 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePerformance Trade-offs of Watermarking Large Language Models
Nov 16, 2023Amidst growing concerns of large language models (LLMs) being misused for generating misinformation or completing homework assignments, watermarking has emerged as an effective solution for distinguishing human-written and LLM-generated text. A prominent watermarking strategy is to embed a signal into generated text by upsampling a (pseudorandomly-chosen) subset of tokens at every generation step. Although this signal is imperceptible to a human reader, it is detectable through statistical testing. However, implanting such signals alters the model's output distribution and can have unintended effects when watermarked LLMs are used for downstream applications. In this work, we evaluate the performance of watermarked LLMs on a diverse suite of tasks, including text classification, textual entailment, reasoning, question answering, translation, summarization, and language modeling. We find that watermarking has negligible impact on the performance of tasks posed as k-class classification problems in the average case. However, the accuracy can plummet to that of a random classifier for some scenarios (that occur with non-negligible probability). Tasks that are cast as multiple-choice questions and short-form generation are surprisingly unaffected by watermarking. For long-form generation tasks, including summarization and translation, we see a drop of 15-20% in the performance due to watermarking. Our findings highlight the trade-offs that users should be cognizant of when using watermarked models, and point to cases where future research could improve existing trade-offs.
Detecting Pretraining Data from Large Language Models
Nov 03, 2023Although large language models (LLMs) are widely deployed, the data used to train them is rarely disclosed. Given the incredible scale of this data, up to trillions of tokens, it is all but certain that it includes potentially problematic text such as copyrighted materials, personally identifiable information, and test data for widely reported reference benchmarks. However, we currently have no way to know which data of these types is included or in what proportions. In this paper, we study the pretraining data detection problem: given a piece of text and black-box access to an LLM without knowing the pretraining data, can we determine if the model was trained on the provided text? To facilitate this study, we introduce a dynamic benchmark WIKIMIA that uses data created before and after model training to support gold truth detection. We also introduce a new detection method Min-K% Prob based on a simple hypothesis: an unseen example is likely to contain a few outlier words with low probabilities under the LLM, while a seen example is less likely to have words with such low probabilities. Min-K% Prob can be applied without any knowledge about the pretraining corpus or any additional training, departing from previous detection methods that require training a reference model on data that is similar to the pretraining data. Moreover, our experiments demonstrate that Min-K% Prob achieves a 7.4% improvement on WIKIMIA over these previous methods. We apply Min-K% Prob to three real-world scenarios, copyrighted book detection, contaminated downstream example detection and privacy auditing of machine unlearning, and find it a consistently effective solution.
InstructEval: Systematic Evaluation of Instruction Selection Methods
Jul 16, 2023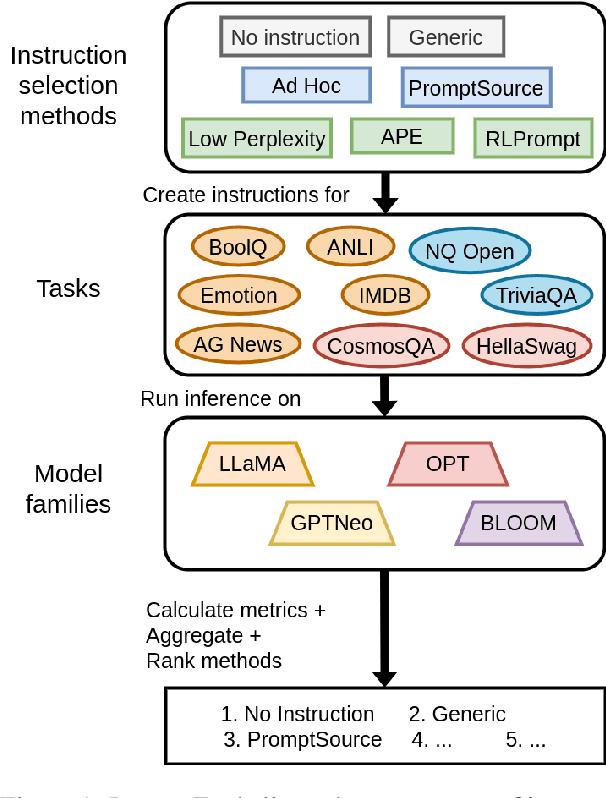
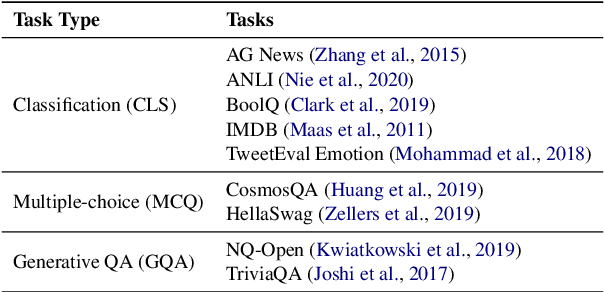

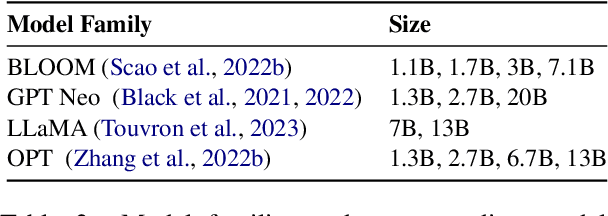
In-context learning (ICL) performs tasks by prompting a large language model (LLM) using an instruction and a small set of annotated examples called demonstrations. Recent work has shown that precise details of the inputs used in the ICL prompt significantly impact performance, which has incentivized instruction selection algorithms. The effect of instruction-choice however is severely underexplored, with existing analyses restricted to shallow subsets of models and tasks, limiting the generalizability of their insights. We develop InstructEval, an ICL evaluation suite to conduct a thorough assessment of these techniques. The suite includes 13 open-sourced LLMs of varying scales from four model families, and covers nine tasks across three categories. Using the suite, we evaluate the relative performance of seven popular instruction selection methods over five metrics relevant to ICL. Our experiments reveal that using curated manually-written instructions or simple instructions without any task-specific descriptions often elicits superior ICL performance overall than that of automatic instruction-induction methods, pointing to a lack of generalizability among the latter. We release our evaluation suite for benchmarking instruction selection approaches and enabling more generalizable methods in this space.
Adapting Language Models to Compress Contexts
May 24, 2023Transformer-based language models (LMs) are powerful and widely-applicable tools, but their usefulness is constrained by a finite context window and the expensive computational cost of processing long text documents. We propose to adapt pre-trained LMs into AutoCompressors. These models are capable of compressing long contexts into compact summary vectors, which are then accessible to the model as soft prompts. Summary vectors are trained with an unsupervised objective, whereby long documents are processed in segments and summary vectors from all previous segments are used in language modeling. We fine-tune OPT models on sequences of up to 30,720 tokens and show that AutoCompressors can utilize long contexts to improve perplexity. We evaluate AutoCompressors on in-context learning by compressing task demonstrations. We find that summary vectors are good substitutes for plain-text demonstrations, increasing accuracy while reducing inference cost. Finally, we explore the benefits of pre-computing summary vectors for large corpora by applying summary vectors to retrieval-augmented language modeling. Overall, AutoCompressors emerge as a simple and inexpensive solution for extending the context window of LMs while speeding up inference over long contexts.