 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConstructing the CORD-19 Vaccine Dataset
Paper and Code
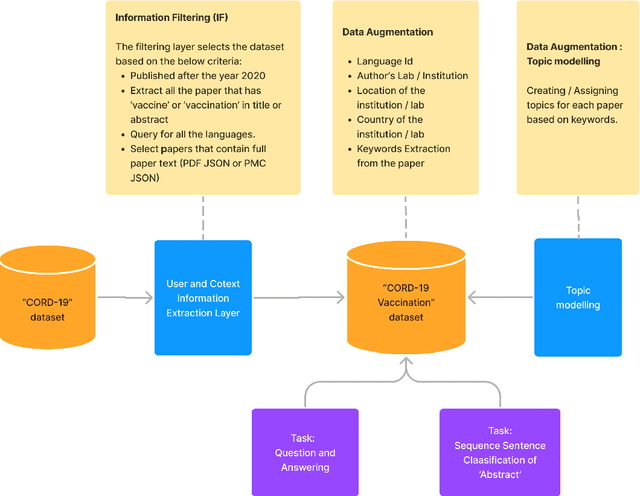



We introduce new dataset 'CORD-19-Vaccination' to cater to scientists specifically looking into COVID-19 vaccine-related research. This dataset is extracted from CORD-19 dataset [Wang et al., 2020] and augmented with new columns for language detail, author demography, keywords, and topic per paper. Facebook's fastText model is used to identify languages [Joulin et al., 2016]. To establish author demography (author affiliation, lab/institution location, and lab/institution country columns) we processed the JSON file for each paper and then further enhanced using Google's search API to determine country values. 'Yake' was used to extract keywords from the title, abstract, and body of each paper and the LDA (Latent Dirichlet Allocation) algorithm was used to add topic information [Campos et al., 2020, 2018a,b]. To evaluate the dataset, we demonstrate a question-answering task like the one used in the CORD-19 Kaggle challenge [Goldbloom et al., 2022]. For further evaluation, sequential sentence classification was performed on each paper's abstract using the model from Dernoncourt et al. [2016]. We partially hand annotated the training dataset and used a pre-trained BERT-PubMed layer. 'CORD- 19-Vaccination' contains 30k research papers and can be immensely valuable for NLP research such as text mining, information extraction, and question answering, specific to the domain of COVID-19 vaccine research.