 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUniversal NER v2: Towards a Massively Multilingual Named Entity Recognition Benchmark
Apr 14, 2026While multilingual language models promise to bring the benefits of LLMs to speakers of many languages, gold-standard evaluation benchmarks in most languages to interrogate these assumptions remain scarce. The Universal NER project, now entering its fourth year, is dedicated to building gold-standard multilingual Named Entity Recognition (NER) benchmark datasets. Inspired by existing massively multilingual efforts for other core NLP tasks (e.g., Universal Dependencies), the project uses a general tagset and thorough annotation guidelines to collect standardized, cross-lingual annotations of named entity spans. The first installment (UNER v1) was released in 2024, and the project has continued and expanded since then, with various organizers, annotators, and collaborators in an active community.
From Tarzan to Tolkien: Controlling the Language Proficiency Level of LLMs for Content Generation
Jun 05, 2024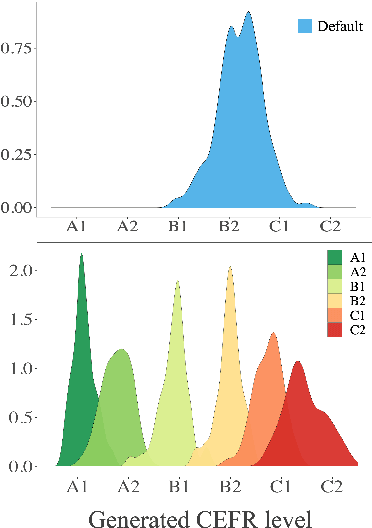
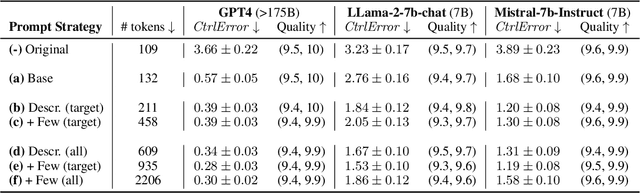
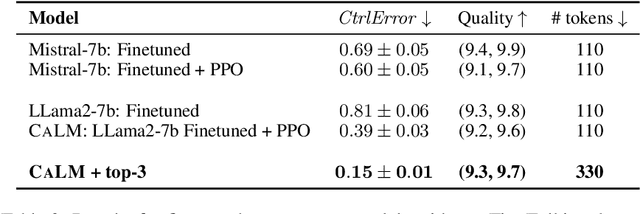
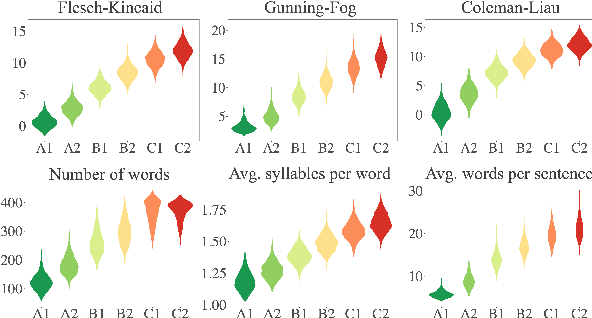
We study the problem of controlling the difficulty level of text generated by Large Language Models (LLMs) for contexts where end-users are not fully proficient, such as language learners. Using a novel framework, we evaluate the effectiveness of several key approaches for this task, including few-shot prompting, supervised finetuning, and reinforcement learning (RL), utilising both GPT-4 and open source alternatives like LLama2-7B and Mistral-7B. Our findings reveal a large performance gap between GPT-4 and the open source models when using prompt-based strategies. However, we show how to bridge this gap with a careful combination of finetuning and RL alignment. Our best model, CALM (CEFR-Aligned Language Model), surpasses the performance of GPT-4 and other strategies, at only a fraction of the cost. We further validate the quality of our results through a small-scale human study.
