 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeParameter Alignment Mitigates Catastrophic Forgetting in Multilingual Expert Language Models
May 29, 2026While continual pretraining~(CPT) is a practical way to extend large language models to new languages, naïve finetuning on targeted data erodes existing capabilities through catastrophic forgetting. Organizing training around language families reduces cross-language interference but cannot alone prevent forgetting of the general knowledge needed for downstream tasks. We link this forgetting to parameter drift in multilingual CPT and present a suite of five layer-aware parameter alignment strategies: hard layer freezing, soft regularization, post-hoc weight reversion, and model merging. We systematically compare our alignment strategies against two unregularized CPT baselines on benchmarks spanning 32 training languages from five language families, plus held-out languages, across four evaluation axes: perplexity, reading comprehension, physical reasoning, and translation. Parameter alignment substantially reduces forgetting at minimal cost to language acquisition: layer freezing and regularization best preserve comprehension, whereas post-hoc reversion yields the strongest translation gains. Together, these results map the acquisition--forgetting frontier for family-expert CPT and offer practical deployment guidelines pairing each strategy to the tasks it best serves.
Accommodation Goes Both Ways: Studying Linguistic Convergence Between Humans and Language Models
May 28, 2026As LLMs become increasingly integrated into daily life, understanding how their presence will shape human linguistic behavior is an open question. We present a large-scale study of linguistic convergence in human-LLM dialogue, examining how humans and LLMs accommodate each other's linguistic style during multi-turn conversations. Using an asymmetric convergence metric on WildChat, a corpus of real-world ChatGPT transcripts, we find that while LLMs significantly overconverge toward their users on both function word and open-class features across eight languages, human convergence rates in this setting are broadly consistent with human-human baselines. These findings suggest that accommodation in human-LLM dialogue is asymmetric: while LLMs dramatically overfit to their users' style, humans linguistically accommodate LLMs no differently than they would another person.
Universal NER v2: Towards a Massively Multilingual Named Entity Recognition Benchmark
Apr 14, 2026While multilingual language models promise to bring the benefits of LLMs to speakers of many languages, gold-standard evaluation benchmarks in most languages to interrogate these assumptions remain scarce. The Universal NER project, now entering its fourth year, is dedicated to building gold-standard multilingual Named Entity Recognition (NER) benchmark datasets. Inspired by existing massively multilingual efforts for other core NLP tasks (e.g., Universal Dependencies), the project uses a general tagset and thorough annotation guidelines to collect standardized, cross-lingual annotations of named entity spans. The first installment (UNER v1) was released in 2024, and the project has continued and expanded since then, with various organizers, annotators, and collaborators in an active community.
Calibration Is Not Enough: Evaluating Confidence Estimation Under Language Variations
Jan 12, 2026Confidence estimation (CE) indicates how reliable the answers of large language models (LLMs) are, and can impact user trust and decision-making. Existing work evaluates CE methods almost exclusively through calibration, examining whether stated confidence aligns with accuracy, or discrimination, whether confidence is ranked higher for correct predictions than incorrect ones. However, these facets ignore pitfalls of CE in the context of LLMs and language variation: confidence estimates should remain consistent under semantically equivalent prompt or answer variations, and should change when the answer meaning differs. Therefore, we present a comprehensive evaluation framework for CE that measures their confidence quality on three new aspects: robustness of confidence against prompt perturbations, stability across semantic equivalent answers, and sensitivity to semantically different answers. In our work, we demonstrate that common CE methods for LLMs often fail on these metrics: methods that achieve good performance on calibration or discrimination are not robust to prompt variations or are not sensitive to answer changes. Overall, our framework reveals limitations of existing CE evaluations relevant for real-world LLM use cases and provides practical guidance for selecting and designing more reliable CE methods.
Relation Extraction or Pattern Matching? Unravelling the Generalisation Limits of Language Models for Biographical RE
May 18, 2025



Analysing the generalisation capabilities of relation extraction (RE) models is crucial for assessing whether they learn robust relational patterns or rely on spurious correlations. Our cross-dataset experiments find that RE models struggle with unseen data, even within similar domains. Notably, higher intra-dataset performance does not indicate better transferability, instead often signaling overfitting to dataset-specific artefacts. Our results also show that data quality, rather than lexical similarity, is key to robust transfer, and the choice of optimal adaptation strategy depends on the quality of data available: while fine-tuning yields the best cross-dataset performance with high-quality data, few-shot in-context learning (ICL) is more effective with noisier data. However, even in these cases, zero-shot baselines occasionally outperform all cross-dataset results. Structural issues in RE benchmarks, such as single-relation per sample constraints and non-standardised negative class definitions, further hinder model transferability.
Does Liking Yellow Imply Driving a School Bus? Semantic Leakage in Language Models
Aug 12, 2024Despite their wide adoption, the biases and unintended behaviors of language models remain poorly understood. In this paper, we identify and characterize a phenomenon never discussed before, which we call semantic leakage, where models leak irrelevant information from the prompt into the generation in unexpected ways. We propose an evaluation setting to detect semantic leakage both by humans and automatically, curate a diverse test suite for diagnosing this behavior, and measure significant semantic leakage in 13 flagship models. We also show that models exhibit semantic leakage in languages besides English and across different settings and generation scenarios. This discovery highlights yet another type of bias in language models that affects their generation patterns and behavior.
