 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLinguistically Informed Evaluation of Multilingual ASR for African Languages
Feb 04, 2026Word Error Rate (WER) mischaracterizes ASR models' performance for African languages by combining phonological, tone, and other linguistic errors into a single lexical error. By contrast, Feature Error Rate (FER) has recently attracted attention as a viable metric that reveals linguistically meaningful errors in models' performance. In this paper, we evaluate three speech encoders on two African languages by complementing WER with CER, and FER, and add a tone-aware extension (TER). We show that by computing errors on phonological features, FER and TER reveal linguistically-salient error patterns even when word-level accuracy remains low. Our results reveal that models perform better on segmental features, while tones (especially mid and downstep) remain the most challenging features. Results on Yoruba show a striking differential in metrics, with WER=0.788, CER=0.305, and FER=0.151. Similarly for Uneme (an endangered language absent from pretraining data) a model with near-total WER and 0.461 CER achieves the relatively low FER of 0.267. This indicates model error is often attributable to individual phonetic feature errors, which is obscured by all-or-nothing metrics like WER.
Targeted Multilingual Adaptation for Low-resource Language Families
May 20, 2024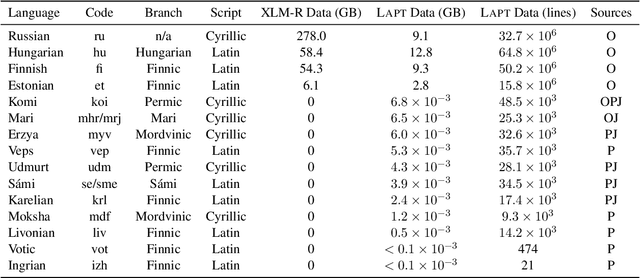
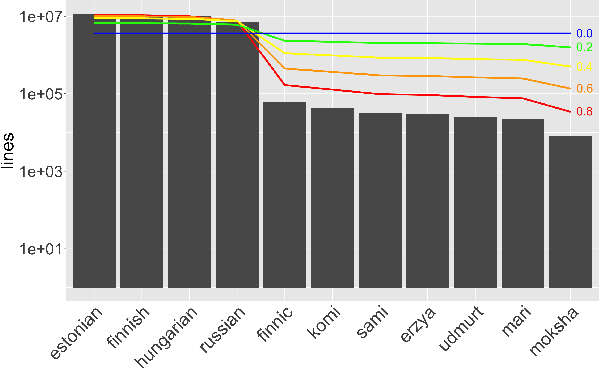
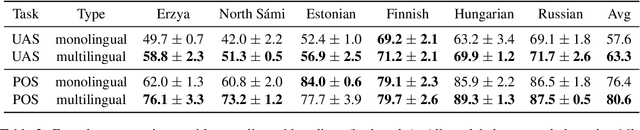
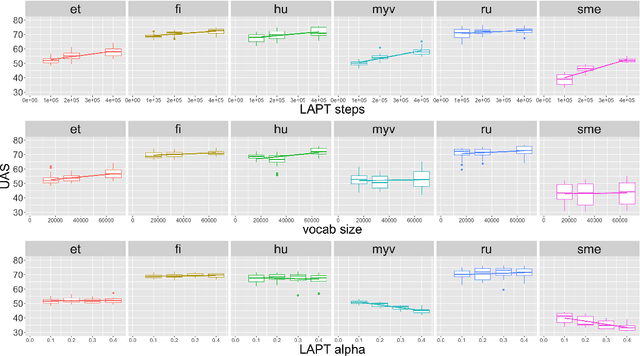
The "massively-multilingual" training of multilingual models is known to limit their utility in any one language, and they perform particularly poorly on low-resource languages. However, there is evidence that low-resource languages can benefit from targeted multilinguality, where the model is trained on closely related languages. To test this approach more rigorously, we systematically study best practices for adapting a pre-trained model to a language family. Focusing on the Uralic family as a test case, we adapt XLM-R under various configurations to model 15 languages; we then evaluate the performance of each experimental setting on two downstream tasks and 11 evaluation languages. Our adapted models significantly outperform mono- and multilingual baselines. Furthermore, a regression analysis of hyperparameter effects reveals that adapted vocabulary size is relatively unimportant for low-resource languages, and that low-resource languages can be aggressively up-sampled during training at little detriment to performance in high-resource languages. These results introduce new best practices for performing language adaptation in a targeted setting.
