 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInstructEval: Systematic Evaluation of Instruction Selection Methods
Jul 16, 2023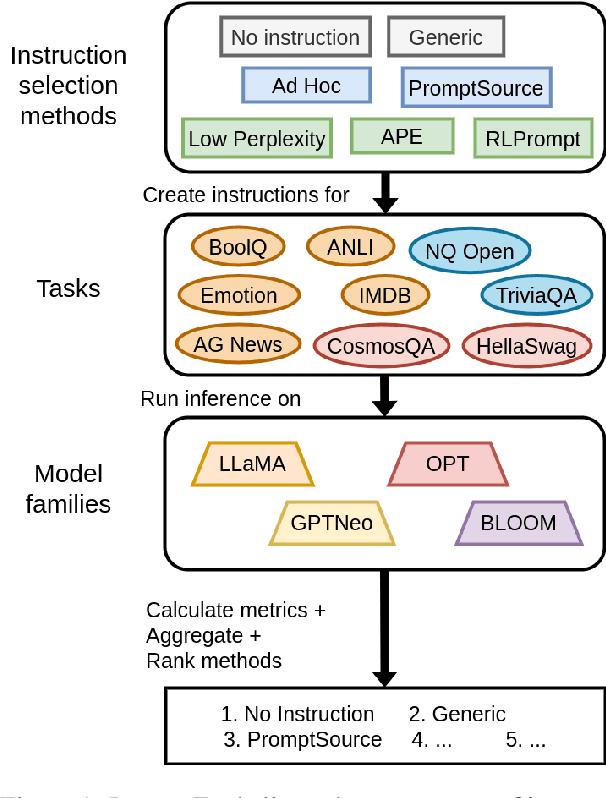
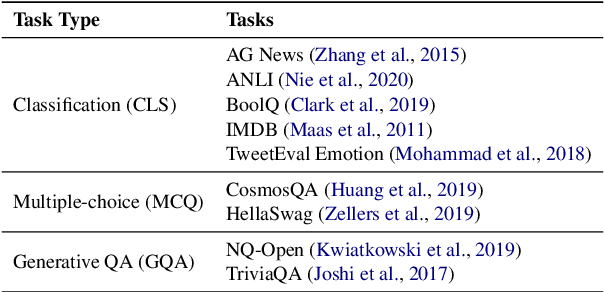

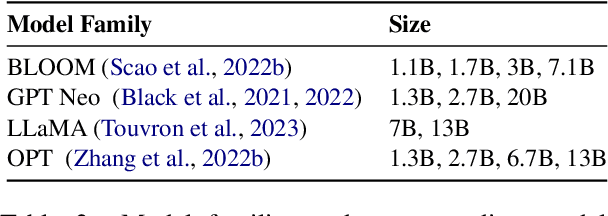
In-context learning (ICL) performs tasks by prompting a large language model (LLM) using an instruction and a small set of annotated examples called demonstrations. Recent work has shown that precise details of the inputs used in the ICL prompt significantly impact performance, which has incentivized instruction selection algorithms. The effect of instruction-choice however is severely underexplored, with existing analyses restricted to shallow subsets of models and tasks, limiting the generalizability of their insights. We develop InstructEval, an ICL evaluation suite to conduct a thorough assessment of these techniques. The suite includes 13 open-sourced LLMs of varying scales from four model families, and covers nine tasks across three categories. Using the suite, we evaluate the relative performance of seven popular instruction selection methods over five metrics relevant to ICL. Our experiments reveal that using curated manually-written instructions or simple instructions without any task-specific descriptions often elicits superior ICL performance overall than that of automatic instruction-induction methods, pointing to a lack of generalizability among the latter. We release our evaluation suite for benchmarking instruction selection approaches and enabling more generalizable methods in this space.