 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultilingual unsupervised sequence segmentation transfers to extremely low-resource languages
Oct 16, 2021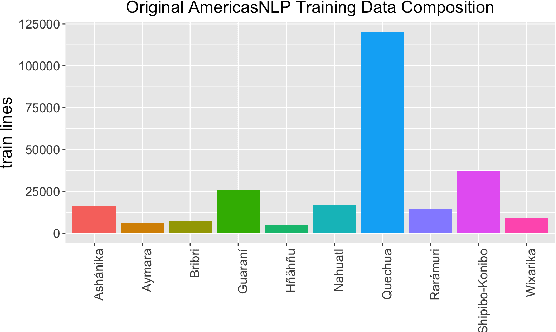

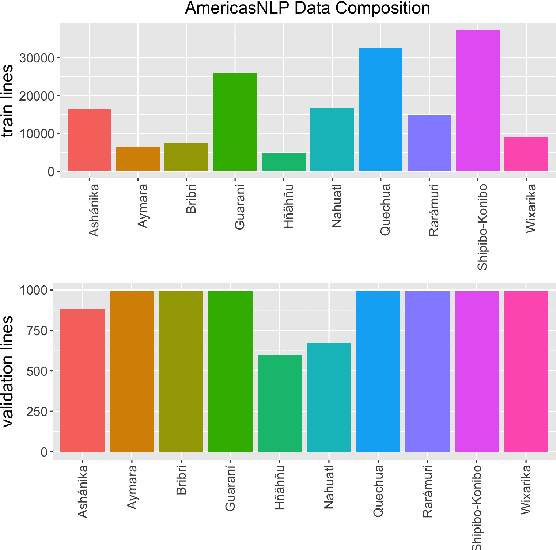

We show that unsupervised sequence-segmentation performance can be transferred to extremely low-resource languages by pre-training a Masked Segmental Language Model (Downey et al., 2021) multilingually. Further, we show that this transfer can be achieved by training over a collection of low-resource languages that are typologically similar (but phylogenetically unrelated) to the target language. In our experiments, we transfer from a collection of 10 Indigenous American languages (AmericasNLP, Mager et al., 2021) to K'iche', a Mayan language. We compare our model to a monolingual baseline, and show that the multilingual pre-trained approach yields much more consistent segmentation quality across target dataset sizes, including a zero-shot performance of 20.6 F1, and exceeds the monolingual performance in 9/10 experimental settings. These results have promising implications for low-resource NLP pipelines involving human-like linguistic units, such as the sparse transcription framework proposed by Bird (2020).