Universal NER: A Gold-Standard Multilingual Named Entity Recognition Benchmark
Nov 15, 2023
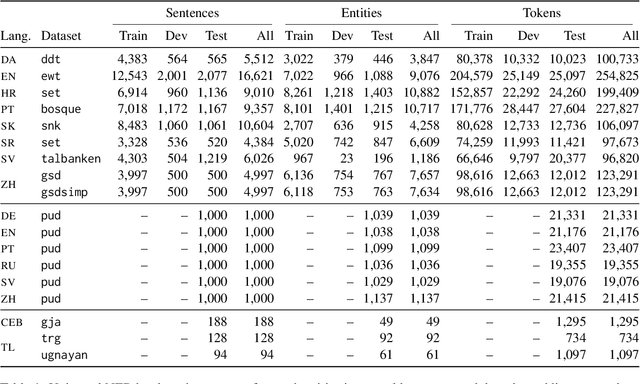


We introduce Universal NER (UNER), an open, community-driven project to develop gold-standard NER benchmarks in many languages. The overarching goal of UNER is to provide high-quality, cross-lingually consistent annotations to facilitate and standardize multilingual NER research. UNER v1 contains 18 datasets annotated with named entities in a cross-lingual consistent schema across 12 diverse languages. In this paper, we detail the dataset creation and composition of UNER; we also provide initial modeling baselines on both in-language and cross-lingual learning settings. We release the data, code, and fitted models to the public.
MasakhaNER: Named Entity Recognition for African Languages
Mar 22, 2021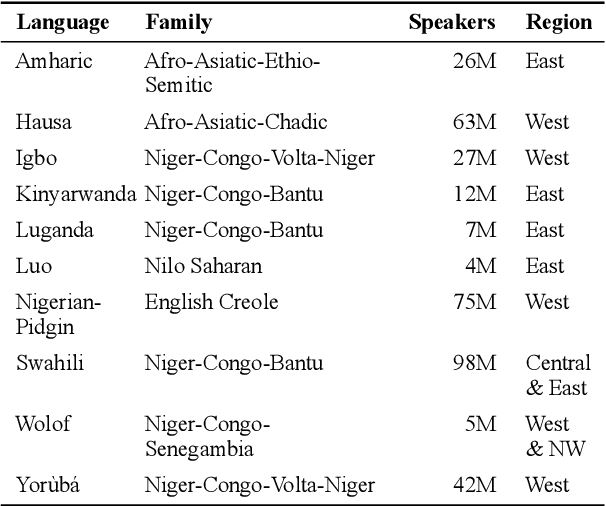

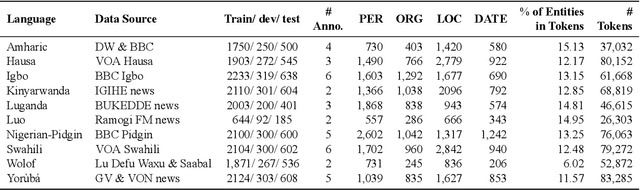
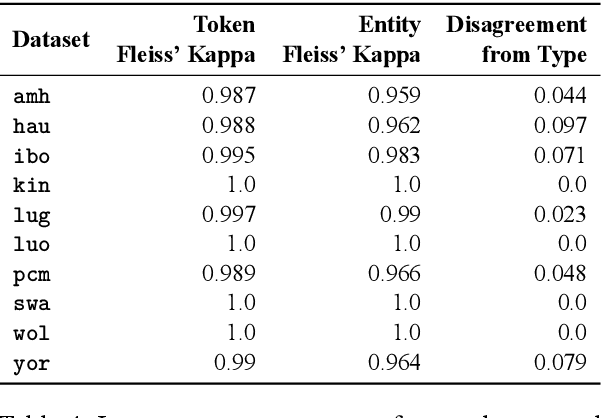
We take a step towards addressing the under-representation of the African continent in NLP research by creating the first large publicly available high-quality dataset for named entity recognition (NER) in ten African languages, bringing together a variety of stakeholders. We detail characteristics of the languages to help researchers understand the challenges that these languages pose for NER. We analyze our datasets and conduct an extensive empirical evaluation of state-of-the-art methods across both supervised and transfer learning settings. We release the data, code, and models in order to inspire future research on African NLP.
