 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultilingual unsupervised sequence segmentation transfers to extremely low-resource languages
Oct 16, 2021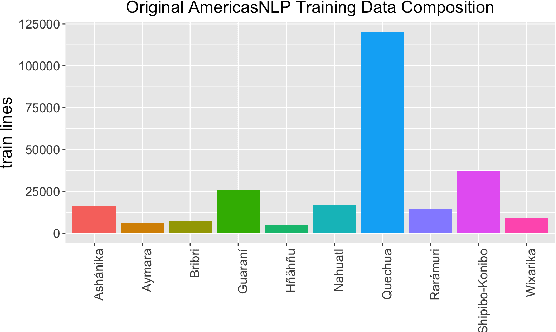

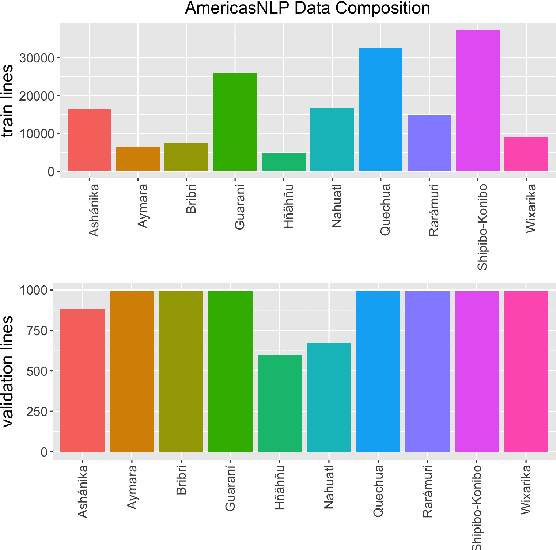

We show that unsupervised sequence-segmentation performance can be transferred to extremely low-resource languages by pre-training a Masked Segmental Language Model (Downey et al., 2021) multilingually. Further, we show that this transfer can be achieved by training over a collection of low-resource languages that are typologically similar (but phylogenetically unrelated) to the target language. In our experiments, we transfer from a collection of 10 Indigenous American languages (AmericasNLP, Mager et al., 2021) to K'iche', a Mayan language. We compare our model to a monolingual baseline, and show that the multilingual pre-trained approach yields much more consistent segmentation quality across target dataset sizes, including a zero-shot performance of 20.6 F1, and exceeds the monolingual performance in 9/10 experimental settings. These results have promising implications for low-resource NLP pipelines involving human-like linguistic units, such as the sparse transcription framework proposed by Bird (2020).
Probing Language Models for Understanding of Temporal Expressions
Oct 03, 2021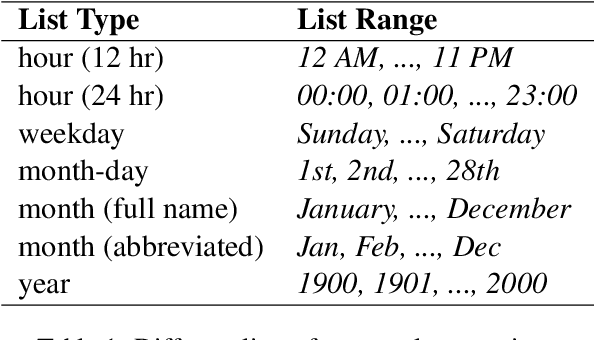
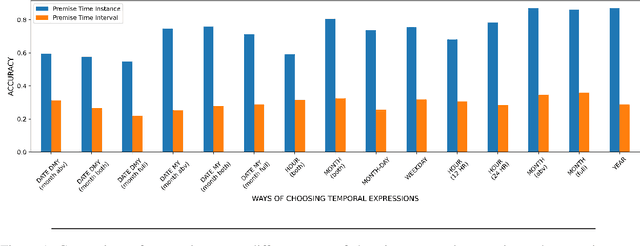

