 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards More Accurate Prediction of Human Empathy and Emotion in Text and Multi-turn Conversations by Combining Advanced NLP, Transformers-based Networks, and Linguistic Methodologies
Jul 26, 2024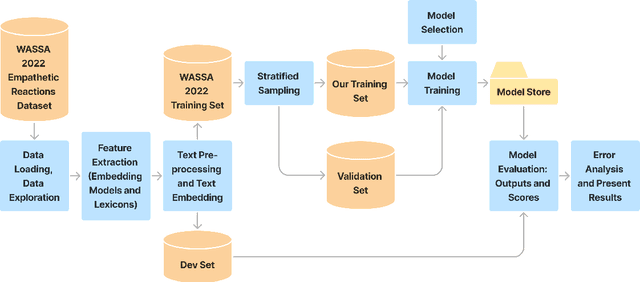
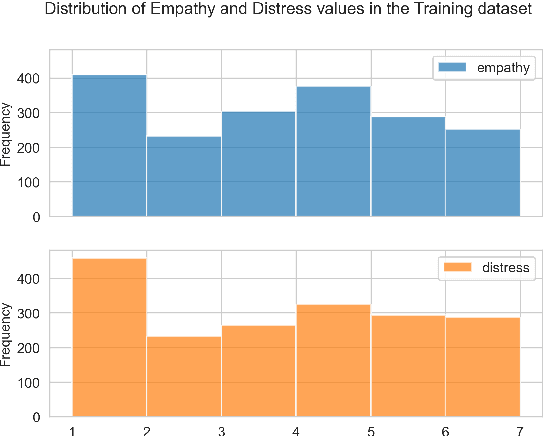

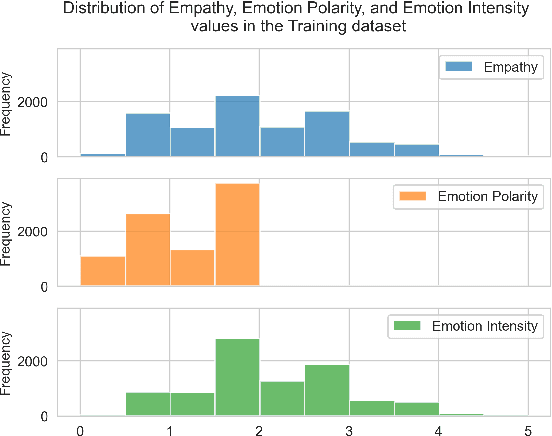
Based on the WASSA 2022 Shared Task on Empathy Detection and Emotion Classification, we predict the level of empathic concern and personal distress displayed in essays. For the first stage of this project we implemented a Feed-Forward Neural Network using sentence-level embeddings as features. We experimented with four different embedding models for generating the inputs to the neural network. The subsequent stage builds upon the previous work and we have implemented three types of revisions. The first revision focuses on the enhancements to the model architecture and the training approach. The second revision focuses on handling class imbalance using stratified data sampling. The third revision focuses on leveraging lexical resources, where we apply four different resources to enrich the features associated with the dataset. During the final stage of this project, we have created the final end-to-end system for the primary task using an ensemble of models to revise primary task performance. Additionally, as part of the final stage, these approaches have been adapted to the WASSA 2023 Shared Task on Empathy Emotion and Personality Detection in Interactions, in which the empathic concern, emotion polarity, and emotion intensity in dyadic text conversations are predicted.
Constructing the CORD-19 Vaccine Dataset
Jul 26, 2024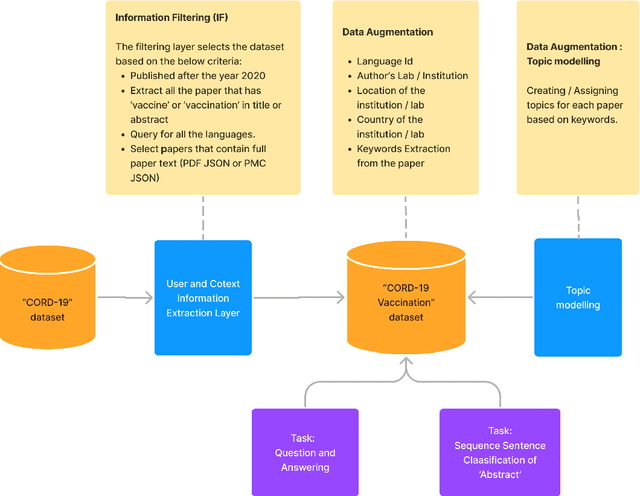



We introduce new dataset 'CORD-19-Vaccination' to cater to scientists specifically looking into COVID-19 vaccine-related research. This dataset is extracted from CORD-19 dataset [Wang et al., 2020] and augmented with new columns for language detail, author demography, keywords, and topic per paper. Facebook's fastText model is used to identify languages [Joulin et al., 2016]. To establish author demography (author affiliation, lab/institution location, and lab/institution country columns) we processed the JSON file for each paper and then further enhanced using Google's search API to determine country values. 'Yake' was used to extract keywords from the title, abstract, and body of each paper and the LDA (Latent Dirichlet Allocation) algorithm was used to add topic information [Campos et al., 2020, 2018a,b]. To evaluate the dataset, we demonstrate a question-answering task like the one used in the CORD-19 Kaggle challenge [Goldbloom et al., 2022]. For further evaluation, sequential sentence classification was performed on each paper's abstract using the model from Dernoncourt et al. [2016]. We partially hand annotated the training dataset and used a pre-trained BERT-PubMed layer. 'CORD- 19-Vaccination' contains 30k research papers and can be immensely valuable for NLP research such as text mining, information extraction, and question answering, specific to the domain of COVID-19 vaccine research.