Embedding structure matters: Comparing methods to adapt multilingual vocabularies to new languages
Sep 09, 2023



Pre-trained multilingual language models underpin a large portion of modern NLP tools outside of English. A strong baseline for specializing these models for specific languages is Language-Adaptive Pre-Training (LAPT). However, retaining a large cross-lingual vocabulary and embedding matrix comes at considerable excess computational cost during adaptation. In this study, we propose several simple techniques to replace a cross-lingual vocabulary with a compact, language-specific one. Namely, we address strategies for re-initializing the token embedding matrix after vocabulary specialization. We then provide a systematic experimental comparison of our techniques, in addition to the recently-proposed Focus method. We demonstrate that: 1) Embedding-replacement techniques in the monolingual transfer literature are inadequate for adapting multilingual models. 2) Replacing cross-lingual vocabularies with smaller specialized ones provides an efficient method to improve performance in low-resource languages. 3) Simple embedding re-initialization techniques based on script-wise sub-distributions rival techniques such as Focus, which rely on similarity scores obtained from an auxiliary model.
Planting and Mitigating Memorized Content in Predictive-Text Language Models
Dec 16, 2022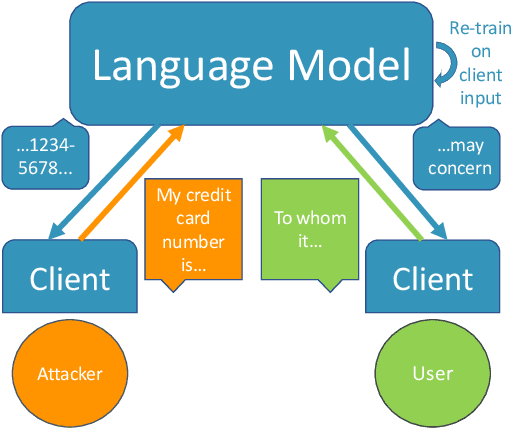
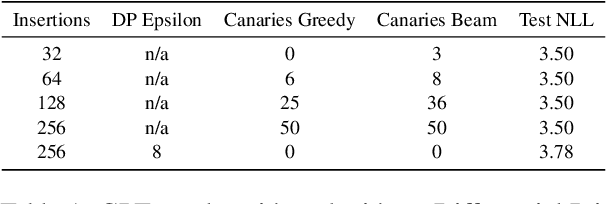
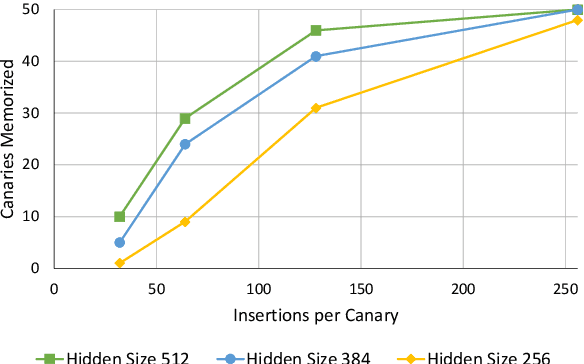
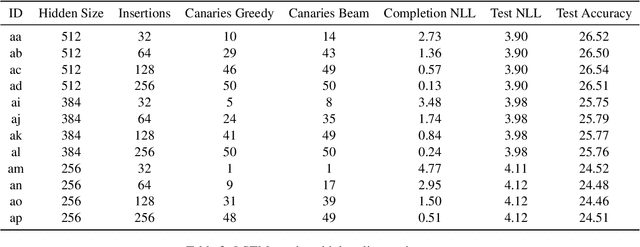
Language models are widely deployed to provide automatic text completion services in user products. However, recent research has revealed that language models (especially large ones) bear considerable risk of memorizing private training data, which is then vulnerable to leakage and extraction by adversaries. In this study, we test the efficacy of a range of privacy-preserving techniques to mitigate unintended memorization of sensitive user text, while varying other factors such as model size and adversarial conditions. We test both "heuristic" mitigations (those without formal privacy guarantees) and Differentially Private training, which provides provable levels of privacy at the cost of some model performance. Our experiments show that (with the exception of L2 regularization), heuristic mitigations are largely ineffective in preventing memorization in our test suite, possibly because they make too strong of assumptions about the characteristics that define "sensitive" or "private" text. In contrast, Differential Privacy reliably prevents memorization in our experiments, despite its computational and model-performance costs.