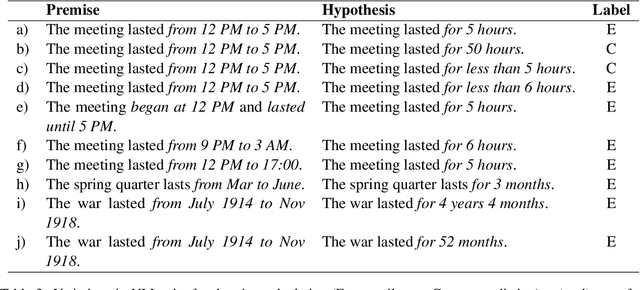
We present three Natural Language Inference (NLI) challenge sets that can evaluate NLI models on their understanding of temporal expressions. More specifically, we probe these models for three temporal properties: (a) the order between points in time, (b) the duration between two points in time, (c) the relation between the magnitude of times specified in different units. We find that although large language models fine-tuned on MNLI have some basic perception of the order between points in time, at large, these models do not have a thorough understanding of the relation between temporal expressions.
Detection of Malicious Android Applications: Classical Machine Learning vs. Deep Neural Network Integrated with Clustering
Feb 28, 2021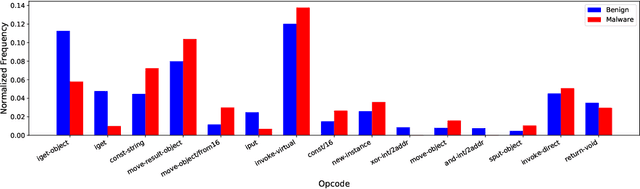
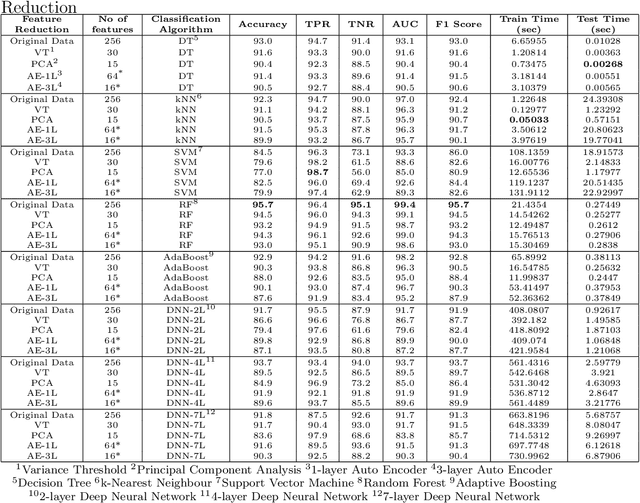
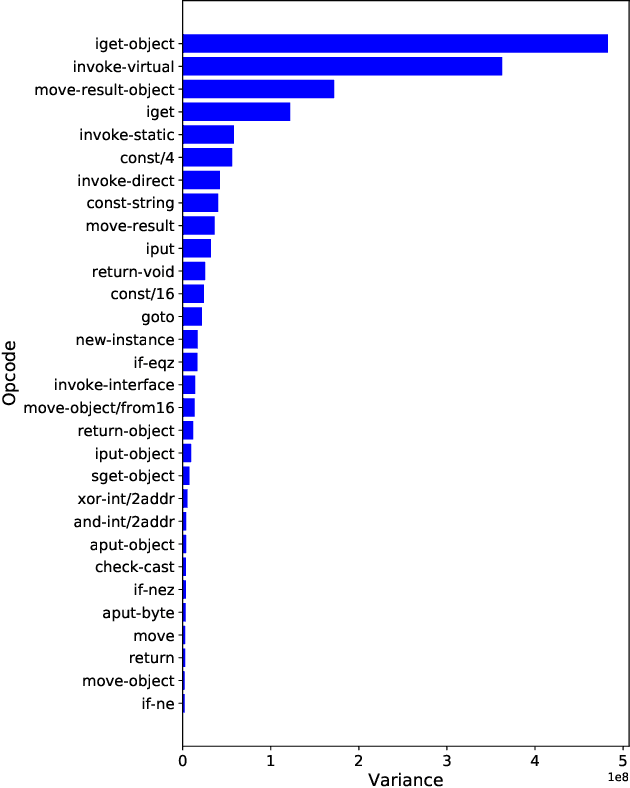
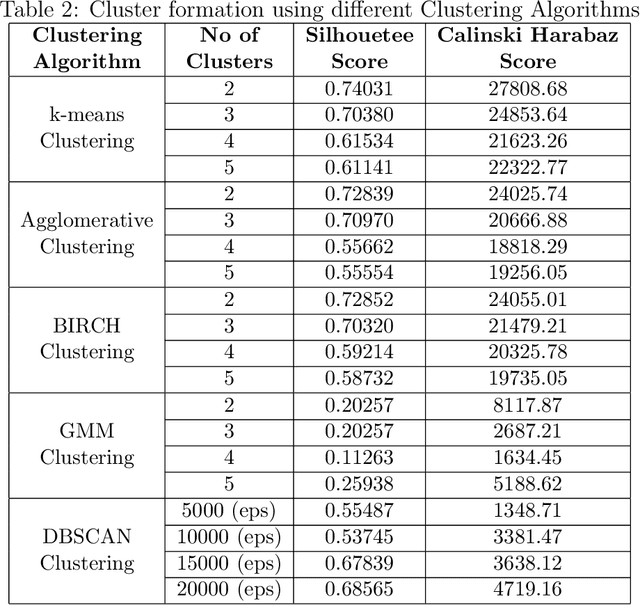
Today anti-malware community is facing challenges due to the ever-increasing sophistication and volume of malware attacks developed by adversaries. Traditional malware detection mechanisms are not able to cope-up with next-generation malware attacks. Therefore in this paper, we propose effective and efficient Android malware detection models based on machine learning and deep learning integrated with clustering. We performed a comprehensive study of different feature reduction, classification and clustering algorithms over various performance metrics to construct the Android malware detection models. Our experimental results show that malware detection models developed using Random Forest eclipsed deep neural network and other classifiers on the majority of performance metrics. The baseline Random Forest model without any feature reduction achieved the highest AUC of 99.4%. Also, the segregating of vector space using clustering integrated with Random Forest further boosted the AUC to 99.6% in one cluster and direct detection of Android malware in another cluster, thus reducing the curse of dimensionality. Additionally, we found that feature reduction in detection models does improve the model efficiency (training and testing time) many folds without much penalty on the effectiveness of the detection model.