Building Low-Resource NER Models Using Non-Speaker Annotation
Jun 17, 2020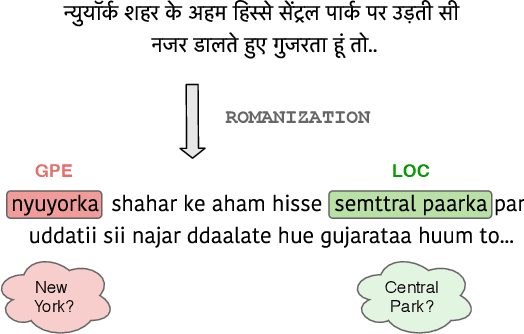
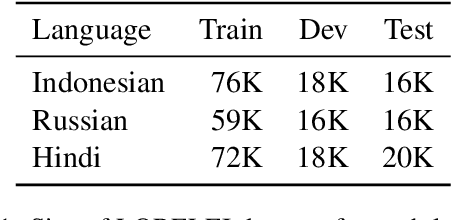
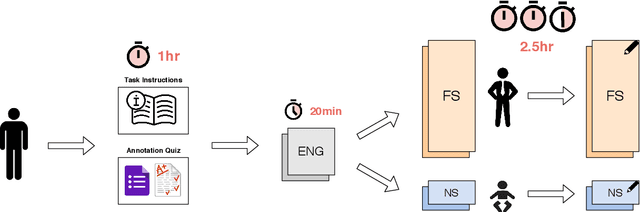
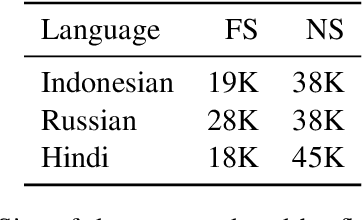
In low-resource natural language processing (NLP), the key problem is a lack of training data in the target language. Cross-lingual methods have had notable success in addressing this concern, but in certain common circumstances, such as insufficient pre-training corpora or languages far from the source language, their performance suffers. In this work we propose an alternative approach to building low-resource Named Entity Recognition (NER) models using "non-speaker" (NS) annotations, provided by annotators with no prior experience in the target language. We recruit 30 participants to annotate unfamiliar languages in a carefully controlled annotation experiment, using Indonesian, Russian, and Hindi as target languages. Our results show that use of non-speaker annotators produces results that approach or match performance of fluent speakers. NS results are also consistently on par or better than cross-lingual methods built on modern contextual representations, and have the potential to further outperform with additional effort. We conclude with observations of common annotation practices and recommendations for maximizing non-speaker annotator performance.
