 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards More Accurate Prediction of Human Empathy and Emotion in Text and Multi-turn Conversations by Combining Advanced NLP, Transformers-based Networks, and Linguistic Methodologies
Jul 26, 2024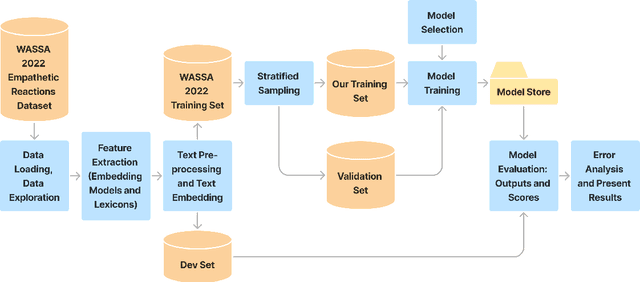
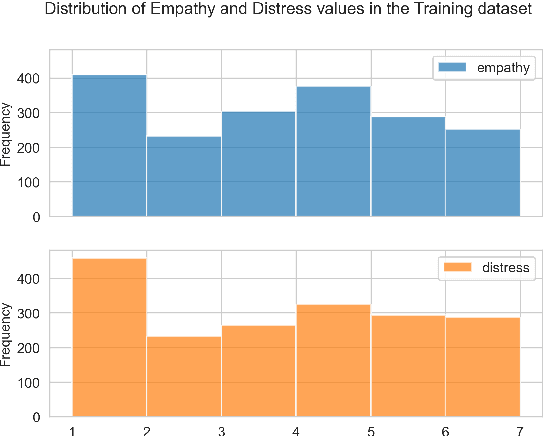

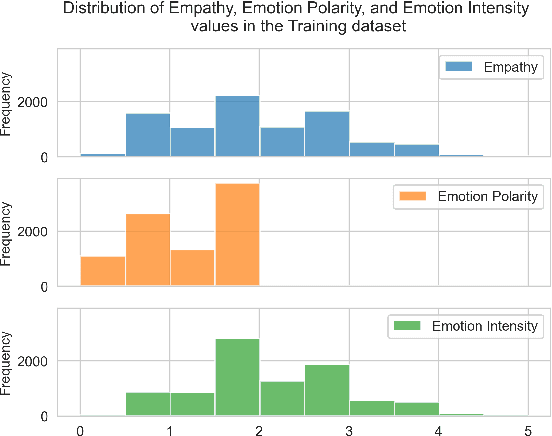
Based on the WASSA 2022 Shared Task on Empathy Detection and Emotion Classification, we predict the level of empathic concern and personal distress displayed in essays. For the first stage of this project we implemented a Feed-Forward Neural Network using sentence-level embeddings as features. We experimented with four different embedding models for generating the inputs to the neural network. The subsequent stage builds upon the previous work and we have implemented three types of revisions. The first revision focuses on the enhancements to the model architecture and the training approach. The second revision focuses on handling class imbalance using stratified data sampling. The third revision focuses on leveraging lexical resources, where we apply four different resources to enrich the features associated with the dataset. During the final stage of this project, we have created the final end-to-end system for the primary task using an ensemble of models to revise primary task performance. Additionally, as part of the final stage, these approaches have been adapted to the WASSA 2023 Shared Task on Empathy Emotion and Personality Detection in Interactions, in which the empathic concern, emotion polarity, and emotion intensity in dyadic text conversations are predicted.
Embedding structure matters: Comparing methods to adapt multilingual vocabularies to new languages
Sep 09, 2023



Pre-trained multilingual language models underpin a large portion of modern NLP tools outside of English. A strong baseline for specializing these models for specific languages is Language-Adaptive Pre-Training (LAPT). However, retaining a large cross-lingual vocabulary and embedding matrix comes at considerable excess computational cost during adaptation. In this study, we propose several simple techniques to replace a cross-lingual vocabulary with a compact, language-specific one. Namely, we address strategies for re-initializing the token embedding matrix after vocabulary specialization. We then provide a systematic experimental comparison of our techniques, in addition to the recently-proposed Focus method. We demonstrate that: 1) Embedding-replacement techniques in the monolingual transfer literature are inadequate for adapting multilingual models. 2) Replacing cross-lingual vocabularies with smaller specialized ones provides an efficient method to improve performance in low-resource languages. 3) Simple embedding re-initialization techniques based on script-wise sub-distributions rival techniques such as Focus, which rely on similarity scores obtained from an auxiliary model.