Targeted Multilingual Adaptation for Low-resource Language Families
May 20, 2024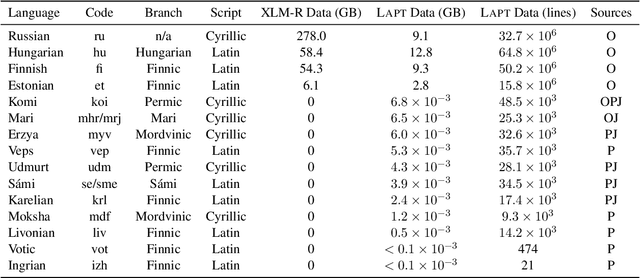
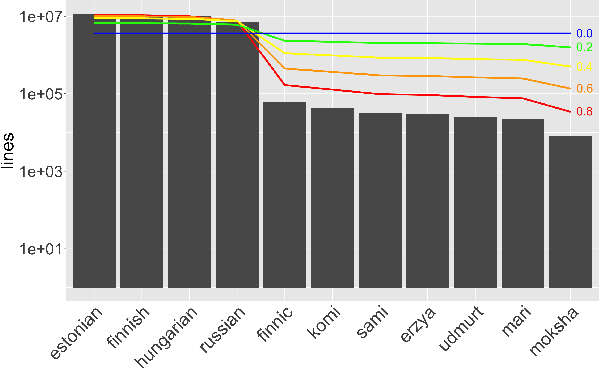
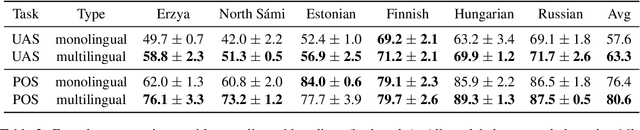
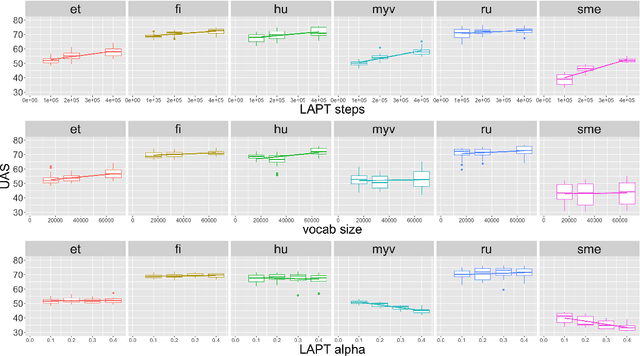
The "massively-multilingual" training of multilingual models is known to limit their utility in any one language, and they perform particularly poorly on low-resource languages. However, there is evidence that low-resource languages can benefit from targeted multilinguality, where the model is trained on closely related languages. To test this approach more rigorously, we systematically study best practices for adapting a pre-trained model to a language family. Focusing on the Uralic family as a test case, we adapt XLM-R under various configurations to model 15 languages; we then evaluate the performance of each experimental setting on two downstream tasks and 11 evaluation languages. Our adapted models significantly outperform mono- and multilingual baselines. Furthermore, a regression analysis of hyperparameter effects reveals that adapted vocabulary size is relatively unimportant for low-resource languages, and that low-resource languages can be aggressively up-sampled during training at little detriment to performance in high-resource languages. These results introduce new best practices for performing language adaptation in a targeted setting.
MYTE: Morphology-Driven Byte Encoding for Better and Fairer Multilingual Language Modeling
Mar 15, 2024A major consideration in multilingual language modeling is how to best represent languages with diverse vocabularies and scripts. Although contemporary text encoding methods cover most of the world's writing systems, they exhibit bias towards the high-resource languages of the Global West. As a result, texts of underrepresented languages tend to be segmented into long sequences of linguistically meaningless units. To address the disparities, we introduce a new paradigm that encodes the same information with segments of consistent size across diverse languages. Our encoding convention (MYTE) is based on morphemes, as their inventories are more balanced across languages than characters, which are used in previous methods. We show that MYTE produces shorter encodings for all 99 analyzed languages, with the most notable improvements for non-European languages and non-Latin scripts. This, in turn, improves multilingual LM performance and diminishes the perplexity gap throughout diverse languages.
Comparing Hallucination Detection Metrics for Multilingual Generation
Feb 16, 2024While many automatic hallucination detection techniques have been proposed for English texts, their effectiveness in multilingual contexts remains unexplored. This paper aims to bridge the gap in understanding how these hallucination detection metrics perform on non-English languages. We evaluate the efficacy of various detection metrics, including lexical metrics like ROUGE and Named Entity Overlap and Natural Language Inference (NLI)-based metrics, at detecting hallucinations in biographical summaries in many languages; we also evaluate how correlated these different metrics are to gauge whether they measure the same phenomena. Our empirical analysis reveals that while lexical metrics show limited effectiveness, NLI-based metrics perform well in high-resource languages at the sentence level. In contrast, NLI-based metrics often fail to detect atomic fact hallucinations. Our findings highlight existing gaps in multilingual hallucination detection and motivate future research to develop more robust detection methods for LLM hallucination in other languages.
Breaking the Curse of Multilinguality with Cross-lingual Expert Language Models
Jan 19, 2024



Despite their popularity in non-English NLP, multilingual language models often underperform monolingual ones due to inter-language competition for model parameters. We propose Cross-lingual Expert Language Models (X-ELM), which mitigate this competition by independently training language models on subsets of the multilingual corpus. This process specializes X-ELMs to different languages while remaining effective as a multilingual ensemble. Our experiments show that when given the same compute budget, X-ELM outperforms jointly trained multilingual models across all considered languages and that these gains transfer to downstream tasks. X-ELM provides additional benefits over performance improvements: new experts can be iteratively added, adapting X-ELM to new languages without catastrophic forgetting. Furthermore, training is asynchronous, reducing the hardware requirements for multilingual training and democratizing multilingual modeling.