Extending Multilingual BERT to Low-Resource Languages
Apr 28, 2020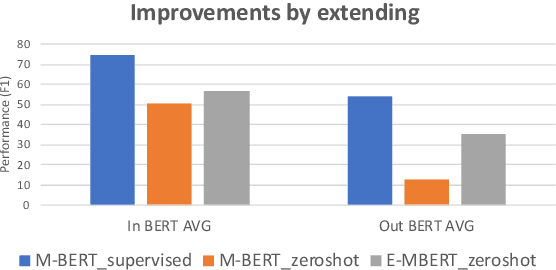
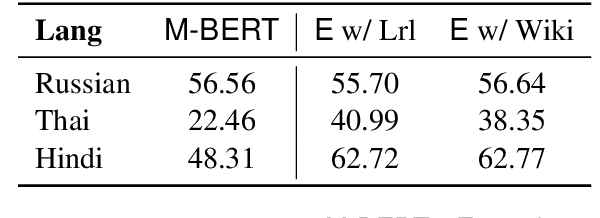
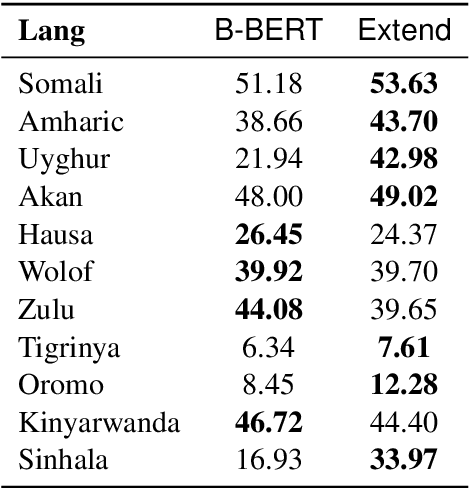
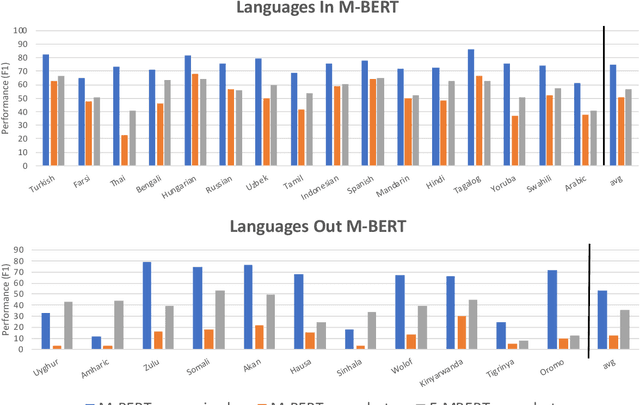
Multilingual BERT (M-BERT) has been a huge success in both supervised and zero-shot cross-lingual transfer learning. However, this success has focused only on the top 104 languages in Wikipedia that it was trained on. In this paper, we propose a simple but effective approach to extend M-BERT (E-BERT) so that it can benefit any new language, and show that our approach benefits languages that are already in M-BERT as well. We perform an extensive set of experiments with Named Entity Recognition (NER) on 27 languages, only 16 of which are in M-BERT, and show an average increase of about 6% F1 on languages that are already in M-BERT and 23% F1 increase on new languages.
Cross-Lingual Ability of Multilingual BERT: An Empirical Study
Dec 17, 2019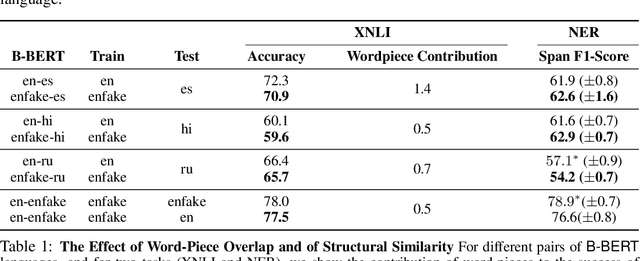

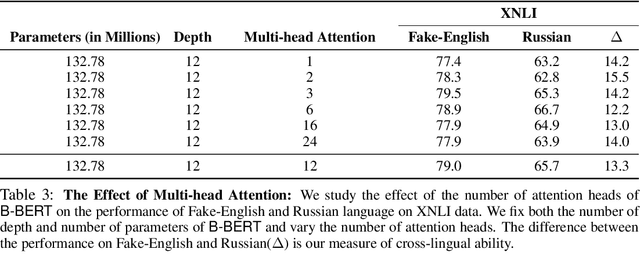
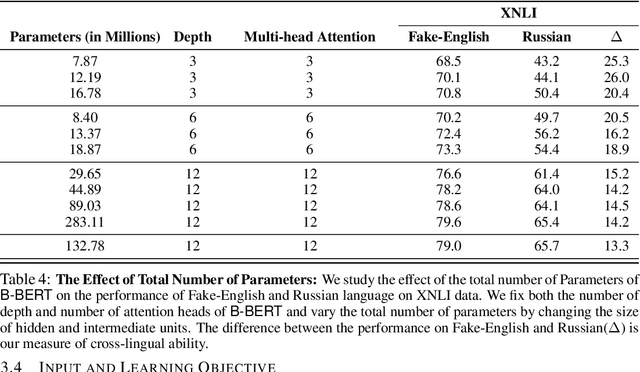
Recent work has exhibited the surprising cross-lingual abilities of multilingual BERT (M-BERT) -- surprising since it is trained without any cross-lingual objective and with no aligned data. In this work, we provide a comprehensive study of the contribution of different components in M-BERT to its cross-lingual ability. We study the impact of linguistic properties of the languages, the architecture of the model, and the learning objectives. The experimental study is done in the context of three typologically different languages -- Spanish, Hindi, and Russian -- and using two conceptually different NLP tasks, textual entailment and named entity recognition. Among our key conclusions is the fact that the lexical overlap between languages plays a negligible role in the cross-lingual success, while the depth of the network is an integral part of it.