Learning to translate by learning to communicate
Jul 14, 2022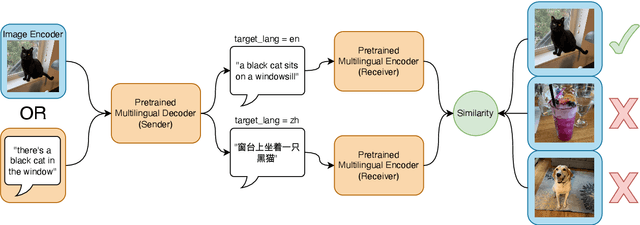
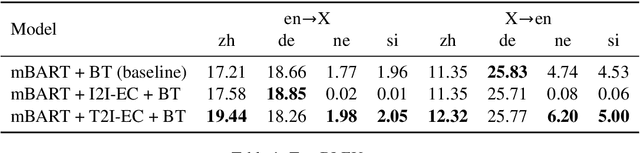
We formulate and test a technique to use Emergent Communication (EC) with a pretrained multilingual model to improve on modern Unsupervised NMT systems, especially for low-resource languages. It has been argued that the currently dominant paradigm in NLP of pretraining on text-only corpora will not yield robust natural language understanding systems, and the need for grounded, goal-oriented, and interactive language learning has been highlighted. In our approach, we embed a modern multilingual model (mBART, Liu et. al. 2020) into an EC image-reference game, in which the model is incentivized to use multilingual generations to accomplish a vision-grounded task, with the hypothesis that this will align multiple languages to a shared task space. We present two variants of EC Fine-Tuning (Steinert-Threlkeld et. al. 2022), one of which outperforms a backtranslation-based baseline in 6/8 translation settings, and proves especially beneficial for the very low-resource languages of Nepali and Sinhala.
Multilingual unsupervised sequence segmentation transfers to extremely low-resource languages
Oct 16, 2021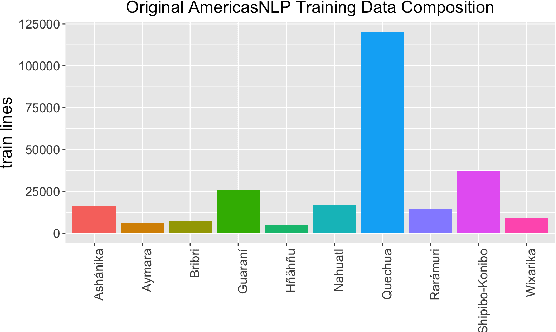

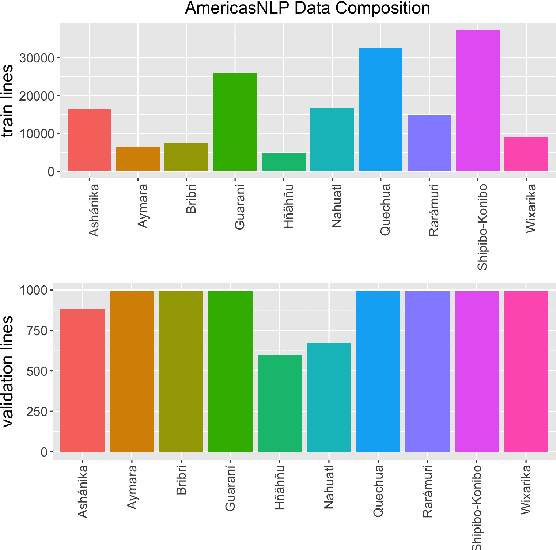

We show that unsupervised sequence-segmentation performance can be transferred to extremely low-resource languages by pre-training a Masked Segmental Language Model (Downey et al., 2021) multilingually. Further, we show that this transfer can be achieved by training over a collection of low-resource languages that are typologically similar (but phylogenetically unrelated) to the target language. In our experiments, we transfer from a collection of 10 Indigenous American languages (AmericasNLP, Mager et al., 2021) to K'iche', a Mayan language. We compare our model to a monolingual baseline, and show that the multilingual pre-trained approach yields much more consistent segmentation quality across target dataset sizes, including a zero-shot performance of 20.6 F1, and exceeds the monolingual performance in 9/10 experimental settings. These results have promising implications for low-resource NLP pipelines involving human-like linguistic units, such as the sparse transcription framework proposed by Bird (2020).
