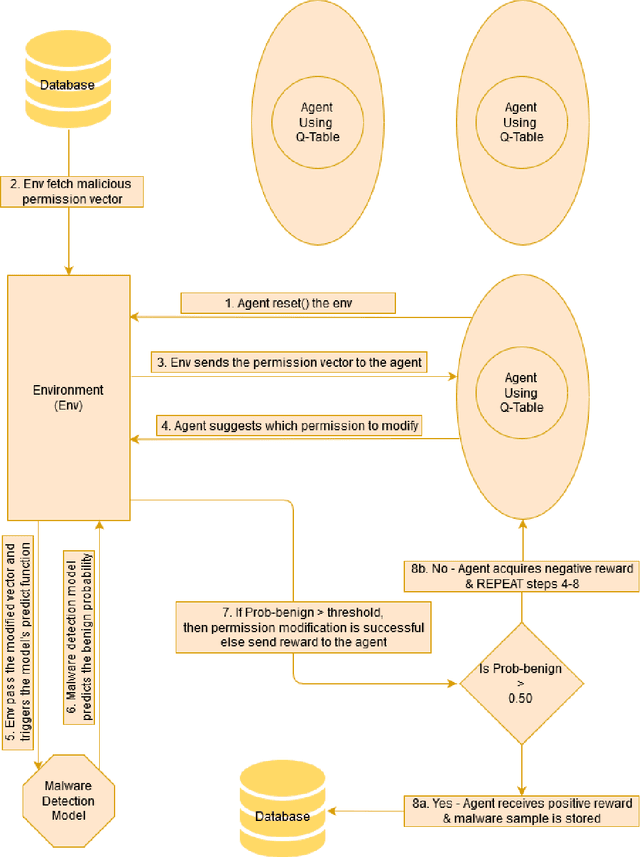
The current state-of-the-art Android malware detection systems are based on machine learning and deep learning models. Despite having superior performance, these models are susceptible to adversarial attacks. Therefore in this paper, we developed eight Android malware detection models based on machine learning and deep neural network and investigated their robustness against adversarial attacks. For this purpose, we created new variants of malware using Reinforcement Learning, which will be misclassified as benign by the existing Android malware detection models. We propose two novel attack strategies, namely single policy attack and multiple policy attack using reinforcement learning for white-box and grey-box scenario respectively. Putting ourselves in the adversary's shoes, we designed adversarial attacks on the detection models with the goal of maximizing fooling rate, while making minimum modifications to the Android application and ensuring that the app's functionality and behavior do not change. We achieved an average fooling rate of 44.21% and 53.20% across all the eight detection models with a maximum of five modifications using a single policy attack and multiple policy attack, respectively. The highest fooling rate of 86.09% with five changes was attained against the decision tree-based model using the multiple policy approach. Finally, we propose an adversarial defense strategy that reduces the average fooling rate by threefold to 15.22% against a single policy attack, thereby increasing the robustness of the detection models i.e. the proposed model can effectively detect variants (metamorphic) of malware. The experimental analysis shows that our proposed Android malware detection system using reinforcement learning is more robust against adversarial attacks.
Assessment of the Relative Importance of different hyper-parameters of LSTM for an IDS
Dec 26, 2020

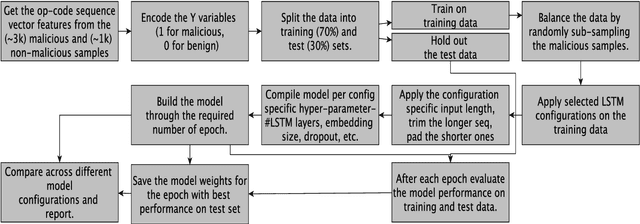
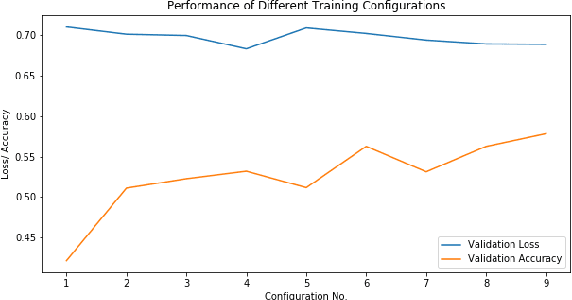
Recurrent deep learning language models like the LSTM are often used to provide advanced cyber-defense for high-value assets. The underlying assumption for using LSTM networks for malware-detection is that the op-code sequence of malware could be treated as a (spoken) language representation. There are differences between any spoken-language (sequence of words/sentences) and the machine-language (sequence of op-codes). In this paper, we demonstrate that due to these inherent differences, an LSTM model with its default configuration as tuned for a spoken-language, may not work well to detect malware (using its op-code sequence) unless the network's essential hyper-parameters are tuned appropriately. In the process, we also determine the relative importance of all the different hyper-parameters of an LSTM network as applied to malware detection using their op-code sequence representations. We experimented with different configurations of LSTM networks, and altered hyper-parameters like the embedding-size, number of hidden layers, number of LSTM-units in a hidden layer, pruning/padding-length of the input-vector, activation-function, and batch-size. We discovered that owing to the enhanced complexity of the malware/machine-language, the performance of an LSTM network configured for an Intrusion Detection System, is very sensitive towards the number-of-hidden-layers, input sequence-length, and the choice of the activation-function. Also, for (spoken) language-modeling, the recurrent architectures by-far outperform their non-recurrent counterparts. Therefore, we also assess how sequential DL architectures like the LSTM compare against their non-sequential counterparts like the MLP-DNN for the purpose of malware-detection.