Robust Named Entity Recognition with Truecasing Pretraining
Dec 15, 2019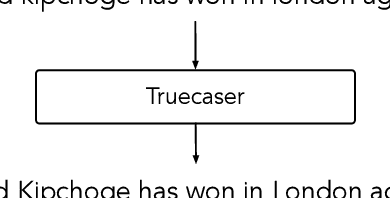
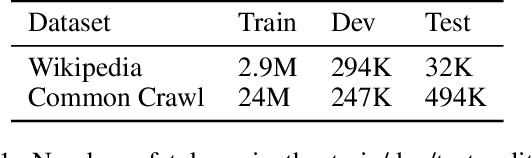
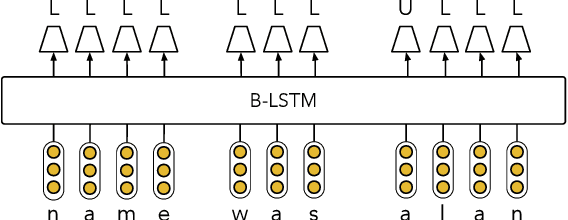

Although modern named entity recognition (NER) systems show impressive performance on standard datasets, they perform poorly when presented with noisy data. In particular, capitalization is a strong signal for entities in many languages, and even state of the art models overfit to this feature, with drastically lower performance on uncapitalized text. In this work, we address the problem of robustness of NER systems in data with noisy or uncertain casing, using a pretraining objective that predicts casing in text, or a truecaser, leveraging unlabeled data. The pretrained truecaser is combined with a standard BiLSTM-CRF model for NER by appending output distributions to character embeddings. In experiments over several datasets of varying domain and casing quality, we show that our new model improves performance in uncased text, even adding value to uncased BERT embeddings. Our method achieves a new state of the art on the WNUT17 shared task dataset.
Named Entity Recognition with Partially Annotated Training Data
Sep 20, 2019
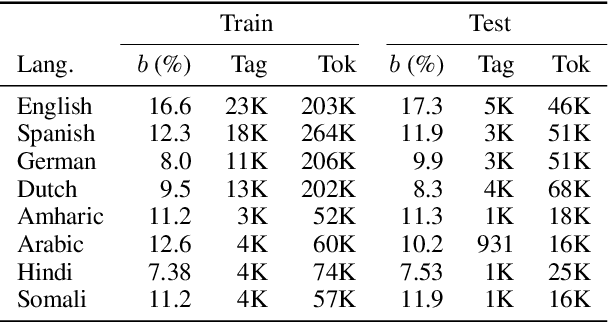

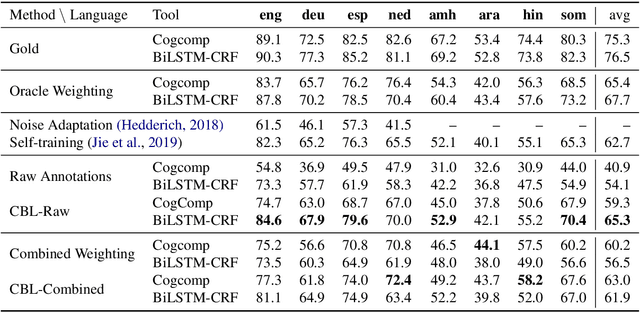
Supervised machine learning assumes the availability of fully-labeled data, but in many cases, such as low-resource languages, the only data available is partially annotated. We study the problem of Named Entity Recognition (NER) with partially annotated training data in which a fraction of the named entities are labeled, and all other tokens, entities or otherwise, are labeled as non-entity by default. In order to train on this noisy dataset, we need to distinguish between the true and false negatives. To this end, we introduce a constraint-driven iterative algorithm that learns to detect false negatives in the noisy set and downweigh them, resulting in a weighted training set. With this set, we train a weighted NER model. We evaluate our algorithm with weighted variants of neural and non-neural NER models on data in 8 languages from several language and script families, showing strong ability to learn from partial data. Finally, to show real-world efficacy, we evaluate on a Bengali NER corpus annotated by non-speakers, outperforming the prior state-of-the-art by over 5 points F1.