A Masked Segmental Language Model for Unsupervised Natural Language Segmentation
Apr 16, 2021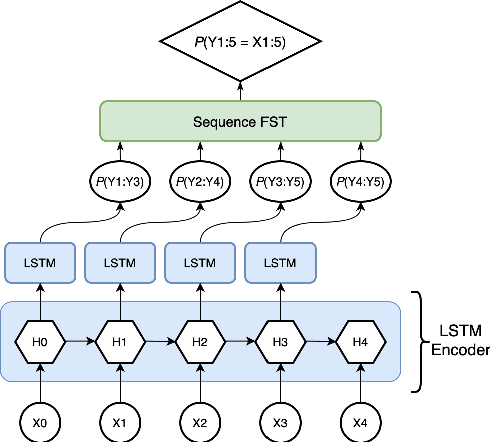
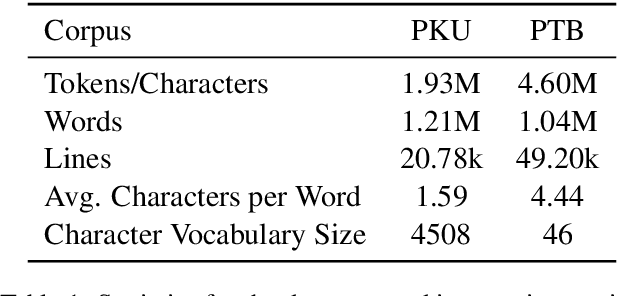
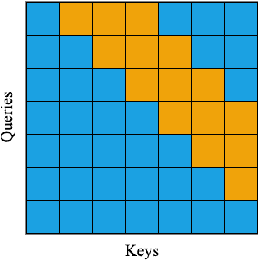
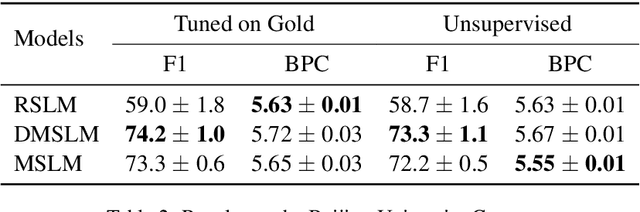
Segmentation remains an important preprocessing step both in languages where "words" or other important syntactic/semantic units (like morphemes) are not clearly delineated by white space, as well as when dealing with continuous speech data, where there is often no meaningful pause between words. Near-perfect supervised methods have been developed for use in resource-rich languages such as Chinese, but many of the world's languages are both morphologically complex, and have no large dataset of "gold" segmentations into meaningful units. To solve this problem, we propose a new type of Segmental Language Model (Sun and Deng, 2018; Kawakami et al., 2019; Wang et al., 2021) for use in both unsupervised and lightly supervised segmentation tasks. We introduce a Masked Segmental Language Model (MSLM) built on a span-masking transformer architecture, harnessing the power of a bi-directional masked modeling context and attention. In a series of experiments, our model consistently outperforms Recurrent SLMs on Chinese (PKU Corpus) in segmentation quality, and performs similarly to the Recurrent model on English (PTB). We conclude by discussing the different challenges posed in segmenting phonemic-type writing systems.