 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBuilding Low-Resource NER Models Using Non-Speaker Annotation
Jun 17, 2020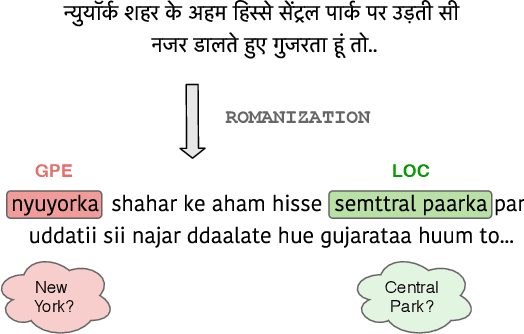
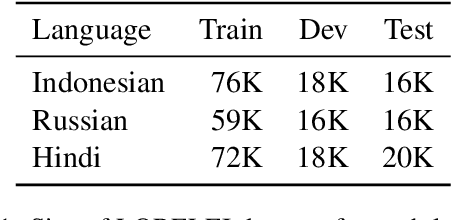
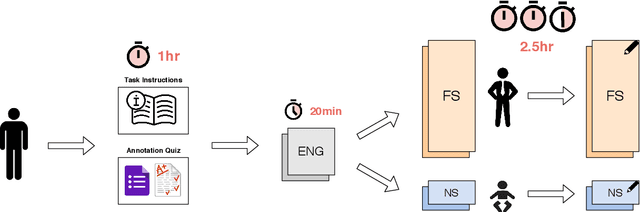
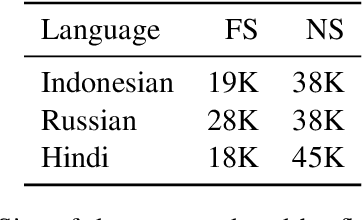
In low-resource natural language processing (NLP), the key problem is a lack of training data in the target language. Cross-lingual methods have had notable success in addressing this concern, but in certain common circumstances, such as insufficient pre-training corpora or languages far from the source language, their performance suffers. In this work we propose an alternative approach to building low-resource Named Entity Recognition (NER) models using "non-speaker" (NS) annotations, provided by annotators with no prior experience in the target language. We recruit 30 participants to annotate unfamiliar languages in a carefully controlled annotation experiment, using Indonesian, Russian, and Hindi as target languages. Our results show that use of non-speaker annotators produces results that approach or match performance of fluent speakers. NS results are also consistently on par or better than cross-lingual methods built on modern contextual representations, and have the potential to further outperform with additional effort. We conclude with observations of common annotation practices and recommendations for maximizing non-speaker annotator performance.
ner and pos when nothing is capitalized
Mar 27, 2019
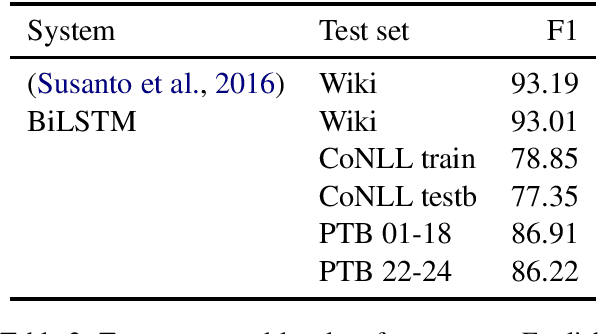
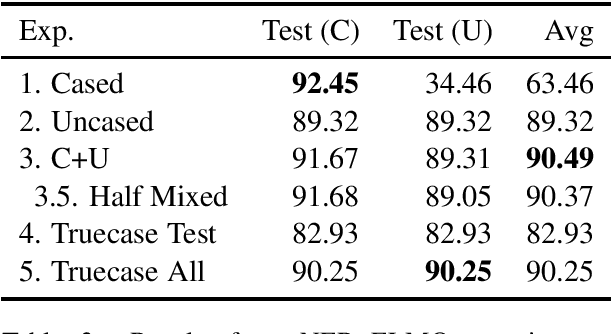
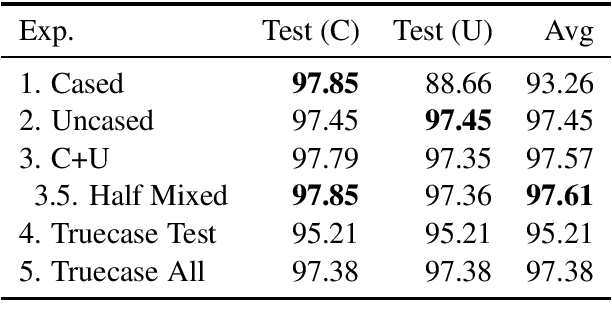
For those languages which use it, capitalization is an important signal for the fundamental NLP tasks of Named Entity Recognition (NER) and Part of Speech (POS) tagging. In fact, it is such a strong signal that model performance on these tasks drops sharply in common lowercased scenarios, such as noisy web text or machine translation outputs. In this work, we perform a systematic analysis of solutions to this problem, modifying only the casing of the train or test data using lowercasing and truecasing methods. While prior work and first impressions might suggest training a caseless model, or using a truecaser at test time, we show that the most effective strategy is a concatenation of cased and lowercased training data, producing a single model with high performance on both cased and uncased text. As shown in our experiments, this result holds across tasks and input representations. Finally, we show that our proposed solution gives an 8% F1 improvement in mention detection on noisy out-of-domain Twitter data.