ner and pos when nothing is capitalized
Mar 27, 2019
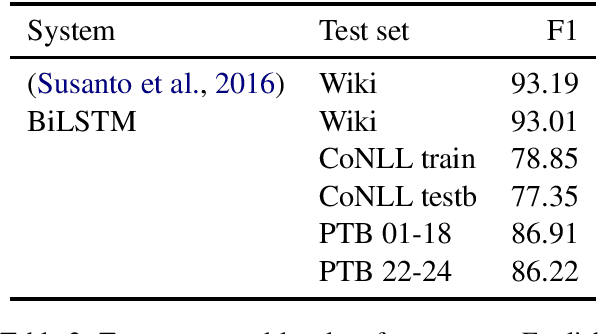
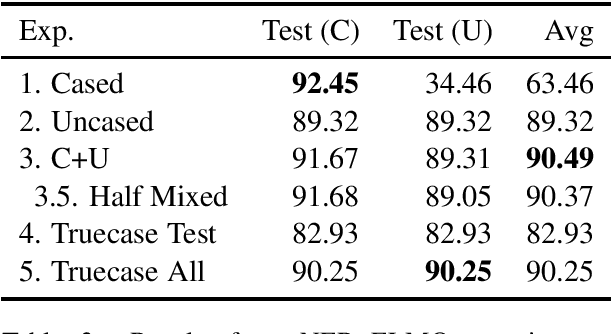
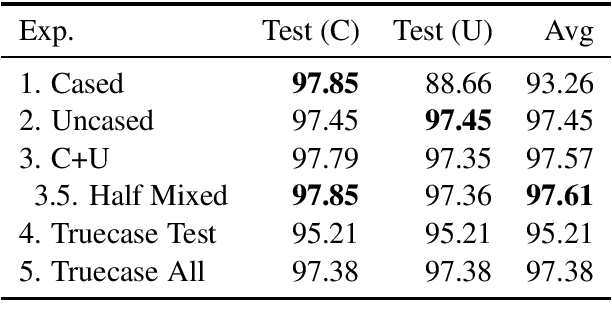
For those languages which use it, capitalization is an important signal for the fundamental NLP tasks of Named Entity Recognition (NER) and Part of Speech (POS) tagging. In fact, it is such a strong signal that model performance on these tasks drops sharply in common lowercased scenarios, such as noisy web text or machine translation outputs. In this work, we perform a systematic analysis of solutions to this problem, modifying only the casing of the train or test data using lowercasing and truecasing methods. While prior work and first impressions might suggest training a caseless model, or using a truecaser at test time, we show that the most effective strategy is a concatenation of cased and lowercased training data, producing a single model with high performance on both cased and uncased text. As shown in our experiments, this result holds across tasks and input representations. Finally, we show that our proposed solution gives an 8% F1 improvement in mention detection on noisy out-of-domain Twitter data.